JavaAPI操作hdfs文件系统
由于需要Hadoop的jar包,为了方便一些,可以使用hadoop的jar包,自己弄成一个库.
把cenos-6.5-hadoop-2.6.4\hadoop-2.6.4\share\文件夹的hadoop单独复制出来
将jar包添加过来:

选择用户类库:
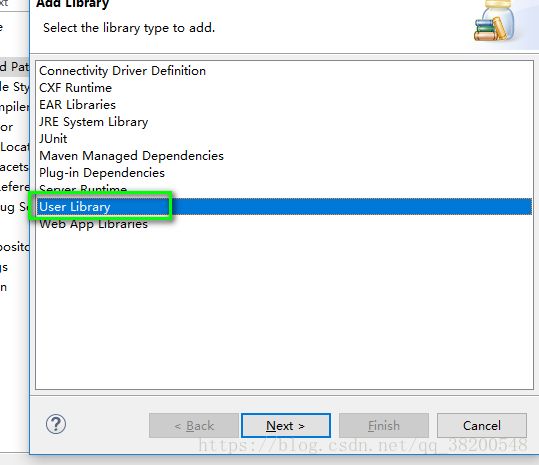
新建类库:
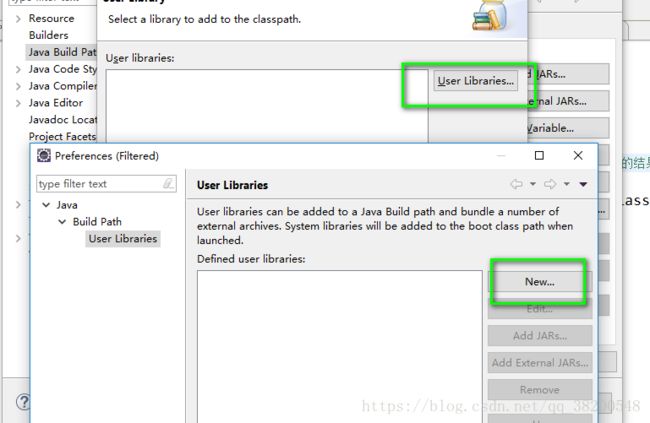
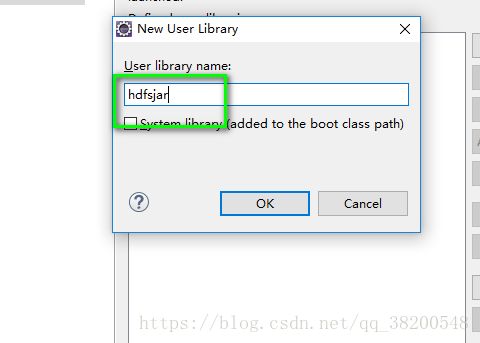
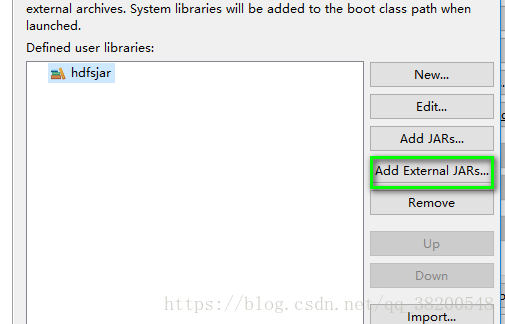
需要导入的jar包:
1.common:
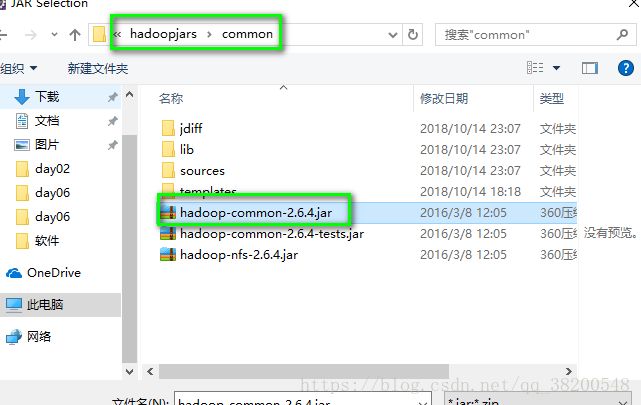
这个common包也需要其他的依赖:
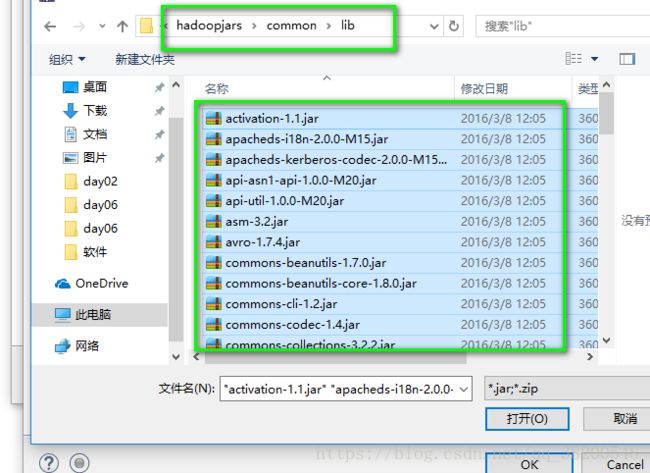
2.添加common下的lib下的所有的jar包
