Python数据分析及可视化案例--2018成都市公共租赁住房家庭(个人)配租信息分析
前言
数据来源于成都市公共数据开放平台。
数据集:http://www.cddata.gov.cn/odweb/catalog/catalogDetail.htm?cata_id=fRa2EWB1EeeM9JrcteruXg434
通过分析该数据集,对成都市的租赁情况有一个基本了解,给需要租房的人们提供一定的参考。
运行环境:Jupyter Notebook
完整代码及数据集:
https://github.com/GYT0313/JupyterNotebook/tree/master/JupyterNotebook/matplotlib/data_visualization/shiyan/sheji2
正文
- 导入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 设置中文显示
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
# load data
data = pd.read_excel("./k_fgj_ggzfzl_gr_1.xls")
data.head()
数据预览:
2. 重设索引
因为数据的行索引是中文,在处理中可能会比较麻烦,这里设置为英文索引。
# 重设索引
data.columns = ["name", "id", "partition", "infos", "location", "type", "size"]
columns = data.columns
data.head()
3. 分析各城区租赁数量分布
# 1. 分析各城区租赁信息
data_groupby_partition = data.groupby(columns[2])[columns].count()
partition_city_count = data_groupby_partition["name"]
# print(partition_city_count)
# print(partition_city_count.values)
# print(partition_city_count.index)
# 饼图
# 距离圆心的距离-图上效果就是突出
explode = [0,0,0,0.1,0,0]
plt.figure(figsize=(6,6))
plt.pie(partition_city_count.values, explode=explode,labels=partition_city_count.index, autopct='%1.1f%%')
plt.title("成都市六大城区公共住房租赁数量统计")
plt.savefig("./成都市六大城区公共住房租赁数量统计-饼图.jpg")
plt.show()
# 条形图
x = range(6)
plt.bar(x, partition_city_count.values)
for x,y in zip(range(6), partition_city_count.values):
plt.text(x+0.05,y+0.05,'%d'%y, ha='center',va='bottom')
plt.title("成都市六大城区公共住房租赁数量统计")
plt.xticks(range(6), partition_city_count.index)
