Python语言程序设计(MOOC崇天)第六章组合数据类型学习笔记(基本统计值计算+文本词频统计)
复习:






今日内容:组合数据类型



集合类型及操作:

集合类型的定义:

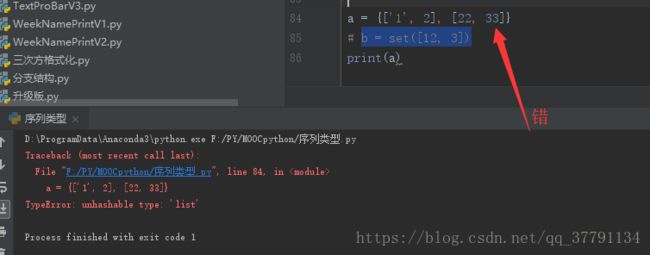
非可变的数据类型:整数、浮点、元组、负数、字符串类型
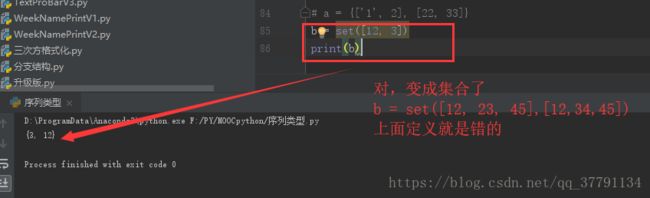
可变的数据类型:列表list和字典dict。所以看不到集合中有列表、{[ ]}
就算是set([12,33]),输出看到的也是{12,33}


重点:


这里是指会把原集合数据改变。而非增强操作符则会生成新的集合且赋值给新集合变量

A = {'p', 'y', 123}
print(A)
B = set("pypy123")
print(B)
print(A-B)
print(B-A)
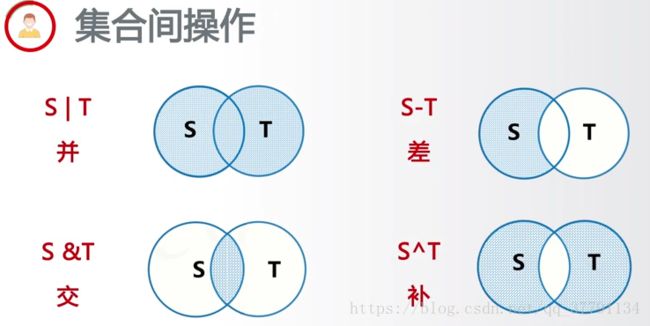
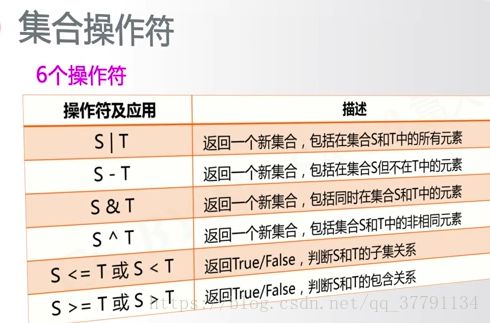
print(A&B)#交
print(A^B) #补(把大家都没有的打印出来)
print(A|B) #并 
集合的处理方法:(10个记下来!!!)



集合类型应用场景:
数据去重、包含关系比较


我的做法:
ls = ["p", "p", "y", "y", 123]
l =[]
for i in range(len(ls)):
if ls[i] not in ls[i+1:-1]:
l.append(ls[i])
print(l)

这个说超过了range但是明显没有呀..怎么破?应该ls在变化,所以不能这样,可能取不到某个值
总结:

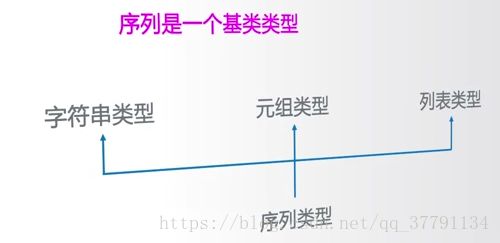
序列类型及操作


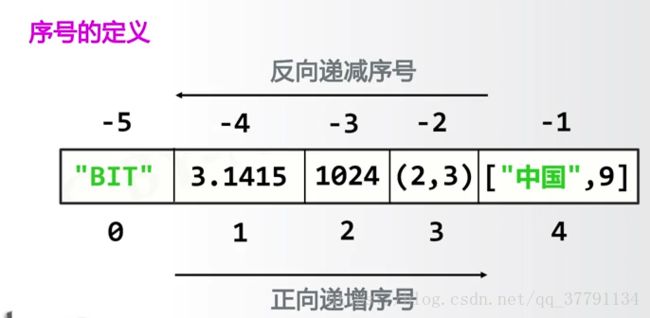


ls = ["python", ".io", 123]
print(ls[::-1])
s = "python123.io"
print(s[::-1])
序列类型通用方法和函数(5个函数)
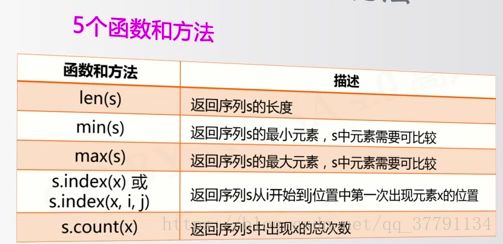
ls = ["python", ".io", 123]
print(ls[::-1])
s = "python123.io"
print(s[::-1])
print(len(ls))
print(max(s))
print(s.count("o"))
print(s.index("o"))
元组类型




