案例:通过空气质量指数AQI学习统计分析并进行预测(上)
申明:文章内容是作者自己的学习笔记,教学来源是开课吧讲师梁勇老师。
不要杠,开心学习!
讲师介绍:梁老师 《细说Java》与《Java深入解析》图书作者。一线互联网资深数据分析专家,超过十年软件开发与培训经验。精通Python与Java开发,擅长网络爬虫,数据分析与可视化,机器学习,自然语言处理等技术。曾参与阿里云大学数据分析,机器学习,自然语言处理等课程开发与认证设计,担任阿里云学院导师。
进入正文:
本篇博客会带你学习:
- 数据分析流程
- 特征工程
- 缺失值、异常值、重复值的处理
- 箱线图怎么判断异常值
- 观察散点图、箱型图、箱线图等进行分析
- 两独立样本T检验
用到的库:numpy 、pandas、 matplotlib、 seaborn
让我们开始吧!!!

AQI分析与预测
- 1、AQI 分析与预测
- 1.1 背景信息
- 1.2 学习任务说明
- 1.3 数据集描述
- 2、数据分析流程
- 3、读取数据
- 3.1 导入相关的库
- 3.2 加载数据集
- 4、数据清洗
- 4.1 缺失值
- 4.1.1 缺失值探索
- 4.1.2 缺失值处理
- 4.1.2.1 数据分布
- 4.1.2.2 填充数据
- 4.2 异常值
- 4.2.1 异常值探索
- 4.2.1.1 describe 方法
- 4.2.1.2 3σ
- 4.2.1.3 箱线图
- 箱线图怎么判断异常值?
- IQR
- 4.2.2 异常值处理
- 4.2.2.1 对数转换
- 4.2.2.2 使用边界值替换
- 4.2.2.3 分箱离散化
- 4.3 重复值
- 4.3.1 重复值探索
- 4.3.2 重复值处理
- 5、数据分析
- 5.1 空气质量最好/最差的5个城市
- 5.1.1 最好的5个城市
- 5.1.2 最差的5个城市
- 5.2 全国城市空气质量
- 5.2.1 城市空气质量等统计
- 5.2.2 空气质量指数分布
- 5.3 临海城市是否空气质量优于内陆城市?
- 5.3.1 数量统计
- 5.3.2 分布统计
- 5.3.3 差异检验
- 两独立样本T检验补充笔记:
1、AQI 分析与预测
1.1 背景信息
AQI(空气质量指数),用来衡量空气清洁或者污染的程度。值越小,表示空气质量越好。近年来,因为环境问题,空气质量也越来越受到人们的重视。

1.2 学习任务说明
我们期望能够运用数据分析的相关技术,对全国城市空气质量进行研究和分析,希望能够解决以下疑问:

这里整合用到了之前的一些统计学习相关的内容。
需要回顾学习的可以点击以下内容:
描述性统计分析。
推断统计分析包括参数估计和假设检验两块内容。
线性回归。
1.3 数据集描述
数据集:获取2015年空气质量指数集。该数据集包括全国主要城市的相关数据以及空气质量指数。
数据集百度云链接,提取码:j63l
数据集中字段(列名)详情:

2、数据分析流程
在进行分析前我们先来了解下数据分析的流程:

