一文详解self-attention机制在语义分割中的应用(含论文解析)
Table of Contents
背景
Self-Attention Mechanism
论文解析
DANet
CCNet
ISSA
关于1×1卷积的作用:1×1 卷积
背景
语义分割经历多年的发展,提出了FCN、U-Net、SegNet、DeepLab等一大批优秀的语义分割网络。但是FCN等结构限制了局部感受野的范围和短距离上下文信息,传统的深度卷积神经网络主要通过叠加多个卷积来模拟长距离依赖关系。为了捕获长距离的依赖关系,Chen等[1]人提出带有多尺度空洞卷积的ASPP模块集成上下文信息;Zhao等[2]人进一步提出带有金字塔池化模块的PSPNet捕获上下文信息。但是基于空洞卷积的方法仍然是从少数的周围点中获取信息而不能形成密集的上下文信息。同时,基于池化的方法以非适应的方式获得上下文信息并且对图像所有像素获得同质的上下文信息,这不能满足不同像素需要不同上下文依赖的需求。
为了获得密集的像素级的上下文信息,PSANet[3]通过预测注意力图中学习汇总每个位置的上下文信息,Non-local[4]网络利用自注意力机制使任何位置的单一特征能够感知所有其他位置的特征,能够产生更强大的像素级的表征能力。
Self-Attention机制能够捕获特征图中任意两个位置的空间依赖关系,获得长距离上下文依赖信息。Ulku等[5]人认为全局上下文信息决定了最终的性能。2020年来自EPFL的ICLR 2020的一篇论文阐述到自注意力机制可以表达任何卷积滤波层[6]。那么什么是self-attention机制呢?
Self-Attention Mechanism
首先介绍Self-Attention机制。Self-Attention是从NLP中借鉴过来的思想,因此仍然保留了Query, Key和Value等名称。下图是self-attention的基本结构,feature maps是由基本的深度卷积网络得到的特征图,如ResNet、Xception等,这些基本的深度卷积网络被称为backbone,通常将最后ResNet的两个下采样层去除使获得的特征图是原输入图像的1/8大小。
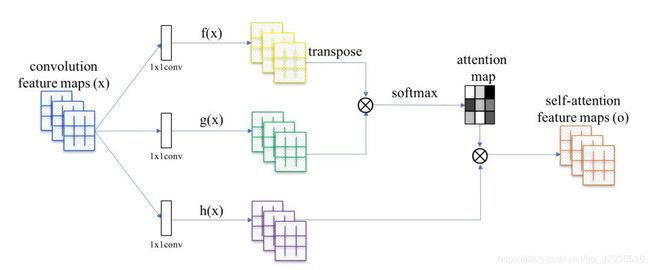
Self-attention结构自上而下分为三个分支,分别是query、key和value。计算时通常分为三步:
- 第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;
- 第二步一般是使用一个softmax函数对这些权重进行归一化;
- 第三步将权重和相应的键值value进行加权求和得到最后的attention。
下面我们通过实例代码讲述self-attention的原理。
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X CX(N)
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
out = self.gamma*out + x
return out,attention
假设feature maps的大小是Batch_size×Channels×Width×Height
在初始化函数中,定义了三个1×1卷积,分别是query_conv , key_conv 和 value_conv。
- 在query_conv卷积中,输入为B×C×W×H,输出为B×C/8×W×H;
- 在key_conv卷积中,输入为B×C×W×H,输出为B×C/8×W×H;
- 在value_conv卷积中,输入为B×C×W×H,输出为B×C×W×H。
在forward函数中,定义了self-attention的具体步骤。
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1)proj_query本质上就是卷积,只不过加入了reshape的操作。首先是对输入的feature map进行query_conv卷积,输出为B×C/8×W×H;view函数是改变了输出的维度,就单张feature map而言,就是将W×H大小拉直,变为1×(W×H)大小;就batchsize大小而言,输出就是B×C/8×(W×H);permute函数则对第二维和第三维进行倒置,输出为B×(W×H)×C/8。proj_query中的第i行表示第i个像素位置上所有通道的值。
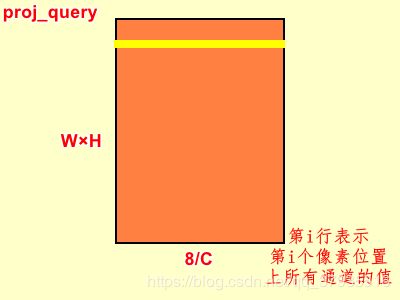
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height)proj_key与proj_query相似,只是没有最后一步倒置,输出为B×C/8×(W×H)。proj_key中的第j行表示第j个像素位置上所有通道的值。

energy = torch.bmm(proj_query,proj_key)这一步是将batch_size中的每一对proj_query和proj_key分别进行矩阵相乘,输出为B×(W×H)×(W×H)。Energy中的第(i,j)是将proj_query中的第i行与proj_key中的第j行点乘得到。这个步骤的意义是energy中第(i,j)位置的元素是指输入特征图第j个元素对第i个元素的影响,从而实现全局上下文任意两个元素的依赖关系。
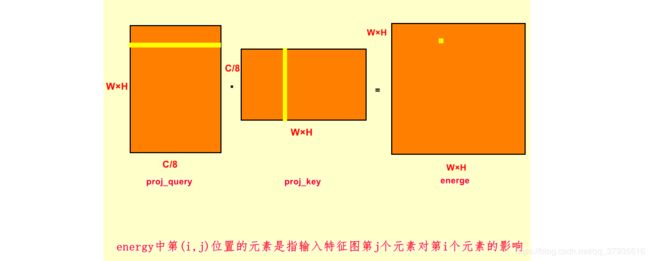
attention = self.softmax(energy)这一步是将energe进行softmax归一化,是对行的归一化。归一化后每行的之和为1,对于(i,j)位置即可理解为第j位置对i位置的权重,所有的j对i位置的权重之和为1,此时得到attention_map。
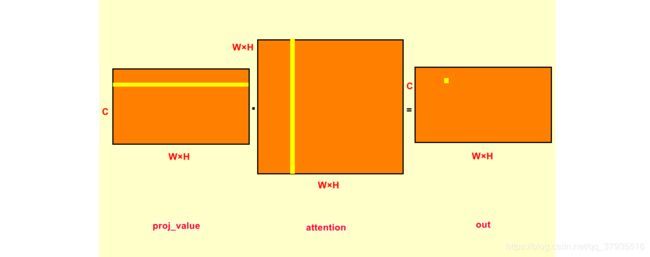
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height)proj_value和proj_query与proj_key一样,只是输入为B×C×W×H,输出为B×C×(W×H)。从self-attention结构图中可以知道proj_value是与attention_map进行矩阵相乘,即下面两行代码。
out = torch.bmm(proj_value,attention.permute(0,2,1) )
out = out.view(m_batchsize,C,width,height)
在对proj_value与attention_map点乘之前,先对attention进行转置。这是由于attention中每一行的权重之和为1,是原特征图第j个位置对第i个位置的权重,将其转置之后,每一列之和为1;proj_value的每一行与attention中的每一列点乘,将权重施加于proj_value上,输出为B×C×(W×H)。
out = self.gamma*out + x这一步是对attention之后的out进行加权,x是原始的特征图,将其叠加在原始特征图上。Gamma是经过学习得到的,初始gamma为0,输出即原始特征图,随着学习的深入,在原始特征图上增加了加权的attention,得到特征图中任意两个位置的全局依赖关系。
以上是self-attention的原理,下面针对一些论文的具体网络进行分析。
论文解析
DANet
DANet[7]是一种经典的应用self-Attention的网络,它引入了一种自注意力机制来分别捕获空间维度和通道维度中的特征依赖关系。

从其结构图中可以看到,它由两个并列的attention module组成,第一个就是前文所述的原理,得到的是特征图中任意两个位置的依赖关系,称为Position Attention Module(PAM);第二个是任意两个通道间的依赖关系,称为Channel Attention Module(CAM)。
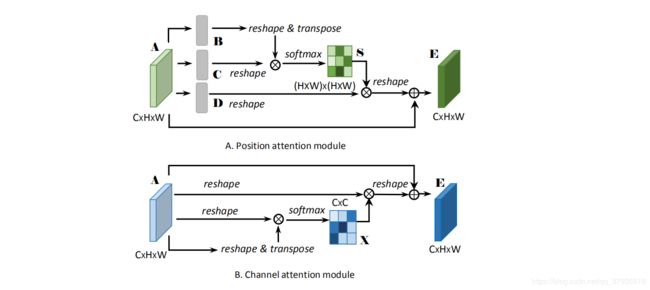
从其具体的模块中来看,PAM中的attention_map的大小为B×(W×H)×(W×H),而CAM中的attention_map大小为B×C×C,这就是PAM与CAM的区别,他们所代表的一个是任意两个位置之间的依赖关系,一个代表的是任意两个通道之间的依赖关系。
其具体代码地址:https://github.com/junfu1115/DANet/blob/master/encoding/nn/attention.py
CCNet
CCNet[8]是针对self-attention占用GPU内存大和计算量大提出来的,它能减少11倍的内存占用和85% FLOPs的同时获得长距离依赖关系。从下面示意图中可以看出来,若要计算输入feature map中蓝色点与其他像素点之间的依赖关系,(a)是一般的Non-local模块,其得到的权重是W×H个;(b)是论文提出中Criss-Cross Attention模块,它只关注每个像素点所在行所在列的权重,得到的权重是H+W-1个,循环两次(为什么要循环两次后文解释)后便能达到与self-attention一样的效果,还能节省大量的计算与内存。

在其具体的criss-cross attention module中,与self-attention不同的是通过Query和Key获得的attention_map中权重的个数是H+W-1,只获得了水平和垂直方向的上下文信息,而这些信息不足以进行语义分割。
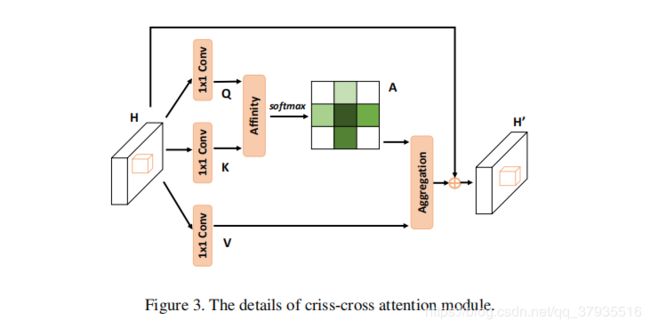
那么如何获得全局上下文信息呢?论文中认为criss-cross attention module循环两次即可获得任意两个像素点的依赖关系,即全局特征。

比如我们要获得下图右上角蓝色点与左下角绿色两个像素点的依赖关系,在Loop1中,右上角(ox,oy)蓝色点将信息传递到(ux,oy)和(ox,uy),还不能传播到左下角点(ux,uy),在Loop2中,左下角点(ux,uy)能够从左上角点(ux,oy)和右下角点(ox,uy)中得到信息,这时已经包含了蓝色点的信息,所以右上角点信息传播到左下角点。同理,任何不能一次遍历的位于十字位置的点只需两次就能完全遍历。这就是为什么论文中循环使用两次criss-cross attention module的原因,此结构称之为Recurrent Criss-Cross Attention module(RCCA)。
ISSA
ISSA[9]同样是针对self-attention需要大量计算与内存而提出来的一种模型,是将interlace机制与self-attention机制结合从而获得任意两个位置的依赖关系的,其主要思想是将密集相似矩阵分解为两个稀疏相似矩阵的乘积。
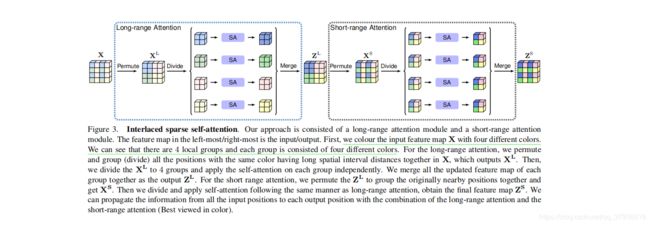
我们将所有的输入位置分为Q个大小相等的子集(上图中Q=4),每个子集中包含P个位置(N=P*Q,上图中P=4)。对于长距离注意模块,我们从每一个子集中采样一个位置构建一个含有Q个位置的新子集(因为原先划分为Q个子集,每个子集拿出一个位置,就有了Q个位置),根据这样采样策略能够获得P个这样的子集。这样每个构造子集中的位置是长空间间隔距离的位置。在每个子集上采用自注意力机制计算稀疏相似性矩阵AL。对于短距离注意模块,直接在原始的Q个子集上(相当于在long-range模块permute之后再permute回来)利用self-attention计算稀疏相似性矩阵AS。融合这两个机制,便可以将信息从每个输入位置传播到所有输出位置。

上图是ISSA的伪代码,原理相对简单,是对self-attention的一种改进,节省了大量的计算与内存占用情况。
以上就是对self-attention机制的一些解释,当然还有一些其他优秀论文,语义分割也有其他方向的发展,等阅读到了一些优秀论文再更新。
参考文献:
[1] Chen L C, Papandreou G, Kokkinos I, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 40(4): 834-848.
[2] Zhao H, Shi J, Qi X, et al. Pyramid scene parsing network[C].Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2881-2890.
[3] Zhao H, Zhang Y, Liu S, et al. Psanet: Point-wise spatial attention network for scene parsing[C].Proceedings of the European Conference on Computer Vision (ECCV). 2018: 267-283.
[4] Wang X, Girshick R, Gupta A, et al. Non-local neural networks[C].Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7794-7803.
[5] Ulku I, Akagunduz E. A Survey on Deep Learning-based Architectures for Semantic Segmentation on 2D images[J]. arXiv preprint arXiv:1912.10230, 2019.
[6] Cordonnier J B, Loukas A, Jaggi M. On the Relationship between Self-Attention and Convolutional Layers[J]. arXiv preprint arXiv:1911.03584, 2019.
[7] Fu J, Liu J, Tian H, et al. Dual attention network for scene segmentation[C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 3146-3154.
[8] Huang Z, Wang X, Huang L, et al. Ccnet: Criss-cross attention for semantic segmentation[C]//Proceedings of the IEEE International Conference on Computer Vision. 2019: 603-612.
[9] Huang L, Yuan Y, Guo J, et al. Interlaced sparse self-attention for semantic segmentation[J]. arXiv preprint arXiv:1907.12273, 2019.
参考博客:
Self-Attention GAN 中的 self-attention 机制
关于attention机制在nlp中的应用总结