kafka集群扩容以及物理资源(broker)隔离
需求:
要对于几个业务topic进行基于broker级别的物理资源隔离
步骤
1:Ambari2.7.x基于HDP3.x进行kafka集群扩容
用于隔离的broker是若干台新机子
在ambari界面–主机–add—kafka broker
进行kafka的broker扩容
2:登陆zk查看扩容机对应的broker id
sh zkcli.sh
ls /broker/ids
get每一个broker id的值,查询新增的brokers 主机名对应的broker id,一般都是基于之前的broker id进行追加,比如之前一共有10台broker,由1001到1010,然后扩容了4台,则新的broker id为1011到1014,与hostname一一对应(前提是你的hostname都是按顺序的噢)
3:创建新topic时进行物理隔离
在创建topic的时候加上replica-assignment参数,后面的值用逗号分隔每个partition,每个partition中冒号分隔副本所在的broker。例如通过下面的命令创建两个topic。
./kafka-topics.sh --zookeeper hostA:2181 --create --topic user1 --replica-assignment 1008:1001,1007:1002
./kafka-topics.sh --zookeeper hostA:2181 --create --topic user1 --replica-assignment 1010:1003,1009:1004
注意:这里创建topic时不能添加–partitions与–replication-factor参数,因为那是自动分配,这里是通过–replica-assignment进行手动分配(隔离)
查看创建之后的user1 topic 的partition分布,partition0的leader是1008,副本在1008和1001,partition1也是和预期的一致.
user2一样
describe如下
./kafka-topics.sh --describe --zookeeper hostA:2181 --topic user1,user2
Topic:user1 PartitionCount:2 ReplicationFactor:2 Configs:
Topic: user1 Partition: 0 Leader: 1008 Replicas: 1008,1001 Isr: 1008,1001
Topic: user1 Partition: 1 Leader: 1007 Replicas: 1007,1002 Isr: 1007,1002
Topic:user2 PartitionCount:2 ReplicationFactor:2 Configs:
Topic: user2 Partition: 0 Leader: 1010 Replicas: 1010,1003 Isr: 1010,1003
Topic: user2 Partition: 1 Leader: 1009 Replicas: 1009,1004 Isr: 1009,1004
4:分析
3中的结果已经表明了 用replica-assignment新创建的2个topic已经分布在不同的broker中了,副本也在完全不同的机子中,user1主题的所有分区的副本一直在1008,1001,1007,1002中,user2主题的所有分区的副本一直在1010,1003,1009,1009中。user1,user2两个主题互不影响。实现了主题在broker级别的物理隔离
其实究其topic创建方式,无非这个参数就是把原本基于固定分区副本数随机分配broker转变成固定分区副本id名称。
id名称固定了,那么分区数,副本数都不需要指定了。
所以省略了–partitions,–replication-factor参数
5:疑问
难道在后续使用的过程中,user1与user2的副本永远不会重叠而造成隔离污染吗?
6:思考
想了下kafka的重平衡机制
有三个参数如下
auto.leader.rebalance.enable=true ## 是否leader自动重平衡
leader.imbalance.check.interval.seconds=300s ## 不均衡扫描间隔时间
leader.imbalance.per.broker.percentage=10 ## 不均衡比率阈值(不均衡比率=leader不等于preferred replicas的分区数/总分区数)
参数不好理解拿下图举个例子
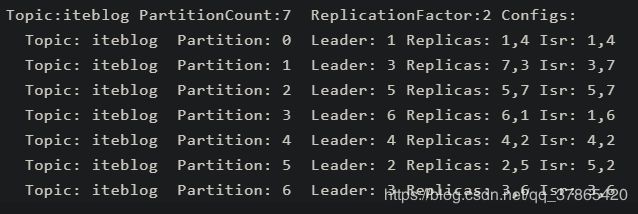
如果满足上图,在
auto.leader.rebalance.enable=true
leader.imbalance.check.interval.seconds=300s
的条件下,进行第三个参数leader.imbalance.per.broker.percentage的判定
iteblog主题的6个分区中只有一个分区的leader不等于replica中的第一个副本id(这里第一个副本就是上文中所说的preferred replica)
比率为1/7,小于10%,所以不会触发leader的重平衡机制
但是如果这个比例大于10%了呢,就会触发重平衡机制,会在所有broker中进行重平衡算法,包括之前新添加的broker(只用于某些topic的物理资源隔离)。
这样子就会导致该topic的分区们将所有的broker宠幸了个遍。破坏了物理隔离
7:优化方式
基于现有业务量,合理将leader.imbalance.per.broker.percentage参数进行增大,15%,20%,像这样,但是也不要太大
8:修正·回滚
发了博客后,我参考官方文档的参数定义,发现6中的三个参数,如果判定生效,他会进行leader的rebalance,但是并不会将隔离前的broker也拉进来一起平衡。而是会在当前topic中将leader不为preferred replica的分区leader改为preferred replica(优先副本),就像刚才那张图

图中1号分区的leader为3,优先副本(preferred replica)却为7。
假设那个平衡比率大于10%了,那么auto.leader.rebalance.enable=true是对leader的负载均衡,不会将扩容前的机子牵扯进来。
leader的rebalance是将leader改为preferred replica。我之前将leader的重平衡跟kafka-reassign-partition脚本搞混了。
kafka-reassign-partition脚本才会对当前topic的所有分区重新分配(如果你自己的执行计划特立独行只修改指定分区当我没说),而auto.leader.rebalance.enable=true只会对某些分区进行操作
上图中编号为3的broker作为分区1、6的leader,压力大,当不均衡比率高于阈值(leader.imbalance.per.broker.percentage)则将分区1的leader更换为7(当然图中的比率是1/7,这里是假设比率高于阈值)。这样子编号3broker就很舒服了
那么得出结论
kafka的–replica-assignment参数所生成的topic的分区副本永远不会改变,除非手动指定执行计划运行kafka-reassign-partition脚本来修改分区的副本id,所以无需修改leader.imbalance.per.broker.percentage阈值