所以上面的图片可以告诉我们,元组一旦创建是不能被修改的,尽管creature[::-1]操作后,creature还是没有变化,依旧是可以通过color[-1][2]找到tiger、
列表类型及操作:


使用内存和指针......没有使用[]相当于没有申请内存,只是重命名了而已。ls和lt都指向同一段内存空间
列表类型操作函数和方法:

ls = ["cat", "dog", "tiger", 1024]
ls[1:2] = [1, 2, 3, 4]
print(ls)
print(ls[1:2])
del ls[::3] #删除以步长为3的数
print(ls)
print(ls*2)

修改列表就是增删减除


但是列表就可以用ls.pop("2")
#列表类型操作
ls = ["cat", "dog", "tiger", 1024]
print(ls)
ls.append(1234)
print(ls)
ls.insert(3, "human")
print(ls)
ls.reverse()
print(ls)
做个小测试,看你能完成几个?



#列表类型操作
#
lt = []
for i in range(5):
lt.append(eval(input()))
print(lt)
lt[2] = 5
print(lt)
lt.insert(2, 3)
print(lt)
del lt[0]
print(lt)
del lt[1:4]
print(lt)
if 0 in lt:
print("是的,0在lt列表中")
lt.append(0) #千万别是"0" 后面没有办法去计算sum
print(lt)
lt.index(0)
print(lt.index(0))
len(lt)
print(lt)
#注意哈 lt.max()
print(max(lt))
lt.clear()
print(lt)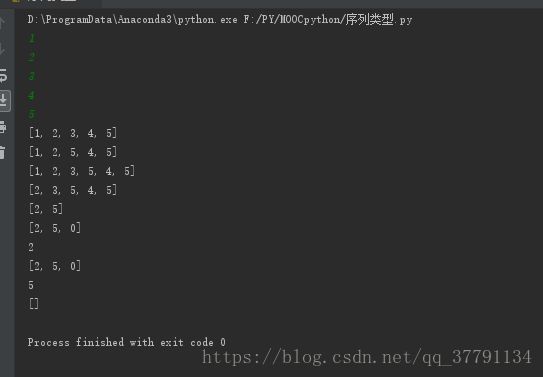 、
、
序列类型的应用场景



当程序不是一个人写的,可以用元组作接口进行传递。
例子:基本统计值计算


def getNum():
nums =[]
iNumStr = input("请输入数字(回车退出):")
while iNumStr !="":
nums.append(eval(iNumStr))
iNumStr = input("请输入数字(回车退出):")
return nums
def mean(numbers):
s = 0.0
for num in numbers:
s = s + num
return s/len(numbers)
def dev(numbers, mean):
sdev = 0.0
for num in numbers:
sdev = sdev+(num - mean)**2
return sdev / len(numbers), pow(sdev / len(numbers), 0.5)
def median(numbers):
sorted(numbers)
size = len(numbers)
if size % 2 == 0:
med = (numbers[size//2 - 1]+numbers[size//2])/2
else:
med = numbers[size//2]
return med
n = getNum()
m = mean(n)
f, j = dev(n, m)
print("数组个数:{},平均值:{},方差:{:.2f},均方差:{:.2f},中位数:{}".format(len(n), m, f, j, median(n)))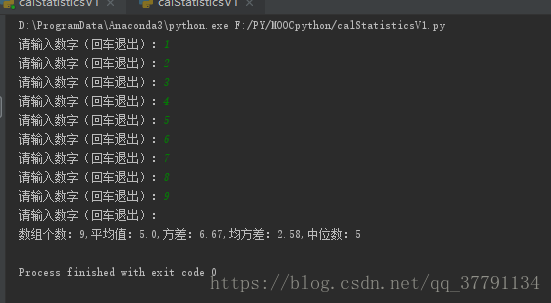
题目需要掌握:
1.如何获取多个数据
2、将功能模块化 函数化

python内置函数几十个,需要记熟,才能好好的用python。
字典类型以及操作






字典类型操作函数和方法


d.keys 和d.values 返回的类型可用 for in来遍历 但是不能当做事列表来操作


做个测试:

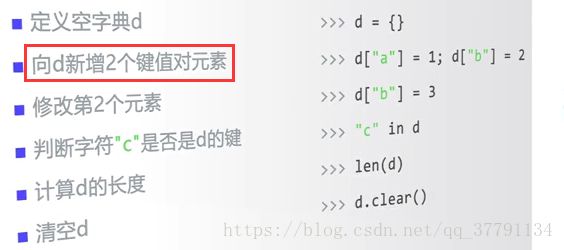
zd = {}
zd = {"中国": "北京", "city": "beijing"}
zd['city'] = " Beijing"
if "c" in zd:
print("Ture")
len(zd)
zd.clear()
字典类型的应用场景


总结:

jieba库


提示:需要你联网。


常用的库:!!!