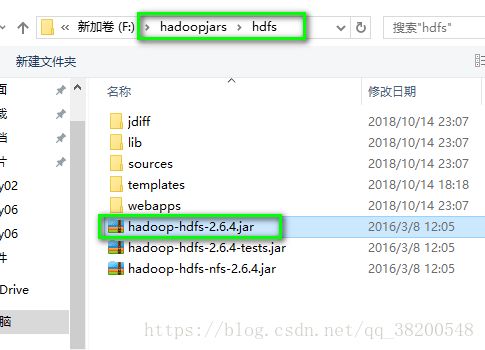
3.还需要hdfs的核心包:
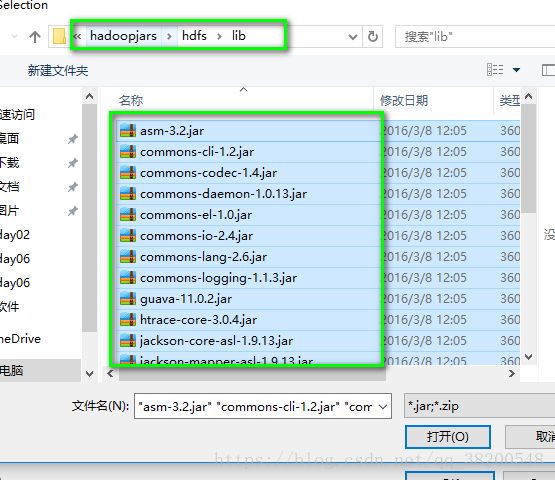
4.还需要hdfs依赖的其他的jar包,由于是同一个版本的,是重复的,就可以进行覆盖:
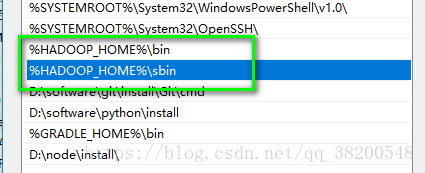
需要在本地使用Java API操作Linux的文件系统,首先,需要配置HADOOP_HOME:

配置好了之后还没有完成,因为我们配置的时候使用的是Linux版本的Hadoop安装软件,这个bin跟lib文件夹的文件都是在Linux下进行编译的,所以不能直接放在windows上使用.
我们需要使用windows版本的Hadoop安装软件.
https://pan.baidu.com/s/1uu8tKq3FvoemccoUiBob0Q
我们只需要这个windows版本的Hadoop安装软件进行解压,然后将其中的bin和lib文件夹替换linux版本的对应的文件夹.
