Spark Streaming 整合Flume 和Kafka
前言
首先会使用Java开发一个日志产生器,使用Flume收集此信息到Kafka,然后Spark Streaming 从Kafka读取消息。
完整项目代码:
https://github.com/GYT0313/Spark-Learning/tree/master/sparkstream
1. 日志产生器
首先你应该创建一个Maven 项目,参考:https://blog.csdn.net/qq_38038143/article/details/89926205
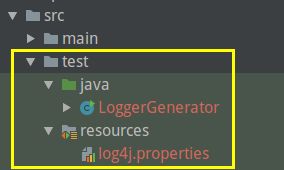
在test 目录下创建java 项目,并创建LoggerGenerator 类,以及resources目录和log4j.properties:
在 Project structure中设置:
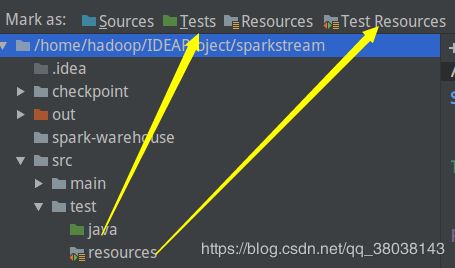
目录结构:
LoggerGenerator.class
import org.apache.log4j.Logger;
/**
* 模拟日志产生
*/
public class LoggerGenerator {
private static Logger logger = Logger.getLogger(LoggerGenerator.class.getName());
public static void main(String[] args) throws Exception {
int index = 0;
while (true) {
Thread.sleep((1000));
logger.info("value:" + index++);
}
}
}
log4j.properties
log4j.rootCategory=INFO, console, flume
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yyyy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# log to flume
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = master
log4j.appender.flume.Port = 41414
log4j.appender.flume.UnsafeMode = true
log4j.appender.flume.layout = org.apache.log4j.PatternLayout
pom.xml 依赖:
2.11.8
2.1.1
2.3.2
2.7.3
1.4.8
5.1.46
1.9.0
io.netty
netty-all
4.1.17.Final
org.jboss.netty
netty
3.2.4.Final
org.apache.spark
spark-streaming_2.11
${spark.version}
org.apache.spark
spark-sql_2.11
${spark.version}
org.apache.flume
flume-ng-auth
${flume.version}
org.mortbay.jetty
servlet-api
2.5-20110124
org.apache.spark
spark-streaming-flume-sink_2.11
${spark.version}
org.apache.commons
commons-lang3
3.5
org.apache.spark
spark-streaming-flume_2.11
${spark.version}
org.apache.avro
avro
1.7.4
org.apache.spark
spark-streaming-kafka-0-10_2.11
${spark.version}
com.fasterxml.jackson.module
jackson-module-scala_2.11
2.6.7.1
org.scala-lang
scala-library
${scala.version}
org.scalatest
scalatest
0.9.1
org.apache.kafka
kafka_2.11
${kafka.version}
org.apache.kafka
kafka-clients
${kafka.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
org.apache.hbase
hbase-client
${hbase.version}
org.apache.hbase
hbase-server
${hbase.version}
mysql
mysql-connector-java
${mysql.version}
org.specs
specs
1.2.5
test
org.apache.flume.flume-ng-clients
flume-ng-log4jappender
${flume.version}
org.apache.flume
flume-ng-sdk
${flume.version}
net.jpountz.lz4
lz4
1.3.0
。。。。
测试,先输出到flume:
在flume-1.9.0/conf 目录下创建:
streaming.conf
# Name the components on this agent
agent1.sources = avro-source
agent1.sinks = log-sink
agent1.channels = logger-channel
# Describe/configure the source
agent1.sources.avro-source.type = avro
agent1.sources.avro-source.bind = master
agent1.sources.avro-source.port = 41414
# Describe the sink
agent1.sinks.log-sink.type = logger
# Use a channel which buffers events in memory
agent1.channels.logger-channel.type = memory
# Bind the source and sink to the channel
agent1.sources.avro-source.channels = logger-channel
agent1.sinks.log-sink.channel = logger-channel
启动flume:
# 启动
bin/flume-ng agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/streaming.conf \
--name agent1 \
-Dflume.root.logger=INFO,console

