Python常用模块总结
目录
一:定义
二:time
三:datetime模块
四:random模块
五:os模块
六:sys模块
七:hashlib模块
八:logging模块
九:configparser模块
十:re模块
十一:json&pickle模块
十二:shielve模块
十四:logging模块
一:定义
某个功能代码的集合,为了完成业务需求,采用拿来主义,直接调用即可,把更多的时间放在逻辑处理。模块一般分为三种:
- 自定义模块
- 内置标准库
- 开源模块
使用模块的好处
- 提高代码的可维护性
- 编写代码不需要从0开始
模块和包导入方法
模块是为了组织函数方法,就是一个*.py;包是为了组织模块,是多个模块的集合,包含一个__init__.py文件
import 导入某个模块名(通过sys.path找到对应的文件)
import 导入某个包 执行__init__.py文件
from 模块 import 方法
from 包 import 模块
from 包.模块 import 方法
路径问题
在sys.path加入包的路径
import os,sys
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
'''
__file__:指的是当前文件位置的相对路径
os.path.abspath(__file__):返回当前文件位置的绝对路径
os.path.dirname(os.path.abspath(__path__)):返回当前文件路径的上一级路径
'''
from module.main1 import main
main()
'''
也可以使用这种方法
from moudule import main1
main1.main()
'''二:time
时间的相关操作,有三种表现形式
- 时间戳 1970年1月1日之后的秒 即:time.time()
- 格式化的字符串 2019-11-11-11 即:time.strftime('%Y-%m-%d')
- 结构化时间 元组包含了:年月日等 即: time.localtime() 北京时间 (time.gmtime() UTC时间)
time.strftime("%Y{a}-%m{b}-%d{c} %X", time.localtime()).format(a='年',b='月',c='日')
time.strptime('2019-05-05 16:37:06', '%Y-%m-%d %X')
输出指定字段如年使用a.tm_year,其他类似
b=time.mktime(a) 把struct_time转换为时间戳
输入print(help(time))可出现如下提示
%y (00-99)
%Y Year with century as a decimal number.
%m Month as a decimal number [01,12].
%d Day of the month as a decimal number [01,31].
%H Hour (24-hour clock) as a decimal number [00,23]. %I(01-12)
%M Minute as a decimal number [00,59].
%S Second as a decimal number [00,61].
%a Locale's abbreviated weekday name.
%A Locale's full weekday name.
%b Locale's abbreviated month name.
%B Locale's full month name.

三:datetime模块
进行时间运算最方便
datetime.datetime.now() 输出一个标准时间:2019-01-07 16:44:57.614705
四:random模块
import random
print(random.random()) #产生0,1的小数
print(random.randint(1,2)) #产生1,2的整数,包括2
print(random.randrange(1,10)) #产生一个范围的整数,不包括10产生四位随机大小验证码
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print(checkcode)五:os模块
提供对操作系统进行调用的接口,能和操作系统进行交互
- os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
- os.chdir('dir') 改变当前脚本的工作目录;相当于shell下的cd
- os.curdir 返回当前目录('.')
- os.pardir 返回当前目录的父目录字符串名('..')
