python网络爬虫(一) 爬取网站图片
网络爬虫系列
python网络爬虫(一) 爬取网站图片
python网络爬虫(二)分页爬取图片
什么是网络爬虫?
网络爬虫(Web Spider),又被称为网页蜘蛛,是一种按照一定的规则,自动地抓取网站信息的程序或者脚本。网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
爬虫流程
用户获取网络数据的方式:
- 方式1:浏览器提交请求—>下载网页代码—>解析成页面
- 方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中,爬虫要做的就是方式2。
-
发起请求
- 使用request模块的get、post函数
- 使用url全球统一资源定位符,用来定义互联网上一个唯一的资源 例如:一张图片、一个文件、一段视频都可以用url唯一确定。
- 请求头User-agent:请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户host;
- 请求体如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data。
-
网站相响应
- 返回值含义:200为代表成功,301为代表跳转,404为文件不存在,403为无权限访问,502为服务器错误。
利用python request库爬取网站图片
- 爬取网站:http://desk.zol.com.cn/dongman/1920x1080/
- 进入网站后右击审查,查看Elements部分:
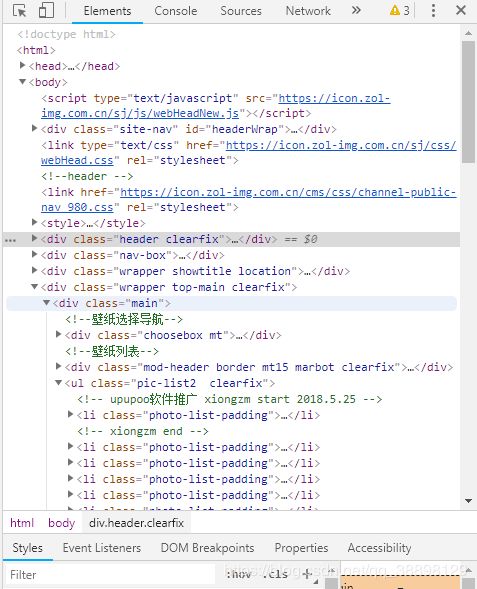
- 鼠标移动到一张图片上,会显示图片信息:
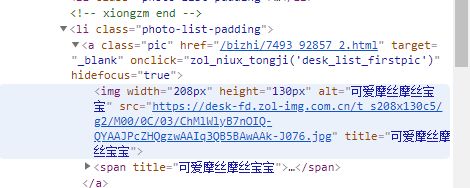
我们需要的就是img标签下的src部分。 - 接下来查看Network部分,选择Img查看相关信息,得到User-Agent和Referer的信息作为Headers的一部分:
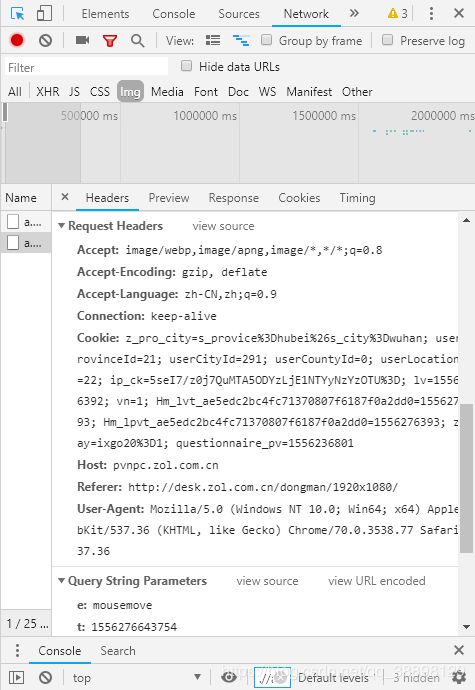
- 具体代码见代码部分。
代码部分
import requests
import time
from lxml import etree
url = 'http://desk.zol.com.cn/dongman/1920x1080/'
headers = {"Referer":"Referer: http://desk.zol.com.cn/dongman/1920x1080/",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",}
resq = requests.get(url,headers = headers)
print(resq)
html = etree.HTML(resq.text)
srcs = html.xpath(".//img/@src")
for i in srcs:
imgname = i.split('/')[-1]
img = requests.get(i,headers = headers)
with open('imgs1/'+imgname,'wb') as file:
file.write(img.content)
print(i,imgname)
爬取结果
- 显示爬取的信息
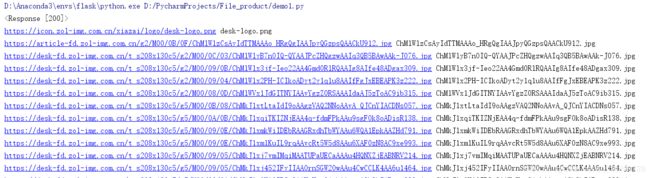
- 在相应文件夹下查看图片是否爬取成功
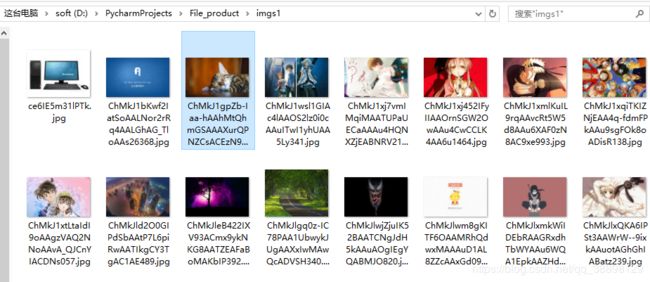
可以发现图片成功爬取了。