小白科研笔记:简析图神经网络收敛性的理论证明
1. 前言
这篇博客主要简析一篇ICLR2020的论文What Graph Neural Network Cannot Learn: Depth vs Width。这篇论文是很有理论深度的。不过这篇博客只是一个导读哈。想借研究这篇论文的时间,打一打图神经网络的理论基础。因为我比较关心图神经网络在点云处理方面的研究,所以对文章的讨论我会以点云处理来举例子。有关图神经网络处理点云的论文可以参考我之前的几篇博客。
2. 图神经网络结构
首先解释一些符号。图神经网络的输入是图类数据。图可以表示为 G = ( V , E ) G=(V,E) G=(V,E)。 n = ∣ V ∣ n=\vert V \vert n=∣V∣表示图中节点的个数。在图 G G G中,使用 v i v_i vi表示第 i i i个节点。 V V V就是所有节点的集合。在点云中, v i v_i vi就可以理解为第 i i i个点的三维坐标。记 e i ← j e_{i\leftarrow j} ei←j表示从 v j v_j vj到 v i v_i vi的边。如果 e i ← j ∈ E e_{i\leftarrow j} \in E ei←j∈E,说明这条边是存在的,此外 e j ← i ∈ E e_{j\leftarrow i} \in E ej←i∈E,即一般讨论的图都是双向的。对于 v i v_i vi来说, d e g i deg_i degi表示该节点的度,即该节点边的个数。 Δ \Delta Δ记为图 G G G中 max ( d e g i ) , ∀ v i ∈ V \max(deg_i), \forall v_i \in V max(degi),∀vi∈V。为了更好的理解图这个数据结构,可以看看这篇归纳笔记。记 a i a_i ai表示第 i i i个节点的特征(比如颜色,法线,雷达强度等)。在一堆点云中,边是怎样建立的呢?直觉是目标点的特征跟他近邻点的特征相关,所以对于点云来说,边是根据近邻关系建立。具体建立方式有几种,一是KNN建立,二是在规定半径范围内建立,三是启发式采样建立(比如最远点采样)。
在这篇论文中,作者用 GNN m p n \text{GNN}_{mp}^n GNNmpn表示图神经网络的运算过程。 GNN \text{GNN} GNN就是Graph Neural Network缩写。 m p mp mp含义是message passing,译为中文就是消息传播。在图神经网络中,目标节点的特征是根据它邻近节点的特征计算而来。举个不恰当的例子,三人成虎。把皇上当作一个节点。他的三位大臣当作邻近节点。三个大臣对皇上说集市有老虎,那么皇上就真相信了集市有老虎。这就是消息传播的过程。 GNN m p n \text{GNN}_{mp}^n GNNmpn中的 n n n表示图神经网络计算的结果是每个节点都会获得一个特征向量。论文中也提及了 GNN m p p \text{GNN}_{mp}^p GNNmpp。在点云应用中,图神经网络用于获取每个点的特征的。所以我们只关心 GNN m p n \text{GNN}_{mp}^n GNNmpn。它的计算方式如下所示:

符号 x i ( l ) x_i^{(l)} xi(l)表示节点 i i i在网络第 l l l层的特征向量。 a i ← j a_{i\leftarrow j} ai←j表示从节点 i i i和节点 j j j的相对关系。在点云处理中 MSG l \text{MSG}_l MSGl相当于是一个多层感知机结构。 m i ← j ( l ) m_{i\leftarrow j}^{(l)} mi←j(l)表示第 l l l层上节点 j j j向节点 i i i传递的消息。对于节点 i i i来说,它的所有邻近节点都会向他发送消息。我们需要一个聚合更新的操作,从这些近邻节点发送的消息中,提取出最有价值的信息,当作节点 i i i在网络第 l l l层的特征向量。在点云处理中, UP l \text{UP}_l UPl表示池化操作,比如最大池化,平均池化,求和等等等。对于 GNN m p n \text{GNN}_{mp}^n GNNmpn来说,每一层都是消息传递和消息聚合的迭代运算。
对于图神经网络 GNN m p n \text{GNN}_{mp}^n GNNmpn而言,网络层数 d d d表示图神经网络的深度。在遍历所有网络层, x i ( l ) x_i^{(l)} xi(l)最大的维度则记为图神经网络的宽度 w w w。比如说有一个五层的图神经网络,这五层的特征维度分别是 [ 1 , 16 , 32 , 64 , 64 , 64 ] [1,16,32,64,64,64] [1,16,32,64,64,64]。那么对于这个图神经网络来说, d = 5 d=5 d=5以及 w = 64 w=64 w=64。
3. 理论收敛的图神经网络
3.1 引言
如果直接说理论证明,就太过于直接了,不方便自己理解。这一节主要做一个过渡。作者写这篇文章的目的是讨论图神经网络在什么情况下可以学到知识(即损失函数收敛),又在什么情况下学不到知识(即损失函数不收敛)。作者意识到影响图神经网络收不收敛的核心要素是网络的深度 d d d和宽度 w w w。为了更好地理解,我们讨论四种情形:
- 一个深度很小且宽度很小的网络,会不会学不到特征呀?