- os.mkdir('dir') 生成单级目录,相当于shell下的mkdir dir
- os.rmdir('dir') 删除单级目录,相当于shell下的rmdir dir
- os.remove() 删除文件
- os.rename('oldname','newname') 重命名文件/目录
- os.sep 输出操作系统特定的路径分割符,Windows下为 \ Linux下为 /
- os.linesep 输出当前平台的行终止符 Windows下为 \r\n Linux下为\n
- os.name 输出字符串指示当前使用的平台 Windows下为 ‘nt’ Linux下为'posix'
- os.system('cmd') 运行shell命令,直接显示
- os.environ 显示系统环境变量
- os.path.abspath(path) 返回path规范化的绝对路径
- os.path.split(path) 将path分割成目录和文件名二元组返回
-
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回FALSE
六:sys模块
提供一个和Python解释器交互的接口,能和Python解释器进行交互
- sys.argv 返回命令行参数列表,第一个参数是程序的本身路径,使用其他参数可以使用索引
- sys.exit(n) 退出程序,正常退出时是exit(0)
- sys.version 获取Python解释器的版本信息
- sys.path 返回模块的搜索路径,当前文件夹,然后一直想歪
- sys.platform 返回操作系统的名称 windwos下返回 win32字符串
- sys.stdout.write('aaa') 这个长用于python2中的输出不换行中,2.x中print 默认会输出‘\n’
- sys.stdin.readline() 类似于raw_input ,但是这个会获得‘\n’
七:hashlib模块
用于加密的相关操作
import hashlib
m=hashlib.md5()
m.update('hello'.encode('utf-8'))#md5的参数是byte类型,
#*.py3中字符串的存储类型默认是Unicode编码,需要encode()转换为utf-8
print(m.digest()) #digest() 返回二进制的hash值
print(m.hexdigest()) #hexdigest() 返回十六进制的hash值
#其余加密方法类似
hash1=hashlib.sha256()
hash1.update('hello'.encode('utf-8'))
print(hash1.hexdigest())八:logging模块
很多程序都有记录日志的需求,并且日志中 包含的信息除了正常访问的日志,还有错误,警告灯信息的输出
Python提供了logging模块提供了标准的日志接口,通过它可以存储各种格式的日志
简单应用:
import logging
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message') 输出:
WARNING:root:warning message
ERROR:root:error message
CRITICAL:root:critical message
默认情况下Python的logging模块打印了大于等于warning级别的日志,说明默认的是waring
日志级别critical 》error 》warning 》 info 》debug 》noset
九:configparser模块
用于生成和修改配置文件,产生一些好看的配置文档,实质就是字典的不断嵌套循环使用
import configparser
config=configparser.ConfigParser()
config['DEEAULT']={'ServerAliver':'45',
'Compression':'yes',
'Comprsseleve':'69'
}
config['topsecre.sere']={}
topset=config['topsecre.sere']
topset['HOst Poar']='5022'
topset['forwardxaa']='no'
with open('a.ini','w') as configfile:
config.write(configfile)
#产生一个如下格式的文档
[DEEAULT]
serveraliver = 45
compression = yes
comprsseleve = 69
[topsecre.sere]
host poar = 5022
forwardxaa = no十:re模块
正则表达式
正则表达式的主要功能是用来做字符串匹配的,字符串本身自带匹配功能,为了更加灵活的匹配字符串,引入了正则表达式,可以
进行模糊匹配,其中字符串所能做到的只有完全匹配
正则表达式是一种小型的、高度专业化的编程语言,有其自己的语法,唯一的功能是字符串匹配
各种编程语言,都是在其基础之上,进行扩充,使得正则具有更加强大的功能。在Python中,通过re模块实现。正则表达式被编译
成一系列的字节码,然后由C编写的匹配引擎执行。
字符匹配分为两种:普通字符匹配和元字符匹配
下面最主要介绍元字符匹配
- . 可以匹配任意字符,除了换行符(\n)
- ^ 匹配字符串开头,在多行模式中匹配每一行的开头
- $ 匹配字符串末尾,在多行模式中匹配每一行的末尾
- * 匹配前一个字符0或无限次
- + 匹配前一个字符1次或无限次
- ? 匹配前一个字符0 或一次
- {} 自定义匹配次数,{1,}匹配1或者无穷次
- [] 字符集:匹配其中的一个 特殊功能:取消元字符的特殊功能,例外( \ 转义( ] - ^) 或者把这几个放第一位
^ 反 -到)
9 | 或者
10 () 做分组
11 \ 转义字符,使后一个字符改变原来意思 后面跟普通字符实现特殊功能 后面跟元字符去除特殊功能
\d 数字[0-9]
\D 非数字 [^0-9]
\s 匹配任何非空白字符 [\t\n\r\f\v]
\S 匹配任何非空白字符 [^\t\n\r\f\v]
\w 匹配字符数字 [a-zA-Z0-9]
\w 匹配任何非字符数字 [^a-zA-Z0-9]
\b 匹配一个特殊边界,也就是单词和空格间的位置