文本词频统计:

实例讲解:
文本噪音处理 归一化
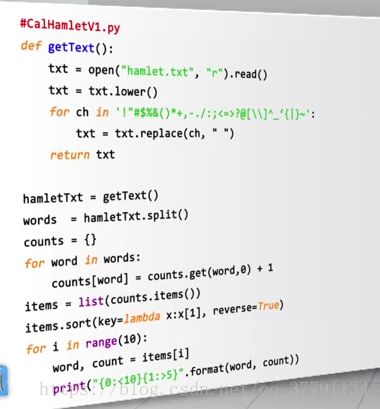
#CalHamletV1.py
def getText():
txt = open("hamlet.txt","r").read()
txt = txt.lower()
for ch in '!"#$%()*+,-./:<=>?@[\\]^_"''{|}~':
txt = txt.replace(ch, "")
return txt
hameletTxt = getText()
words = hameletTxt.split()
counts = {}
for word in words:
counts[word] = counts.get(word, 0)+1
items = list(counts.items())
# print(items.sort(key=lambda x: x[1], reverse=True))
items.sort(key=lambda x: x[1], reverse=True)
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
知识点:
1、type(items.sort(key=lambda x: x[1], reverse=True))输出的是:
所以:print(items.sort(key=lambda x: x[1], reverse=True))不能这么用
但是:
listC = [('e', 4), ('o', 2), ('!', 5), ('v', 3), ('l', 1)]
print(sorted(listC,key=lambda x: x[1], reverse=True))
输出是:[('!', 5), ('e', 4), ('v', 3), ('o', 2), ('l', 1)]2、print("{0:<10}{0:>5}".format(word, count))
输出:
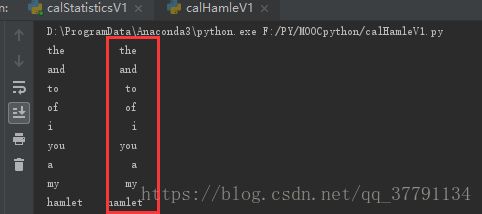
可见这个{1:>5}还不是耐得....

出现UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd0 in position 0: invalid con
看:https://blog.csdn.net/qq_37791134/article/details/83217964
#CalThreeKingdomsV1.py
import jieba
txt = open("threeKingdoms.txt", "r", encoding="utf-8").read()
words = jieba.lcut(txt)
print(words)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1 #键word存在则返回相应值,不存在则返回0
items = list(counts.items())
# 固定用法,在对应列进行排序,从小到大的排序与sorted(listC,key=lambda x: x[1], reverse=True)相反这是从大到小
items.sort(key=lambda x: x[1], reverse=True)
for i in range(15):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
却说、孔明日 =孔明 玄德日 = 玄德
所以哈.....改进:



集合、序列、字典很好的实例。
关于可变数据类型和不可变数据类型,有个博客总结的很好。https://www.cnblogs.com/big-devil/p/7625898.html

之所以称为不可变数据类型,这里的不可变可以理解为x引用的地址处的值是不能被改变的,也就是31106520地址处的值在没被垃圾回收之前一直都是1,不能改变,如果要把x赋值为2,那么只能将x引用的地址从31106520变为31106508,相当于x = 2这个赋值又创建了一个对象,即2这个对象,然后x、y、z都引用了这个对象,所以int这个数据类型是不可变的,如果想对int类型的变量再次赋值,在内存中相当于又创建了一个新的对象,而不再是之前的对象。
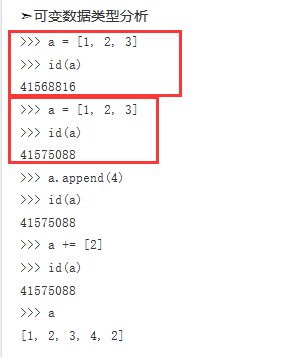
可变数据类型是允许同一对象的内容,即值可以变化,但是地址是不会变化的。但是需要注意一点,对可变数据类型的操作不能是直接进行新的赋值操作,比如说a = [1, 2, 3, 4, 5, 6, 7],这样的操作就不是改变值了,而是新建了一个新的对象,这里的可变只是对于类似于append、+=等这种操作。
总结
用一句话来概括上述过程就是:“python中的不可变数据类型,不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象,内部会有一个引用计数来记录有多少个变量引用这个对象;可变数据类型,允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化,不过对于相同的值的不同对象,在内存中则会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。”