- 一个深度很小但宽度很大的网络,会不会容易过拟合呀?
- 一个深度很大但宽度很小的网络,会不会梯度消失呀?
- 一个深度很大且宽度很大的网络,会不会容易过拟合吗?
上述的原因都是我随便猜的。作者试图从理论的高度,去解释图神经网络收敛和网络的深度 d d d和宽度 w w w的内部联系,进而去指导科研工作者更好地设计图神经网络。OK,那我们就正式开始了。当然啦,作为刚刚入坑的小白,看不懂全部的推导其实并不重要,重要是领会论文的思想,为自己的科研工作做服务。
3.2 计算可达
在论文中,把收敛的网络记为computationally universal。我这里把computationally universal译为计算可达。为什么这么翻译呢?可达一词源于现代控制理论中的状态可达性(不是可达鸭),指的是系统可以达到某一个指定的状态,那个指定的状态就是可达状态。因此,可达指可以到达的状态。computationally universal就是可以通过计算的方式,把输入数据输出成人们指定的结果。以目标检测为例,输入数据是一张图,输出数据是判断这幅图中是否有人/猫/狗等物。计算的载体则是深度学习模型。如果该网络模型经过海量数据学习,可以完全正确地完成图片分类任务,那么这个网络就是计算可达的。当然,你也可以说这个网络是Universal Approximation(万有逼近的)。意思其实差不多。
我再对上述的例子做一个更为抽象的概括。还是以目标检测为例子。给一张图,图像是存在的,这张图中有目标的事情就是也是确定的。这是客观存在的事实,不会以人的主观而转移(颇有哲学意味)。基于上述的客观事实,就铁定存在一个映射 f ( ⋅ ) f(\cdot) f(⋅)。对任何输入的图像 x x x,它都能给出一个正确的分类结果 y y y。我们学习出来的复杂的神经网络,其实可以抽象为一个映射 g ( ⋅ ) g(\cdot) g(⋅)。computationally universal就是指 g ( ⋅ ) g(\cdot) g(⋅)无限接近于 f ( ⋅ ) f(\cdot) f(⋅),即 ∥ f ( ⋅ ) − g ( ⋅ ) ∥ → 0 \Vert f(\cdot) - g(\cdot) \Vert \rightarrow 0 ∥f(⋅)−g(⋅)∥→0。
3.3 收敛条件的证明思路
再讲具体证明之前,咱们先理清一下逻辑:
- 证明的内容: GNN m p n \text{GNN}_{mp}^n GNNmpn在条件 X X X下是计算可达的; X X X是未知的;
然后假设我们是科研人员哈,目前掌握一个这样的已知条件:
- 已知条件:计算模型 LOCAL \text{LOCAL} LOCAL在条件 Y Y Y下是计算可达的; Y Y Y是已知的;
其中 LOCAL \text{LOCAL} LOCAL是一个计算复杂度更高的网络模型,是细胞间传递信息的生物模型。我们会去想,并试图去构造一个条件 Z Z Z,在一个条件 Z Z Z下,让 GNN m p n \text{GNN}_{mp}^n GNNmpn与 LOCAL \text{LOCAL} LOCAL是等价的。这样一来, GNN m p n \text{GNN}_{mp}^n GNNmpn计算可达的条件就是 Y + Z Y+Z Y+Z啦。没错,这就是证明思路。是不是很有意思?总结一下证明思路:
- 第一步:证明在条件 Z Z Z下, GNN m p n \text{GNN}_{mp}^n GNNmpn与 LOCAL \text{LOCAL} LOCAL是等价的
- 第二步:根据 LOCAL \text{LOCAL} LOCAL的性质,获知在满足条件 Y Y Y的情形下, LOCAL \text{LOCAL} LOCAL计算可达
- 第三步:那么 GNN m p n \text{GNN}_{mp}^n GNNmpn计算可达的条件就是 Y + Z Y+Z Y+Z
3.4 计算模型 LOCAL \text{LOCAL} LOCAL
在讲解证明之前,简单了解一下计算模型 LOCAL \text{LOCAL} LOCAL。它的计算过程伪代码如下所示:

模型 LOCAL \text{LOCAL} LOCAL其实很好理解。我们想象一下每一个图中节点都是一个小细胞,这些细胞彼此紧紧地挨在一起。Receive过程就是目标细胞接受周围邻近细胞发出的化学物质;Send过程就是目标细胞向周围邻近细胞发出的化学物质;模型 LOCAL \text{LOCAL} LOCAL就是细胞间信息交互的模型。粗糙地讲,运算符 ALG \text{ALG} ALG表示一个图灵完备的算法。符号 N i ∗ N^*_i Ni∗表示目标点的包含自身的近邻节点集合。 ∗ * ∗指包含自身。总而言之,模型 LOCAL \text{LOCAL} LOCAL是一个理想化的图结构计算模型。
那什么是图灵完备 ( Turing Complete )呢?图灵完备是指机器执行任何其他可编程计算机能够执行计算的能力。简单来说,一切可计算的问题都能计算,这样的虚拟机或者编程语言就叫图灵完备的。好吧,那什么样的问题是可计算的呢?可以参考这篇知乎。
3.5 收敛条件的证明过程
这一节会按照3.3节的证明思路展开。
第一步:证明在条件 Z Z Z下, GNN m p n \text{GNN}_{mp}^n GNNmpn与 LOCAL \text{LOCAL} LOCAL是等价的,条件 Z Z Z是 GNN m p n \text{GNN}_{mp}^n GNNmpn中的 MSG \text{MSG} MSG和 UP \text{UP} UP是图灵完备函数
这个证明的大体思路是两个计算模型相互推导,最后推导出一种等价的形式。
从 GNN m p n \text{GNN}_{mp}^n GNNmpn计算模型推导:
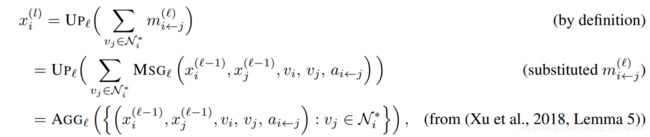
其中 AGG \text{AGG} AGG是聚合函数,可以理解为是 MSG \text{MSG} MSG和 UP \text{UP} UP的融合形式。简简单单地讲, AGG \text{AGG} AGG可以理解为是PointNet的子模块。
从 LOCAL \text{LOCAL} LOCAL计算模型推导:
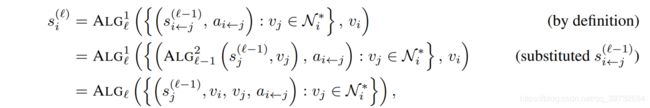
可以发现,两个计算模型能够推导出一种类似的形式。它们等价的充分必要条件就是 AGG \text{AGG} AGG需要和 ALG \text{ALG} ALG等价。作为导读,我来用一种不严谨的语言完成剩下的证明。在讲模型 LOCAL \text{LOCAL} LOCAL的时候, ALG \text{ALG} ALG是一个图灵完备的算法。如果要等价的话, AGG \text{AGG} AGG也应该是图灵完备的。 AGG \text{AGG} AGG由 MSG \text{MSG} MSG和 UP \text{UP} UP复合而成,那么 MSG \text{MSG} MSG和 UP \text{UP} UP也必须是图灵完备的。第一部分就证明完了。
第二步:根据 LOCAL \text{LOCAL} LOCAL的性质,获知在满足条件 Y Y Y的情形下, LOCAL \text{LOCAL} LOCAL计算可达,条件 Y Y Y是深度 d ≥ δ G d \geq \delta_G d≥δG并且宽度 w w w没有界
这是 LOCAL \text{LOCAL} LOCAL的性质,这里不去做证明,直接拿来用。 δ G \delta_G δG指的是图中最长的最短距离(the length of the longest shortest path)。最大的最短距离,看上去有的矛盾哈。先理清楚一个图中任意两节点的最短距离定义shortest path。遍历一个图中所有的点对,计算该点对的距离,把所有点对的距离都由大到小地排列在一起,那么最前头的最短距离就是最大的最短距离。宽度 w w w没有界就是 w w w。