注:前面的* + ?都是贪婪匹配,可以在后面加?使其变成惰性匹配
re=re.findall('abc*?','abcccc') 匹配结果返回[ab]
re模块常用方法
re.findall() 返回所有满足匹配条件的结果,放在列表里
re.search() 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None
re.match() 同search,不过尽在字符串开始处进行匹配
re.split([ab],'abcd') 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
re.sub('\d','abc','str1') 在str1中符合 \d的都换成abc ==str1.replace()
十一:json&pickle模块
eval通常用来执行一个字符串表达式,并返回表达式的值,但是也可以将一个字符串转换成Python对象,有局限,不能转函数等
序列化
把对象(变量)从内存中变成变成一个可存储或传输的过程称之为序列化,在Python中叫做pickling,在其他语言中也叫
serialization,marshalling ,flattening都是一个意思
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,必须xml,但是有一种更好的方法是JSON
因为JSON表示出来就是一个字符串,可以被所有语言读取。也可以方便的存储到磁盘或者通过网络传输。JSON不仅是标准
格式,并且比XML快,可以直接在web页面中读取
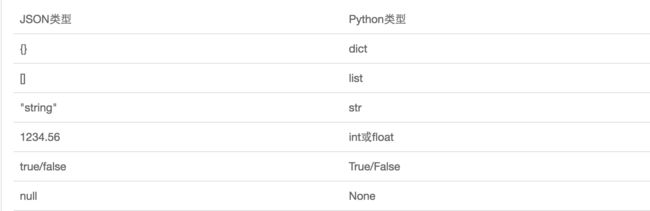
JSON表示的对象就是标准的JavaScript对象,json和Python内置的数据类型对应如下
import json
dic={'name':'xiaod','age':22,'sex':'male'}
print(type(dic))#
j=json.dumps(dic)
print(type(j))#
f=open('1.txt','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()
#-------------------------------反序列化
import json
f=open('序列化对象')
data=json.loads(f.read())# 等价于data=json.load(f) 方法区别
dumps(内容) dump(内容,文件句柄) loads() load(文件句柄)
pickle模块
pickle是Python独有的,不同版本的Python都彼此不兼容,一般用于保存不重要的数据,使用方法和json一样
一般"能用json 就不用pickle"
import pickle
dic={'name':'smalld','age':22,'sex':'male'}
print(type(dic)) #
j=pickle.dumps(dic)
print(type(j))#
f=open('1.txt','wb') #注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #----------------------等价于pickle.dump(dic,f)
f.close()
#-------------------------反序列化
import pickle
f=open('1.txt','rb')
data=pickle.loads(f.read())# 等价于data=pickle.load(f)
print(data['age']) 十二:shielve模块
shielve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写
key 必须为字符串 ,而值是Python所支持的数据类型
import shelve
f = shelve.open('1.txt')
# f['stu1_info']={'name':'smalld','age':'18'}
# f['stu2_info']={'name':'smalld','age':'20'}
# f.close()
print(f.get('stu_info')['age'])十四:logging模块
一:简单应用
import logging
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message') 日志级别从低到高
debug
info
warning(默认)
error
critical
默认的输出格式为:WARNING:root:warning messages
日志级别:用户:信息
二:灵活配置日志级别,日志格式,输入位置
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='/tmp/test.log',
filemode='w')
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')filemode 文件打开方式,默认为a,指定为w
datefmt 指定日期格式
format 指定handler使用的日志显示格式
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
三:logger对象
logger=logging.getLonger([name]) 如果不指定名字,将返回根logger
logger.setLevel( logging.DEBUG) 设置日志的显示级别为debug
fh = logging.FileHandler('test.log') 创建一个handler,用于写入日志文件
ch = logging.StreamHandler() 再创建一个handler,用于输出到控制台
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') 设置输出日志格式
logger.addHandler(fh) #logger对象可以添加多个fh和ch对象
logger.set
logger.addHandler(ch)
logger.debug('logger debug message')