ElasticSearch常用查询
Elasticsearch
一个基于Lucene的搜索服务器,分布式、高扩展、高实时,能对大量数据搜索、分析和探索。实现原理主要分为以下几个步骤,首先用户将数据提交到Elastic Search 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
可以使用 Kibana 来搜索,查看存储在 Elasticsearch 索引中的数据并与之交互。
注:term查询时,查询内容不分词,直接进行匹配。match查询要分词后匹配。eg:content内容为”北京有天安门“,现将”北京天安门“与content进行匹配查询,term查询过程中将直接用北京天安门进行匹配,返回结果为空;match匹配将”北京“和”天安门“与content进行匹配,结果不为空。
具体事例
启动elasticSearch、启动kibana,端口访问。
以下事例包括-----创建索引库、创建测试数据、term查询、match查询、match_phrase查询、match_phrase_prefix查询、多字段匹配、range查询、前缀查询、模糊查询、value查询、多ID查询、组合过滤、高亮以及多字段高亮。
创建索引库
PUT /my_search
{
"mappings": {
"article":{
"properties": {
"content":{
"type": "text"
},
"email":{
"type": "keyword"
},
"pub_time":{
"type": "date"
},
"title":{
"type": "text"
},
"type":{
"type": "keyword"
},
"words":{
"type": "long"
}
}
}
}
}创建测试数据
POST /my_search/article/1
{
"title":"hello word!",
"content":"hello 你好,世界!",
"email":"[email protected]",
"words":1000,
"pub_time":"2019-09-24",
"type":"IT"
}
POST /my_search/article/2
{
"title":"2号测试",
"content":"我爱中华人民共和国",
"email":"[email protected]",
"words":5000,
"pub_time":"2019-10-24",
"type":"人文"
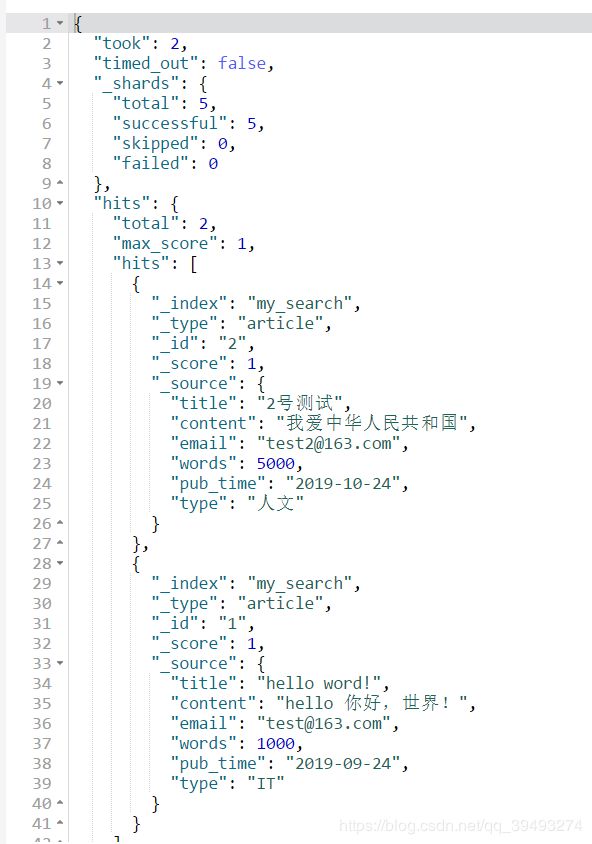
}term查询、精确匹配
GET my_search/_search
{
"query": {
"term": {
"type": "人文"
}
}
}结果为my_search/article/2

match查询、分词
GET my_search/_search
{
"query": {
"match": {
"content": {
"query": "世界啊",
"operator": "or"
}
}
}
}结果为my_search/article/1