运行LoggerGeneraotr:

日志产生器开发完成。。。
2. Spark Streaming 从kakfa读取数据
首先启动zookeeper,再启动kafka:
创建kafka主题:
# kafka 创建主题
kafka-topics.sh --create --zookeeper slave1:2181 \
--replication-factor 1 --partitions 1 --topic streaming_topic

创建StreamingKafkaApp.scala
从指定的topic 消费消息,并且计数输出到控制台:
package com.gyt.sparkstream
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
object StreamingKafkaApp {
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println("Usage: StreamingKafkaApp ")
System.exit(1)
}
val Array(brokers, groupId, topics) = args
// Create context with 2 second batch interval
val sparkConf = new SparkConf().setAppName("StreamingKafkaApp").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
// Create direct kafka stream with brokers and topics
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])
// Create direct inputStream
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
messages.map(_.value()).count().print()
// Start the computation
ssc.start()
ssc.awaitTermination()
}
}
测试程序:
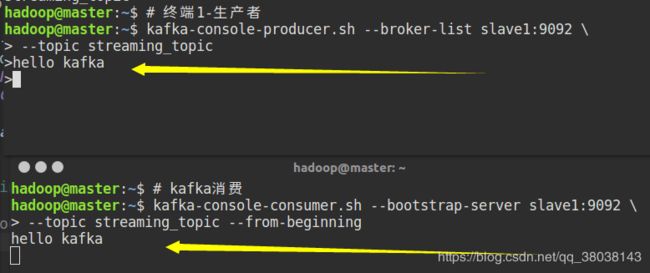
启动kafka生产者和消费者:
博主使用的是集群,如果你是但机器,启动但机器即可,slave1修改为你主机名
# 终端1-生产者
kafka-console-producer.sh --broker-list slave1:9092 \
--topic streaming_topic
# kafka消费
kafka-console-consumer.sh --bootstrap-server slave1:9092 \
--topic streaming_topic --from-beginning
测试:
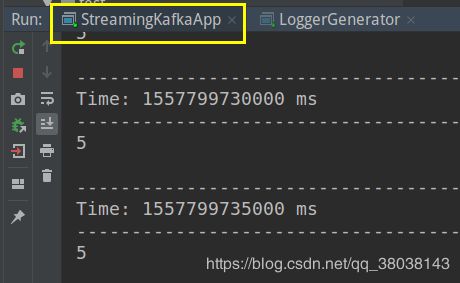
运行spark 程序,第一次报错,然后设置参数:

参数:broker group topic

在生产者出输入消息:

3. 启动日志生成器-Fluem-Kafka-Spark Streaming
运行Flume:为什么这样配置,可以查看Flume官网
flume-1.9.0/conf/streaming2.conf
# Name the components on this agent
agent1.sources = avro-source
agent1.channels = logger-channel
agent1.sinks = kafka-sink
# Describe/configure the source
agent1.sources.avro-source.type = avro
agent1.sources.avro-source.bind = master
agent1.sources.avro-source.port = 41414
# Describe the sink
agent1.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.kafka-sink.kafka.topic = streaming_topic
agent1.sinks.kafka-sink.kafka.bootstrap.servers = slave1:9092
agent1.sinks.kafka-sink.kafka.flumeBatchSize = 20
agent1.sinks.kafka-sink.kafka.producer.acks = 1
# Use a channel which buffers events in memory
agent1.channels.logger-channel.type = memory
# Bind the source and sink to the channel
agent1.sources.avro-source.channels = logger-channel
agent1.sinks.kafka-sink.channel = logger-channel
启动:
# 启动
bin/flume-ng agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/streaming2.conf \
--name agent1 \
-Dflume.root.logger=INFO,console
![]()
启动Kafka 服务:博主使用的是集群,如果你是但机器,启动但机器即可
运行Spark Streaming:

最后,运行日志生成器LoggerGenerator: