【yolov3】【2】yolov3-spp结构详解与源码解析(pytorch)
更新:增加了test.py部分的源码解析,包含mAP的计算。
更新:我的机子是pytorch0.4的,所以在训练时候踩了一些坑,把这些问题和解决方法放在yolov3网络训练踩坑纪实(pytorch)中。
yolov3-spp是yolov3的一个版本,在yolo官网中给出了cfg和weights。
本文调试源码为ultralytics/yolov3,参考博客为yolo系列之yolo v3【深度解析】
文章目录
- 结构详解
- train.py源码解析
- 数据预处理和加载
- 前向传播
- 计算loss
- 后续
- test.py源码解析
结构详解
参考yolo系列之yolo v3【深度解析】。对照这一博客中的网络结构图↓,将cfg文件print出来,分析了一下,如下图所示(注意,博客是yolov3非spp的结构,这里的输入是416x416的)。
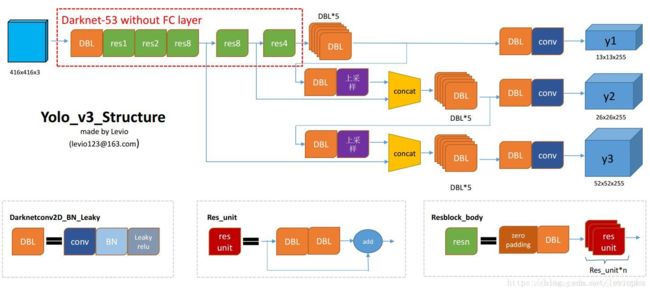

其中,各个module的含义如下:
convolutional:对应博客中的DBL或conv,主要是看有没有batch normalize,以及是否加了leaky rulu
shortcut:res_unit的跨层连接
route:重新从之前某层的输出开始forward 或 concat,主要是看'layers'这个参数是一个参数还是两个
upsample:上采样
yolo:一共有三次,输出分别是13、26和52
具体参考源码中models.py的Darknet类的forward
train.py源码解析
调试的是Example: Train Single Image,按照步骤一步步来就可以了
数据预处理和加载
在train.py中,将dataset装在dataloader中,并用tqdm循环。
在utils/datasets.py中定义了datasets,在__getitem__中返回经过了augment等预处理的image和labels。其中,label被处理为[0 class x y w h]格式(均经过归一化)。
前向传播
model = Darknet(cfg).to(device)
……
pred = model(imgs)
models.py中,在__init__将cfg文件中储存的网络结构,逐行读入self.module_defs,并调用create_modules生成对应的module,存入self.module_list,在forward中进行前向传播。
forward输出的output是一个list,共包含3项,均为yolo层的输出,分别为[1,3,13,13,85],[1,3,26,26,85],[1,3,52,52,85]。(By the way,之前的yolo层,是将输入的255x13x13中的255,展开成3x85,85 = 80classes + xywh + confidence,3为每个grid对应的anchor数目)
计算loss
loss部分可以参见YOLOv3 Loss构建详解
loss, loss_items = compute_loss(pred, targets, model)
在utils/utils.py中的compute_loss计算loss
计算loss,主要用到了build_targets和compute_loss
build_targets
输入:
model
targets:[0 class x y w h]格式的label
输出:
tcls, tbox, indices, av(anchor_vec),四个长度为3的list,对应3个尺度的yolo layer输出(具体的参照代码注释)
| tcls[0] | tbox[0] | indices[0] | av[0] |
|---|---|---|---|
| torch.size([n]) | torch.size([n, 4]) | 长度为4的tuple,每个元素都是torch.size([n])的tensor | torch.size([n, 4]) |
| class | gxy+gwh,即xywh(grid),且gxy减掉了整数部分 | 索引b, a, gj, gi,对应yolo_layer的输出维度 | anchor_vec |
代码注释:
def build_targets(model, targets):
# targets = [image, class, x, y, w, h]
nt = len(targets) # 一个batch中的target总数
tcls, tbox, indices, av = [], [], [], []
multi_gpu = type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
for i in model.yolo_layers:
# get number of grid points and anchor vec for this yolo layer
# 获取对应yolo layer的ng(grid数目,13*13或26*26或52*52)以及anchor vec
if multi_gpu:
ng, anchor_vec = model.module.module_list[i].ng, model.module.module_list[i].anchor_vec
else:
ng, anchor_vec = model.module_list[i].ng, model.module_list[i].anchor_vec
# iou of targets-anchors
t, a = targets, []
gwh = t[:, 4:6] * ng # 将w和h都scale到0~ng之间
if nt:
# 计算iou,得到torch.size([anchor数目(3),target数目(假设为25)])
iou = torch.stack([wh_iou(x, gwh) for x in anchor_vec], 0)
use_best_anchor = False
if use_best_anchor:
iou, a = iou.max(0) # best iou and anchor
else: # use all anchors
na = len(anchor_vec) # number of anchors —— 3
a = torch.arange(na).view((-1, 1)).repeat([1, nt]).view(-1) # target-anchor pair中的anchor idx[0,0,...0,1,1...,1,2,2...2],size = 75
t = targets.repeat([na, 1]) # target-anchor pair中的target,size = 75 * 6
gwh = gwh.repeat([na, 1]) # target-anchor pair中的target的w和h
iou = iou.view(-1) # use all ious,target-anchor pair的iou
# reject anchors below iou_thres (OPTIONAL, increases P, lowers R)
reject = True
if reject:
# 根据iou筛选target-anchor pair
j = iou > model.hyp['iou_t'] # iou threshold hyperparameter
t, a, gwh = t[j], a[j], gwh[j]
# Indices
try:
b, c = t[:, :2].long().t() # target-anchor pair对应的target image, class
gxy = t[:, 2:4] * ng # target-anchor pair对应的grid x, y
except:
tcls.append(None)
tbox.append(None)
indices.append(None)
av.append(None)
continue
gi, gj = gxy.long().t() # grid x, y indices
indices.append((b, a, gj, gi)) # target-anchor pair对应的target image, anchor idx(0,1或2), grid x, grid y
# GIoU
gxy -= gxy.floor() # xy
tbox.append(torch.cat((gxy, gwh), 1)) # target-anchor pair中target的xywh (grids),其中,x,y是相对于当前grid的
av.append(anchor_vec[a]) # target-anchor pair中的anchor vec
# Class
tcls.append(c) # target-anchor pair中target的class
if c.shape[0]: # if any targets
assert c.max() <= model.nc, 'Target classes exceed model classes'
return tcls, tbox, indices, av
compute_loss
输入
p:网络输出,3个尺度的yolo tensor
targets:[0 class x y w h]格式的label
model
输出
loss,((lbox, ft([0]), lobj, lcls, loss))
过程
build_targets得到对应3个尺度yolo tensor的tcls, tbox, indices, av(anchor_vec)- 遍历3个尺度,进行3~8
- 提取p的其中一个tensor,即pi,同时提取对应的b, a, gj, gi
- tobj = torch.zeros_like(pi[…, 0])(pi[1,3,26,26,85],tobj[1,3,26,26])
- 对每一个尺度中的n个build出来的target-anchor pair,设置tobj对应位置的值为1,提取tensor的对应位置ps(torch.size([n, 85]))
- 将ps[:, 0:2],ps[:, 2:4]作为yolov3论文公式中的tx,ty,tw,th,计算pbox,与tbox比较计算giou,并通过lbox += (1.0 - giou).mean()更新总的位置loss——lbox
- 建立一个与ps[:, 5:]相同尺寸的全0的tensor,设置对应的类别位置为1,与ps[:, 5:]比较,更新总的类别loss——lcls
- 提取pi[…, 4](torch.size([1,3,26,26])),与tobj比较,更新总的物体loss——lobj(注意,这里的lbox和lcls是仅对
tragets对应的prediction区域进行计算的,而lobj是对所有prediction区域计算的) - 将lcls, lbox, lobj加权相加得到总的loss
后续
loss的backward,optimizer.step(),更新mean loss,计算mAP,保存checkpoint等
test.py源码解析
test.py包含了test函数,函数的核心是一个三层的循环,把核心部分的代码抽取出来,如下:
for batch_i, (imgs, targets, paths, shapes) in enumerate(tqdm(dataloader, desc=s)):
inf_out, train_out = model(imgs) # train模式是只有一个输出的,但在eval模式中,分别输出了inference的结果和train的结果,前者将网络预测的offset映射成了xywh(具体差别参看model.py的YOLOLayer类的forward函数中的if self.training判断)
output = non_max_suppression(inf_out, conf_thres=conf_thres, nms_thres=nms_thres) #output是长度为batch-size的list,list中的每个元素是size为[k, 7]的tensor
for si, pred in enumerate(output): # 对一个batch中的每张图片分别处理
labels = targets[targets[:, 0] == si, 1:] # 提取图片的target中的nl个labels
nl = len(labels) # target个数
tcls = labels[:, 0].tolist() if nl else [] # target class,长度为nl
# Assign all predictions as incorrect
correct = [0] * len(pred) # 长度为k
if nl:
detected = []
tcls_tensor = labels[:, 0] # 长度为nl
# target boxes
tbox = xywh2xyxy(labels[:, 1:5]) # size为nl * 4,对应的尺寸是416*416
tbox[:, [0, 2]] *= width
tbox[:, [1, 3]] *= height
# Search for correct predictions,遍历k次(对应[k, 7])
for i, (*pbox, pconf, pcls_conf, pcls) in enumerate(pred):
# Best iou, index between pred and targets
m = (pcls == tcls_tensor).nonzero().view(-1) # 和pred类别相同的ground-truth idx
iou, bi = bbox_iou(pbox, tbox[m]).max(0) # 从相同类别的gt中,选出和pred的iou最大的,获取iou和idx
# If iou > threshold and class is correct mark as correct
if iou > iou_thres and m[bi] not in detected: # and pcls == tcls[bi]:
correct[i] = 1 # pred对应的位置置1
detected.append(m[bi]) # 将对应的gt归入detected
# Append statistics (correct, conf, pcls, tcls)
# 对应长度:k, k, k, nl
# 一共有k个检测结果,其中,correct是对检测结果的pos/neg的标记,conf和pcls是对每个结果置信度和类别的标记
stats.append((correct, pred[:, 4].cpu(), pred[:, 6].cpu(), tcls)) # 每一张图片,生成一个stats的项
if len(stats):
p, r, ap, f1, ap_class = ap_per_class(*stats)
mp, mr, map, mf1 = p.mean(), r.mean(), ap.mean(), f1.mean()
nt = np.bincount(stats[3].astype(np.int64), minlength=nc) # number of targets per class
else:
nt = torch.zeros(1)
这里使用到了ap_per_class函数,在utils.py中:
输入:tp, conf, pred_cls, target_cls(test.py中的stats),长度分别为k, k, k, nl
输出:p, r, ap, f1, unique_classes
代码:
# Sort by objectness, 将前三个输入按照conf降序排序
i = np.argsort(-conf)
tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
# Find unique classes,获取gt中的label列表
unique_classes = np.unique(target_cls)
# Create Precision-Recall curve and compute AP for each class,为每一类计算ap
ap, p, r = [], [], []
for c in unique_classes:
i = pred_cls == c
n_gt = (target_cls == c).sum() # Number of ground truth objects
n_p = i.sum() # Number of predicted objects
if n_p == 0 and n_gt == 0:
continue
elif n_p == 0 or n_gt == 0:
ap.append(0)
r.append(0)
p.append(0)
else:
# Accumulate FPs and TPs
fpc = (1 - tp[i]).cumsum() # 计算一个长度为n_p的False Positive累加向量(到目前为止,有多少个误检)
tpc = (tp[i]).cumsum() # 计算一个长度为n_p的True Positive累加向量(到目前为止,有多少个正检)
# Recall
recall = tpc / (n_gt + 1e-16) # recall curve,p-r曲线中的r值
r.append(recall[-1])
# Precision
precision = tpc / (tpc + fpc) # precision curve,p-r曲线中的p值
p.append(precision[-1])
# AP from recall-precision curve
ap.append(compute_ap(recall, precision)) # 根据p-r曲线,计算总面积,即ap
# Compute F1 score (harmonic mean of precision and recall)
p, r, ap = np.array(p), np.array(r), np.array(ap)
f1 = 2 * p * r / (p + r + 1e-16)
return p, r, ap, f1, unique_classes.astype('int32')