Linux下Hadoop的bin文件夹:
windows下的Hadoop的lib文件夹:
bin跟lib下的东西是跟本地有关的.
测试代码:
public class HdfsClient {
FileSystem fs = null;
@Before
public void init() throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://bd1:9000");
/**
* 参数优先级:1.客户端代码中设置的值 2,classpath下用户自定义的配置文件 3,然后是服务器的默认配置
*/
conf.set("dfs.replication", "3");
fs = FileSystem.get(conf);
}
@Test
public void testAddFileToHdfs() throws IllegalArgumentException, IOException {
fs.copyFromLocalFile(new Path("f:/c.txt"), new Path("/"));
fs.close();
}
}
需要设置参数,指定Hadoop用户,否则的话,权限会被拒绝.
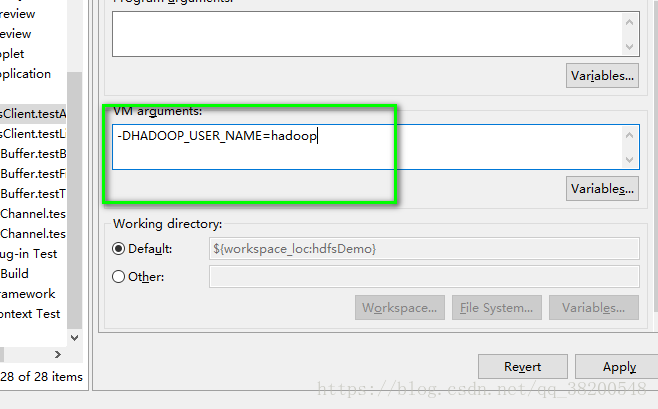
或者可以通过代码进行设置:
@Before
public void init() throws IOException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
fs = FileSystem.get(new URI("hdfs://bd1:9000"), conf, "hadoop");
}
遍历整个hdfs文件系统的文件:
/**
* 只会遍历文件,而不会遍历文件夹
* @throws FileNotFoundException
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void testListFiles() throws FileNotFoundException, IllegalArgumentException, IOException {
RemoteIterator listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println(fileStatus.getPath().getName());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getLen());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for(BlockLocation bl : blockLocations) {
System.out.println("block-length:" + bl.getLength() + " -- " + "block-offset:" + bl.getOffset());
String[] hosts = bl.getHosts();
for(String host : hosts) {
System.out.println(host);
}
}
System.out.println("-----------------------");
}
}
打印的结果:
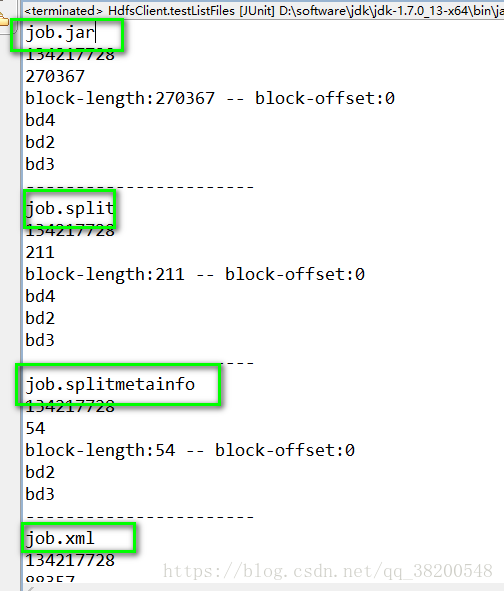
里面会出现这四个文件:
jab.jar job.split job.splitmetainfo job.xml
这四个文件出现的原因就是由于我之前执行了MapReduce程序,产生的日志这个日志是在hdfs文件系统的根目录下的tmp文件夹里面的,这个文件夹在网页端是没有权限访问的,得在Linux系统上访问hdfs文件系统
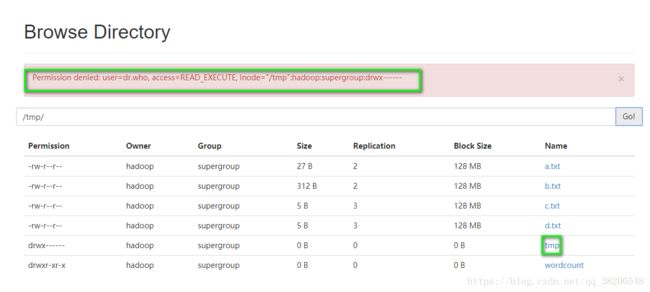