那什么是宽度 w w w没有界呢?就是 w → + ∞ w\rightarrow +\infty w→+∞。宽度 w w w指的是图神经网络中神经元中最大的特征维度。举个例子, w = 64 w=64 w=64,说明有一层的神经元个数是64个。 w → + ∞ w\rightarrow +\infty w→+∞则说明有一层的神经元个数是极其大的。神经元个数越多,网络的表示能力就会越强。当 w → + ∞ w\rightarrow +\infty w→+∞,该网络在理论上是图灵完备的。一个图灵完备的网络对应 LOCAL \text{LOCAL} LOCAL中图灵完备的运算符 ALG \text{ALG} ALG。
深度 d ≥ δ G d \geq \delta_G d≥δG这个条件也可以去解释。当 d ≥ δ G d \geq \delta_G d≥δG,图中任一一个节点都可以接收到图中其他任意节点的信息。当然 d ≥ δ G d \geq \delta_G d≥δG是一个非常非常强的条件。
第三步(结论): GNN m p n \text{GNN}_{mp}^n GNNmpn计算可达的条件是: MSG \text{MSG} MSG和 UP \text{UP} UP是图灵完备函数,且深度 d ≥ δ G d \geq \delta_G d≥δG并且宽度 w w w没有界
把前两步的结果拼起来即可。注意这个结论是一个必要条件(必要条件!):
根据 MSG \text{MSG} MSG和 UP \text{UP} UP是图灵完备函数,且深度 d ≥ δ G d \geq \delta_G d≥δG并且宽度 w w w没有界,可以去得到 GNN m p n \text{GNN}_{mp}^n GNNmpn计算可达。(正确的结论)
但论文可没有下这样的充分条件哦:
GNN m p n \text{GNN}_{mp}^n GNNmpn计算可达一定要 MSG \text{MSG} MSG和 UP \text{UP} UP是图灵完备函数,且深度 d ≥ δ G d \geq \delta_G d≥δG并且宽度 w w w没有界。(错误的结论)
我们着重解释一下这个结论。首先,这个结论只是个理论上的结论。 d ≥ δ G d \geq \delta_G d≥δG是一个非常强的必要条件。它是必要条件哈。满足 d ≥ δ G d \geq \delta_G d≥δG和其他条件,那么 GNN m p n \text{GNN}_{mp}^n GNNmpn计算可达。如果 d < δ G d < \delta_G d<δG, GNN m p n \text{GNN}_{mp}^n GNNmpn也未必是不收敛的。宽度 w w w没有界同样是一个非常强的必要条件。而且从实际角度出发, w → + ∞ w\rightarrow +\infty w→+∞是难以去训练的,需要足够大内存和海量的数据以及充分的训练时间等等。因此,这仅仅是一个理论结论。
4. 理论不收敛的图神经网络
这篇论文后半部分讨论图神经网络不收敛的种种理论条件。根据图神经网络计算可达的条件反过来想,如果 d < δ G d<\delta_G d<δG且 w w w有界,即 w < M w
5. 结束语
说句人话,对我等调参调包炼丹侠(斜杠青年,调参/调包/炼丹,hhh),这篇论文的任何结论都没什么实际意义。这篇论文只是告诉我们一个大家都懂的道理,图结构越复杂,网络的深度和宽度应该设计地越大才好。有人会说,这种道理,我们在炼丹的时候,完全是凭直觉就能掌握的呀。没错,这篇文章是从严谨的数学角度证明了大家司空见惯的直觉是对的,并且尽可能地量化网络收不收敛的条件。它的价值就在这里喵。