什么是特征工程?
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。通俗的说就是数据预处理的方式,从源数据当中提取相关数据可以放到模型当中。
通过总结和归纳,目前认为特征工程包括以下方面:
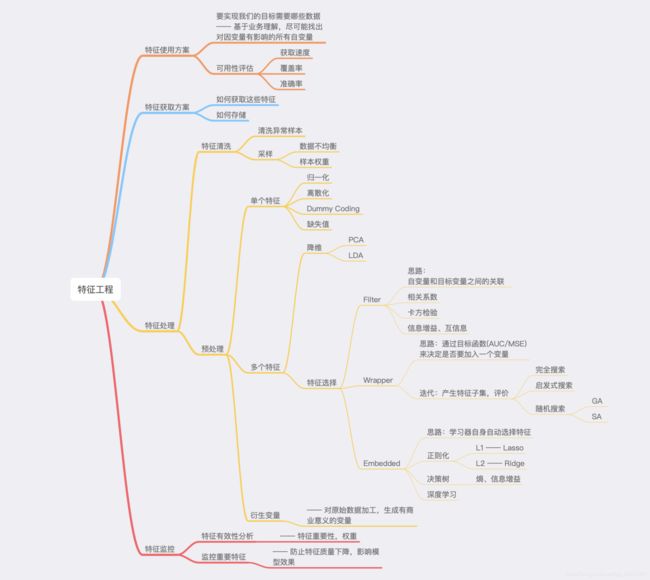
什么是超参数调整?
模型参数通常是有数据来驱动调整。
超参数不需要数据来驱动,而是在训练前或者训练中人为的进行调整的参数。
3、读取数据
3.1 导入相关的库
导入需要的库,同时,进行一些初始化设置。
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import seaborn as sns
import warnings
sns.set(style="darkgrid")
plt.rcParams["font.family"] = "SimHei"
plt.rcParams["axes.unicode_minus"] = False
warnings.filterwarnings("ignore")
warnings.filterwarnings("ignore") python通过调用warnings模块中定义的warn()函数来发出警告。我们可以通过警告过滤器进行控制是否发出警告消息。
“ignore”表示忽略匹配的警告。
3.2 加载数据集
data = pd.read_csv("data.csv")
print(data.shape)
结果:(325, 12)(325行12列的形式)
加载之后,可以使用head / tail / sample等方法查看数据的大致情况。
data.head()
结果:
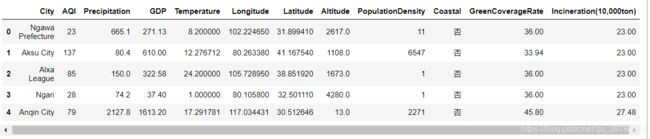
数据集我们大致查看后,现在要来对数据进行清洗的操作:
4、数据清洗
4.1 缺失值
4.1.1 缺失值探索
我们可以使用如下方法查看缺失值:
- info
- isnull
data.info()
结果:
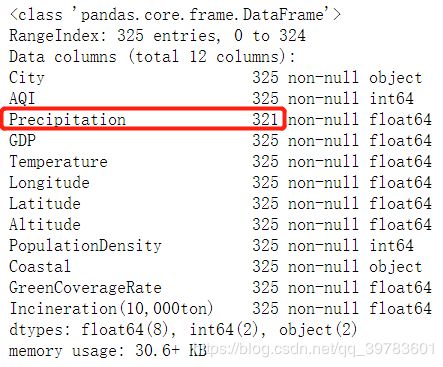
data.isnull().sum(axis=0)
# 用sum 统计每一列有多少个缺失值
结果:
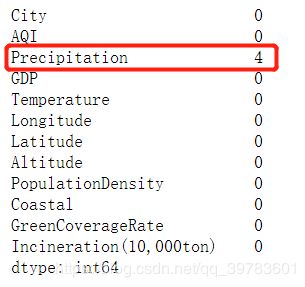
通过查看发现降雨量Precipitation 有4个缺失值。
4.1.2 缺失值处理
对于缺失值,我们可以使用如下的方式处理:
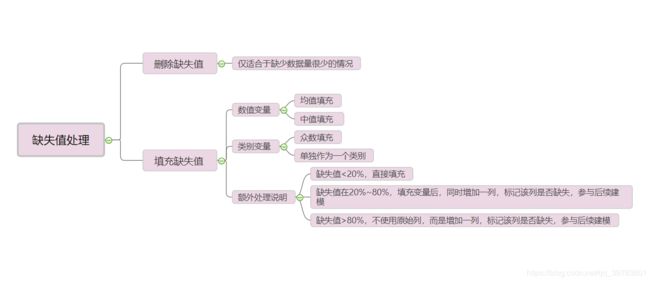
均值填充:
如果是正态分布用均值填充也可以,但是如果是右偏分布就不可以用均值填充了,因为会受到极值的影响。
中值填充:
中位数不太受异常值或者极值的影响。 类别变量中,单独作为一个类别这种方法用的比较多些。
4.1.2.1 数据分布
print(data["Precipitation"].skew())
# skew 查看下偏度信息
sns.distplot(data["Precipitation"].dropna())
skew() 查看下偏度信息
注意:
seaborn不支持空值绘制图形,所以需要使用dropna()将空值剔除掉。
结果:
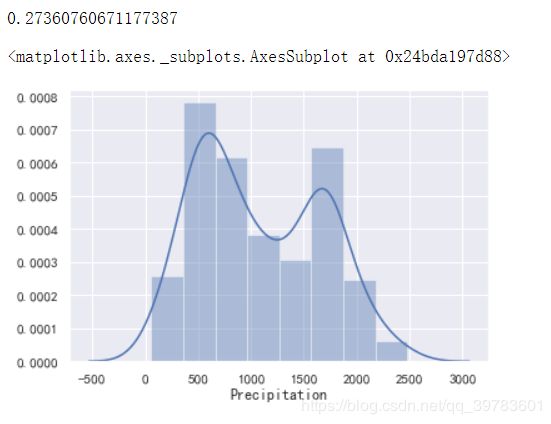
从图中可以看到,分布多少有些右偏,所以我们可以使用中值对其进行一个填充。
4.1.2.2 填充数据
data.fillna({"Precipitation":data["Precipitation"].median()},inplace=True)
data.isnull().sum()
median()中位数
inplace=True对当前对象进行修改
结果:

从图中可以看出,已经填充完成,现在没有缺失值了。
接着我们再来看下有没有异常值。
4.2 异常值
4.2.1 异常值探索
发现异常值:

4.2.1.1 describe 方法
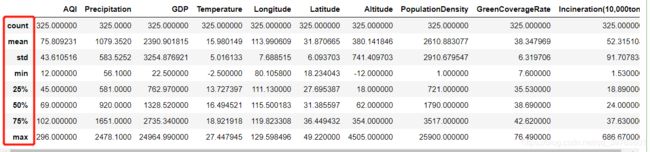
调用DataFrame对象的describe方法,可以显示数据的统计信息,不过,此种方法仅能作为一种简单的异常探索方式。
data.describe()
4.2.1.2 3σ
根据正态分布的特性,我们可以将3σ之外的数据,视为异常值。
我们以GDP为例,首先绘制GDP的分布。
sns.distplot(data["GDP"])
print(data["GDP"].skew())
结果:
3.7614282419643033
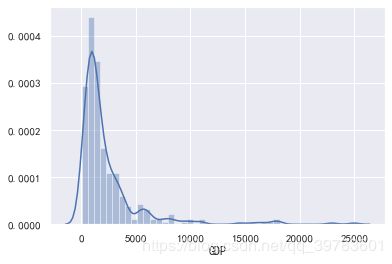
可以看出,该数据呈现严重的右偏分布。也就是存在很多极大的异常值,我们可以获取这些异常值。
#均值mean,标准差std
mean,std = data["GDP"].mean(),data["GDP"].std()
lower,upper = mean - 3 * std,mean + 3 * std
print("均值:",mean)
print("标准差:",std)
print("下限:",lower)
print("上限:",upper)
# 拿出均值加减3倍标准差后得出的异常值
data["GDP"][(data["GDP"] < lower) | (data["GDP"] > upper )]
代码解析:
lower,upper = mean - 3 * std,mean + 3 * std 算出上限和下限
data["GDP"][(data["GDP"] < lower) | (data["GDP"] > upper )] 拿出上限和下限之外的值,即3σ。
结果:

4.2.1.3 箱线图
箱线图是一种常见的异常检测方式。
箱形图可以用来观察数据整体的分布情况,利用中位数,25/%分位数,75/%分位数,上边界,下边界等统计量来来描述数据的整体分布情况。通过计算这些统计量,生成一个箱体图,箱体包含了大部分的正常数据,而在箱体上边界和下边界之外的,就是异常数据。
画箱线图:
sns.boxplot(data=data["GDP"])
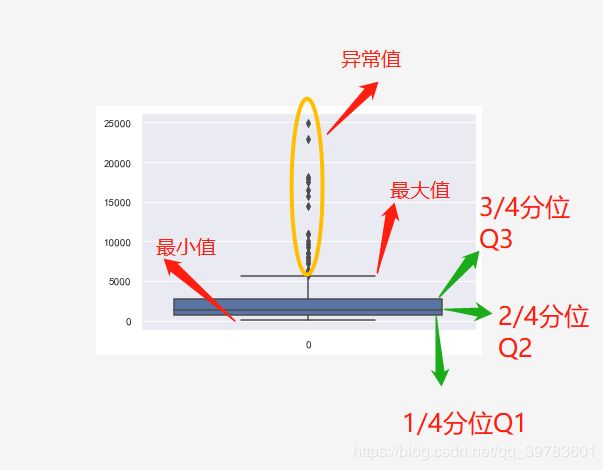

注意:
箱线图中的上限(最大值)和下限(最小值)不是数据集中的最大值和最小值,指的是合理范围之内的最大值和最小值,合理范围是什么呢?
Q1-1.5IQR > 合理范围 > Q3+1.5IQR
其中上下边界的计算公式如下:

箱线图怎么判断异常值?
如果一个异常值比Q1-1.5IQR还要小的话,或者它比Q3+1.5IQR还要大的话,就把这样的值看成异常值。(超出上边界或下边界的值就是异常值)
Q1-1.5IQR > 异常值
异常值 > Q3+1.5IQR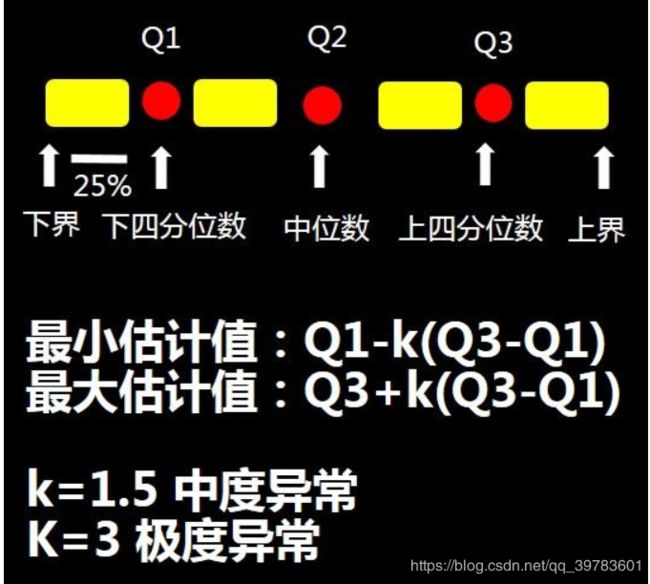
IQR
什么是IQR?
IQR可以用来识别异常值。
IQR是两个四分位之间的间距。
IQR = Q3 − Q1
4.2.2 异常值处理
对于异常值,我们可以采用以下方式进行处理:

4.2.2.1 对数转换
如果数据中存在较大的异常值,我们可以通过取对数来进行转换,这样可以得到一定的缓解。
例如,GDP变量呈现右偏分布,我们可以进行取对数转换。
# 创建子图,一行两列两个图
fig,ax = plt.subplots(1,2)
fig.set_size_inches(15,5)
# ax指的是子绘图的对象在那个位置进行绘制
sns.distplot(data["GDP"],ax=ax[0])
sns.distplot(np.log(data["GDP"]),ax=ax[1])
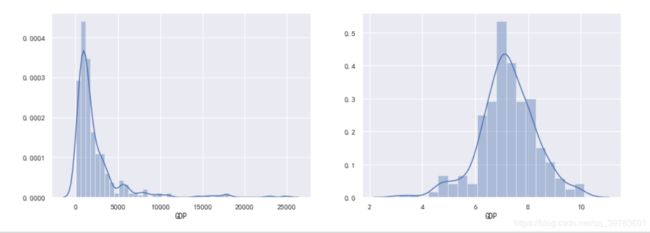
左侧的子图是严重的右偏分布,在取对数后基本上趋于正态分布。