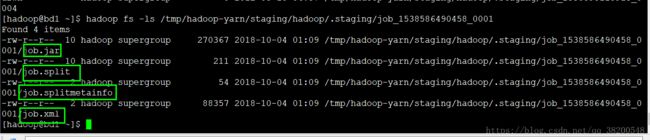
/**
* 查看文件以及文件夹信息
* @throws IOException
* @throws IllegalArgumentException
* @throws FileNotFoundException
*/
@Test
public void testListAll() throws FileNotFoundException, IllegalArgumentException, IOException {
FileStatus[] listStatus = fs.listStatus(new Path("/"));
String flag = "d------------";
for(FileStatus fstatus : listStatus) {
if(fstatus.isFile()) flag = "f-- ";
System.out.println(flag + fstatus.getPath().getName());
}
}
打印的结果:
f-- a.txt
f-- b.txt
f-- c.txt
f-- d.txt
f-- tmp
f-- wordcount
通过流的方式访问hdfs:
public class StreamAccess {
FileSystem fs = null;
@Before
public void init() throws IOException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
fs = FileSystem.get(new URI("hdfs://bd1:9000"), conf, "hadoop");
}
}
下载文件:
@Test
public void testDownloadToLocal() throws IllegalArgumentException, IOException {
// 先获取一个文件的输入流--针对hdfs上的
FSDataInputStream in = fs.open(new Path("/a.txt"));
// 再构造一个文件的输入流--针对本地的
FileOutputStream out = new FileOutputStream(new File("f:/a.txt"));
// 在将输入流中数据传入到输出流
IOUtils.copyBytes(in, out, 4096);
}
自定义流的起始偏移量:
/**
* hdfs支持随机定位进行文件读取,而且可以方便地读取指定长度
* 用于上层分布式运算框架并发处理数据
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testRandomAccess() throws IllegalArgumentException, IOException {
FSDataInputStream in = fs.open(new Path("/b.txt"));
// 可以将流的起始偏移量进行自定义
in.seek(10);
FileOutputStream out = new FileOutputStream(new File("f:/b.txt"));
IOUtils.copyBytes(in, out, 19L, true);
}
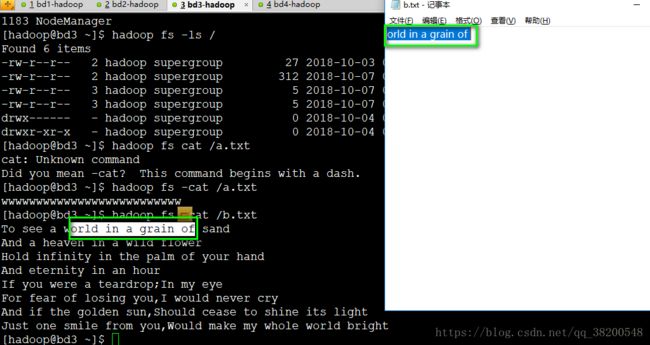
显示hdfs上文件的内容:
/**
* 显示hdfs上文件的内容
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void testCat() throws IllegalArgumentException, IOException {
FSDataInputStream in = fs.open(new Path("/b.txt"));
// 直接输出在控制台
IOUtils.copyBytes(in, System.out, 1024);
}
