ElasticSearch学习之(六)--kibana-7.3.0-windows安装
一、Kibana概述
Kibana 是一个设计出来用于和 Elasticsearch 一起使用的开源的分析与可视化平台,可以用 kibana 搜索、查看、交互存放在Elasticsearch 索引里的数据,使用各种不同的图表、表格、地图等展示高级数据分析与可视化,基于浏览器的接口使你能快速创建和分享实时展现Elasticsearch查询变化的动态仪表盘,让大量数据变得简单,容易理解。Kibana 是在ElasticSearch 有了相当多的数据之后,进行分析这些数据用的工具。 但是现在还么有数据呀,为什么就要介绍这个工具呢? 因为Kibana 里面有一个叫做 Dev Tools的,可以很方便地以Restful 风格向 ElasticSearch 服务器提交请求,接下来的部分学习,都会使用Kibana 里的这个Dev Tools 来讲解,简单又方便。
二、Kibana下载和安装
1. Kibana官网下载地址:https://www.elastic.co/cn/downloads/kibana

2. 安装其实很简单,和ES一样直接解压即可。然后访问控制台的IP和端口:
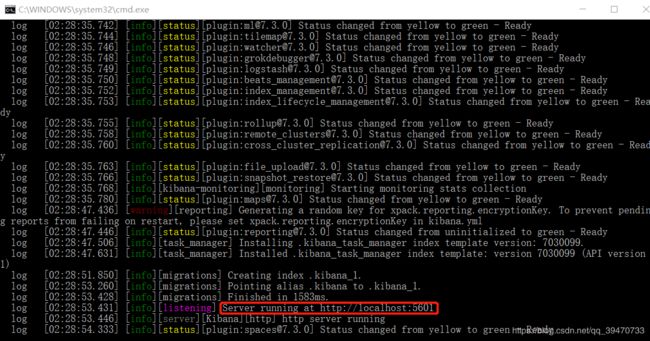
3.访问地址:http://localhost:5601 其中 Dev Tools是专门为ES提供的可视化操作面板。

4. 通过点击执行按钮会出现结果(此处有疑问?)

5. 通过ES的head 插件访问你会发现,本来没有索引的集群里面出现啦索引(此处也有疑问?)

6. 通过对比ES集群的索引和Kibana的查询 结果发现这就是Kibana服务创建的索引。而kibana启动的时候会加载自身配置文件:kibana.yml。通过配置文件的配置ES的集群配置加载相应集群,如果没有配置,那么Kibana 会扫描本地的ES 服务自动注册关联到本地的ES集群。并创建测试索引。
三、kibana的基本操作
1.集群信息查看:
GET /_cat/health?v 集群健康状态查询:green-所有的shard 和 replica 都工作正常;yellow-所有的shard 工作正常,但是部分replica 不能正常提供服务;red-有shard 不能正常提供服务,数据丢失;
GET /_cat/indices?v 集群索引查看;
GET /_cat/nodes?v 集群节点查看;