match_phrase查询、词项顺序需一致
GET my_search/_search
{
"query": {
"match_phrase": {
"content": "hello你好"
}
}
}结果为my_search/article/1
GET my_search/_search
{
"query": {
"match_phrase": {
"content": "你好hello"
}
}
}词项顺序替换后,结果为空
match_phrase_prefix查询,最后一个词项、前缀匹配
GET my_search/_search
{
"query": {
"match_phrase_prefix": {
"content": "中华 人民"
}
}
}结果为my_search/article/2
多字段匹配
GET my_search/_search
{
"query": {
"multi_match": {
"query": "你好",
"fields": ["title", "content"]
}
}
}
结果为my_search/article/1
多条件精确匹配
GET my_search/_search
{
"query": {
"terms": {
"type": [
"IT",
"人文"
]
}
}
}结果为my_search/article/1和my_search/article/2
range查询(gt 大于 gte大于等于 lt小于 lte小于等于)
GET my_search/_search
{
"query": {
"range": {
"words": {
"gt": 1000,
"lte": 5000
}
}
}
}结果为my_search/article/2
range查询日期
GET my_search/_search
{
"query": {
"range": {
"pub_time": {
"gte": "2019-9-24",
"lte": "2019-9-25",
"format": "yyyy-MM-dd"
}
}
}
}结果为my_search/article/1
前缀查询
GET my_search/_search
{
"query": {
"prefix": {
"title": "hello"
}
}
}结果为my_search/article/1
模糊查询
GET my_search/_search
{
"query": {
"fuzzy": {
"title":"helo"
}
}
}
结果为my_search/article/1
value查询
GET my_search/_search
{
"query": {
"type":{
"value":"article"
}
}
}结果为my_search/article/1和my_search/article/2
多ID查询
GET my_search/_search
{
"query": {
"ids":{
"type":"article",
"values": ["1", "2"]
}
}
}结果为my_search/article/1和my_search/article/2
GET my_search/_search
{
"query": {
"ids":{
"type":"article",
"values": ["1", "3"]
}
}
}
结果为my_search/article/1
组合过滤
must:全部为真则为真;should:至少一个为真则为真;must_not:全部为假则为真。
minimum_should_match:指定should条件中至少几个为真,默认为1。
GET my_search/_search
{
"query": {
"bool": {
"minimum_should_match": 1,
"must": [
{"match": {
"title": "hello"
}}
],
"should": [
{"match": {
"title": "AA"
}},
{"match":{
"title":"hello"
}
}
],
"must_not": [
{"range": {
"words": {
"gte": 10000
}
}}
]
}
}
}结果为my_search/article/1
高亮
eg:将标题中含“hello”的字段高亮展示
GET my_search/_search
{
"query": {
"match": {
"title": "hello"
}
},
"highlight": {
"fields": {
"title": {
"pre_tags":[""],
"post_tags":["结果

多字段查询
require_field_match设置为false,搜索title时,同时content也高亮。
GET my_search/_search
{
"query": {
"match": {
"title": "hello"
}
},
"highlight": {
"require_field_match":false,
"fields": {
"title": {},
"content": {}
}
}
}结果

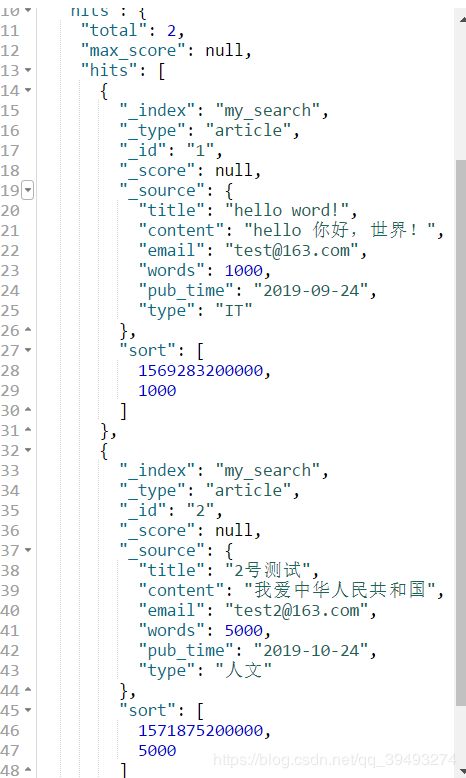
排序
GET my_search/_search
{
"sort": [
{
"_score": {
"order": "asc"
}
}
]
}结果

GET my_search/_search
{
"sort": [
{
"pub_time": {
"order": "asc"
}
},
{
"words": {
"order": "asc"
}
}
]
}结果