plt.savefig("./成都市六大城区公共住房租赁数量统计-条形图.jpg")
plt.show()
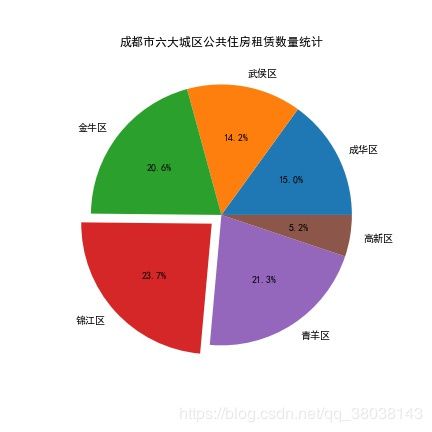
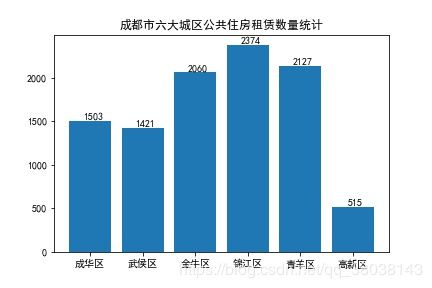
可以看出,锦江区的租赁数量最高,高新区数量最少。和城区的产业结构有很大关系。如,高新区是以办公为主,所以住房小区数相对来说是最少的。
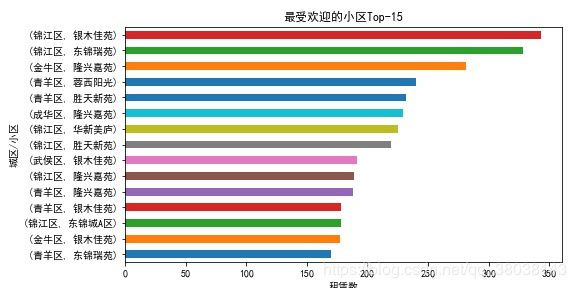
- 分析最受欢迎的小区Top-15
# 2.分析最受欢迎的小区
data.groupby([columns[2], columns[3]])[columns[3]].count().sort_values(ascending=False)\
.head(15).sort_values().plot(kind='barh', figsize=(8,4))
plt.title("最受欢迎的小区Top-15")
plt.tight_layout()
plt.ylabel("城区/小区")
plt.xlabel("租赁数")
plt.savefig("./最受欢迎的小区Top-15.jpg")
plt.show()
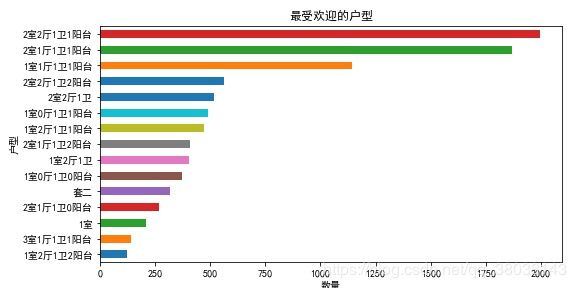
- 分析最受欢迎的户型
# 3. 分析最受欢迎的户型
data.groupby(columns[5])[columns[5]].count().sort_values(ascending=False)\
.head(15).sort_values().plot(kind='barh', figsize=(8,4))
plt.title("最受欢迎的户型")
plt.tight_layout()
plt.ylabel("户型")
plt.xlabel("数量")
plt.savefig("./最受欢迎的户型.jpg")
plt.show()
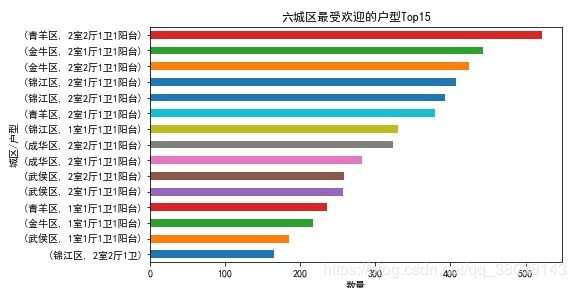
- 按城区分组-最受欢迎的户型
# 3. 按城区分析最受欢迎的户型
data.groupby([columns[2], columns[5]])[columns[5]].count().sort_values(ascending=False)\
.head(15).sort_values().plot(kind='barh', figsize=(8,4))
plt.title("六城区最受欢迎的户型Top15")
plt.tight_layout()
plt.ylabel("城区/户型")
plt.xlabel("数量")
plt.savefig("./六城区最受欢迎的户型Top15.jpg")
plt.show()
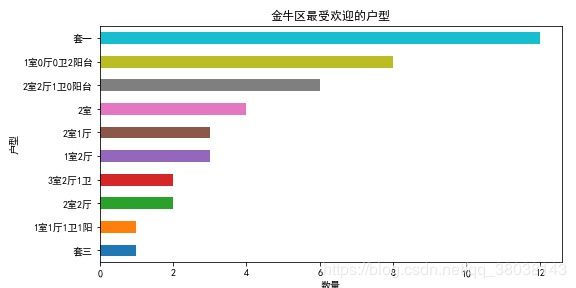
- 分析每个城区最受欢迎的户型–六张图
# 6张图-按照城区单独分析最受欢迎的户型
#print(data.groupby([columns[2], columns[5]])[columns[2]].count().loc["成华区"])
partitions = pd.unique(data["partition"])
# 遍历六个城区
for p,i in zip(partitions, range(6)):
data.groupby([columns[2], columns[5]])[columns[2]].count().loc[p].sort_values()\