cat----类似Linux中的cat命令,请注意这个查询返回的不是json,而是以表格的形式展现。
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
要启用表头,加上?v这个参数2. 常用语句
添加数据:
PUT /index_user_index/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}这个URI后面的1代表的是这条数据的ID,也可以字符串。如果不想自己指定ID,可以不传,但是必须使用POST来新增,这样的话Elasticsearch会给这条数据生成一个随机的字符串。
如果想对这条数据进行更新,可以重新请求这个URI,关键是这个ID要指定,然后修改json内容,这样就可以更新这条数据了。
检索数据
根据ID检索到具体某条数据:
GET /index_user_index/employee/1
结果:
{
"_index": "index_user_index",
"_type": "employee",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
}其中_source就是我们存储的json信息,其他字段都很明了。
将HTTP动词由PUT改为GET可以用来检索文档,同样的,可以使用DELETE命令来删除文档,以及使用HEAD指令来检查文档是否存在。如果想更新已存在的文档,只需再次PUT。由此可见,Elasticsearch的作者深谙restful。
最简单的搜索:GET /index_user_index/employee/_search
搜索指定Index下的Type的全部文档,默认每页只显示10条,可以通过size字段改变这个设置,还可以通过from字段,指定位移(默认是从位置0开始)。返回结果的 took字段表示该操作的耗时(单位为毫秒),timed_out字段表示是否超时,hits字段表示命中的记录
简单条件搜索
搜索last_name=Smith的数据:GET /index_user_index/employee/_search?q=last_name:Smith
条件搜索:
GET /index_user_index/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}这段查询和上面的例子是一样的,不过参数从简单的参数变成了一个复杂的json,不过复杂带来的优势就是控制力更强,我们可以对查询做出更多精细的控制。
更复杂的搜索
根据last_name搜索,并且只关心年龄大于30的:
GET /index_user_index/employee/_search
{
"query" : {
"bool": {
"must": {
"match" : {
"last_name" : "smith"
}
},
"filter": {
"range" : {
"age" : { "gt" : 30 }
}
}
}
}
}短语搜索:
GET /index_user_index/employee/_search
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}这个搜索会返回about中包含rock或者climbing的数据,也就是关键词之间默认是or的关系。如果希望精确匹配这个短语呢?
GET /index_user_index/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
}
}就是用match_phrase查询。高亮搜索:
PUT /index_user_index/_mapping/employee
{
"size" : 0,
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}返回结果多了个highlight的部分,默认是用包裹:
GET /index_user_index/employee/_search
{
...
"hits": {
"total": 1,
"max_score": 0.23013961,
"hits": [
{
...
"_score": 0.23013961,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [ "sports", "music" ]
},
"highlight": {
"about": [
"I love to go rock climbing"
]
}
}
]
}
}简单聚合
在聚合之前,需要做些修改,因为Elasticsearch默认是不支持对text类型的数据聚合的,所以需要先开启:
{
"properties": {
"about": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "long"
},
"first_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"interests": {
"type": "text",
"fielddata": true,
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"last_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
类似SQL中的group by,下面是按interests聚合:
GET /index_user_index/employee/_search
{
"size" : 0,
"aggs": {
"all_interests": {
"terms": { "field": "interests" }
}
}
}
结果:
{
...
"hits": { ... },
"aggregations": {
"all_interests": {
"buckets": [
{
"key": "music",
"doc_count": 2
},
{
"key": "forestry",
"doc_count": 1
},
{
"key": "sports",
"doc_count": 1
}
]
}
}
}还可以过滤后再聚合:
GET /index_user_index/employee/_search
{
"size" : 0,
"query": {
"match": {
"last_name": "smith"
}
},
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
}
}
}
}
结果:
...
"all_interests": {
"buckets": [
{
"key": "music",
"doc_count": 2
},
{
"key": "sports",
"doc_count": 1
}
]
}还可以分级聚合:
GET /index_user_index/employee/_search
{
"size" : 0,
"aggs" : {
"all_interests" : {
"terms" : { "field" : "interests" },
"aggs" : {
"avg_age" : {
"avg" : { "field" : "age" }
}
}
}
}
}
结果:
"all_interests": {
"buckets": [
{
"key": "music",
"doc_count": 2,
"avg_age": {
"value": 28.5
}
},
{
"key": "forestry",
"doc_count": 1,
"avg_age": {
"value": 35
}
},
{
"key": "sports",
"doc_count": 1,
"avg_age": {
"value": 25
}
}
]
}计数:
GET /_count
{
"query": {
"match_all": {}
}
}
结果:
{
"count": 12,
"_shards": {
"total": 20,
"successful": 20,
"skipped": 0,
"failed": 0
}
}当然可以对某个Type计数:
GET /index_user_index/employee/_count
{
"query": {
"last_name" : "Smith"
}
}
结果:
{
"count": 2,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
}
}如有披露或问题欢迎留言或者入群探讨