.head(10).plot(kind='barh', figsize=(8,4))
plt.title("{}最受欢迎的户型".format(p))
plt.tight_layout()
plt.ylabel("户型")
plt.xlabel("数量")
plt.savefig("./{}最受欢迎的户型Top15.jpg".format(p))
plt.show()
这里只贴两张图:
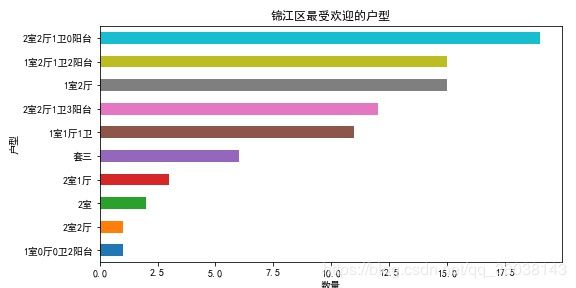
- 分析每个城区最受欢迎的户型–一张图
# 一张图-按照城区单独分析最受欢迎的户型
#print(data.groupby([columns[2], columns[5]])[columns[2]].count().loc["成华区"])
partitions = pd.unique(data["partition"])
pf = plt.figure(figsize=(10,12), dpi=80)
# 设置标题
plt.title("各城区最受欢迎的户型\n", fontsize=18)
plt.xlabel("\n数量", fontsize=15)
plt.ylabel("户型\n\n\n\n\n", fontsize=15)
# 避免坐标重叠
plt.xticks([])
plt.yticks([])
# 便利6个城区,并添加子图
for p,i in zip(partitions, range(6)):
pf.add_subplot(3,2,i+1)
data.groupby([columns[2], columns[5]])[columns[2]].count().loc[p].sort_values()\
.head(10).plot(kind='barh', figsize=(10,10))
plt.tight_layout()
plt.title("{}".format(p))
plt.ylabel("")
pf.savefig("./各城区最受欢迎的户型Top10.jpg")
pf.show()
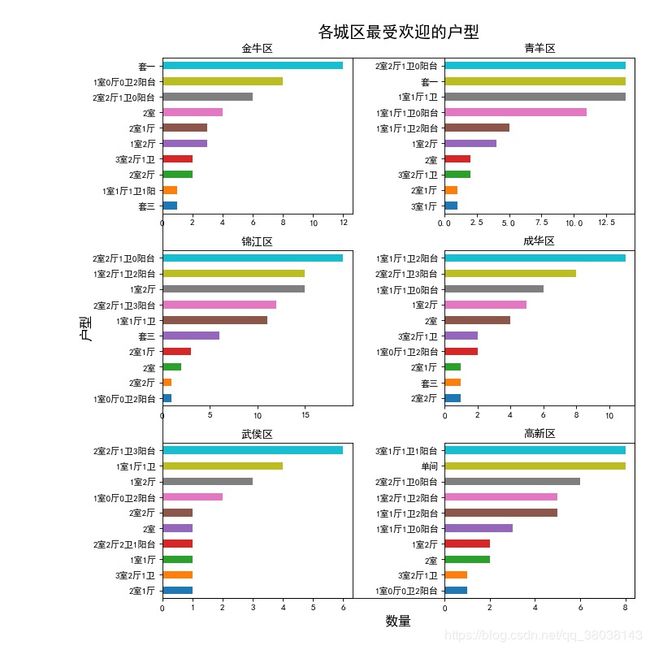
- 分析租赁房按分组大小占比–饼图
# 1张图-六城区总的房间大小分区统计
max = data["size"].max()
min = data["size"].min()
# 设置分组
limit = range(int(min-min%10), int(max+10), 10)
# 进行分组
size_limit_group = pd.cut(data["size"], limit, right=False)
# 分组后的计数
size_group_count = size_limit_group.value_counts()
# 是否需要取样、排序。。。
data_sort = size_limit_group.value_counts()#.sample(frac=1)#.sort_values()
# 按照大小间隔排序,避免重叠
# 如:1 2 3 4 5 6 7 -> 7 2 5 4 3 6 1
print(data_sort)
length = len(data_sort.values)
indexs = [str(x) for x in data_sort.index]
for i, j in zip(range(0, length, 2), range(length-1, 0, -2)):
if j <= i:
break
data_sort.iloc[i],data_sort.iloc[j] = data_sort.iloc[j],data_sort.iloc[i]
indexs[i], indexs[j] = indexs[j], indexs[i]
data_sort = pd.Series(data_sort.values, index=indexs)
print(data_sort)
# 绘图
plt.pie(data_sort.values, labels=[str(x) for x in data_sort.index],autopct='%1.1f%%')
plt.title("租赁房大小比例(m^2)")
plt.tight_layout()
plt.savefig("./租赁房大小比例(m^2).jpg")
plt.show()
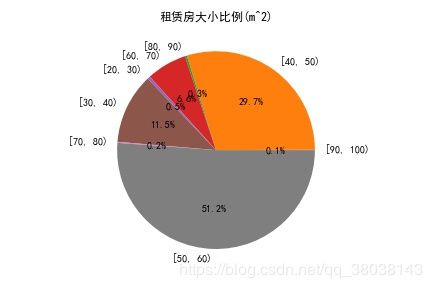
- 分析租赁房按分组大小占比–条形图
# 6张图-六城区总的房间大小分区统计
max = data["size"].max()
min = data["size"].min()
limit = range(int(min-min%10), int(max+10), 10)
# 按照城区分组
size_group_by_partition = data.groupby("partition")
# 每个城区的分组频数统计
partitions_limit_group = []
# 强转 --> [("高新区", DataFrame), ("锦江区", DataFrame), ...]
size_group_by_partition = list(size_group_by_partition)
# 遍历统计
for partition_df in size_group_by_partition:
partitions_limit_group.append(pd.cut(partition_df[1]["size"], limit, right=False).value_counts())
# 绘图
pf = plt.figure(figsize=(10,8), dpi=80)
# 设置标题
plt.title("各城区租赁房大小分组统计\n", fontsize=18)
plt.xlabel("\n数量", fontsize=15)
plt.ylabel("分组\n\n\n\n", fontsize=15)
# 避免坐标重叠
plt.xticks([])
plt.yticks([])
# 遍历6个城区,并添加子图
for p,i in zip(partitions_limit_group, range(6)):
pf.add_subplot(3,2,i+1)
p.sort_values().plot(kind='barh')
plt.tight_layout()
plt.title("{}".format(size_group_by_partition[i][0]))
plt.ylabel("")
pf.savefig("./各城区租赁房大小统计.jpg")
pf.show()
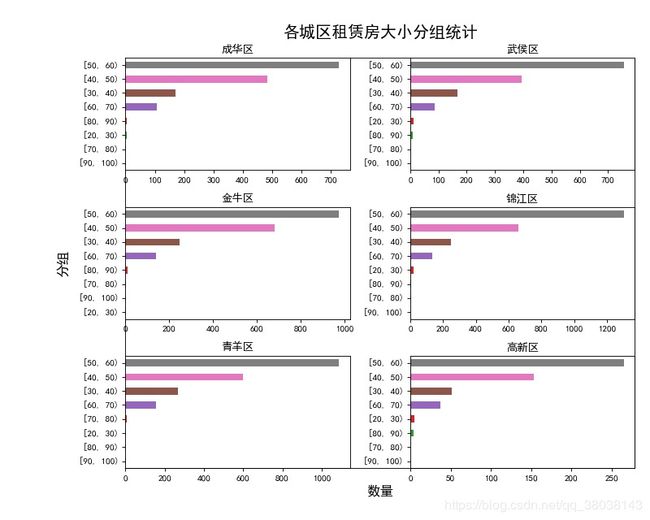
最后这张图感觉可有可无,分组占比顺序几乎一样。。。