4.2.2.2 使用边界值替换
我们可以对异常值进行截断处理,即使用临界值替换异常值。
例如,在3σ与箱线图中,就可以这样来处理。
4.2.2.3 分箱离散化
有时候,特征对目标值存在一定的影响,但是,这种影响可能未必是线性的增加,此时,我们就可以使用分箱方式,对特征进行离散化处理。
4.3 重复值
4.3.1 重复值探索
使用duplicate检查重复值。
可配合keep参数进行调整。
# 发现重复值
print(data.duplicated().sum())
# 查看哪些记录出现了重复值
data[data.duplicated(keep=False)]
duplicated( )函数:df.duplicated(subset=None, keep=‘first’/‘last’/False)
参数解析:
subset:对应值是列名,表示只考虑写的列,将列对应值相同的行进行去重,默认值None,即考虑所有列;
keep='first/last/False’:first:默认值,除了第一次出现外,其余相同的被标记为重复;last:除了最后一次出现外,其余相同的被标记为重复;False:即所有相同的都被标记为重复;
使用duplicated()函数检测标记Series中的值、DataFrame中的记录行是否是重复,重复为True,不重复为False。
结果:
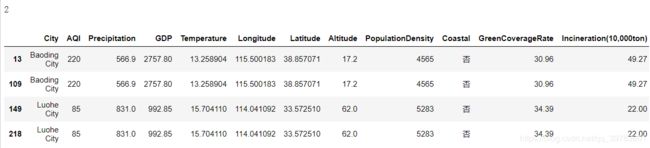
4.3.2 重复值处理
重复值对数据分析通常没有作用,直接删除即可。
data.drop_duplicates(inplace=True)
data.duplicated().sum()
对重复值进行删除后,现在结果查看重复值为0。
数据处理后,现在我们进行一个简单的分析。
5、数据分析
5.1 空气质量最好/最差的5个城市
5.1.1 最好的5个城市
t=data[["City","AQI"]].sort_values("AQI")
display(t.iloc[:5])
plt.xticks(rotation=45)
sns.barplot(x="City",y="AQI",data=t.iloc[:5])

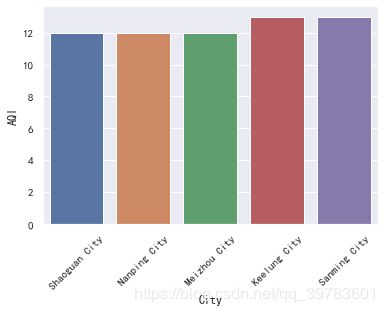
我们发现,空气质量最好的5个城市为:韶关市,南平市,梅州市,基隆市,三明市。
5.1.2 最差的5个城市
display(t.iloc[-5:])
plt.xticks(rotation=45)
sns.barplot(x="City",y="AQI",data=t.iloc[-5:])

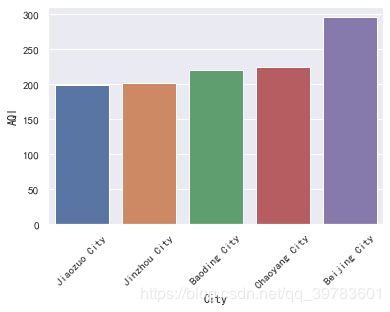
空气最差的5个城市分别为:北京市,朝阳市,保定市,锦州市,焦作市。
5.2 全国城市空气质量
5.2.1 城市空气质量等统计
对于AQI,可以对空气质量进行等级划分,划分标准如下表所示:

根据核标准,我们来统计下,全国空气质量每个等级的数量。
# 编写函数,将AQI转换为对应的等级
def value_to_level(AQI):
if AQI >= 0 and AQI <= 50:
return "一级"
elif AQI >=51 and AQI <=100:
return "二级"
elif AQI >=101 and AQI <=150:
return "三级"
elif AQI >=151 and AQI <=200:
return "四级"
elif AQI >=201 and AQI <=300:
return "五级"
else:
return "六级"
level = data["AQI"].apply(value_to_level)
display(level.value_counts())
sns.countplot(x=level,order=["一级","二级","三级","四级","五级","六级"])
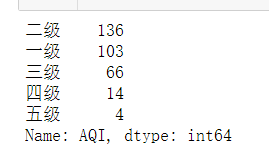
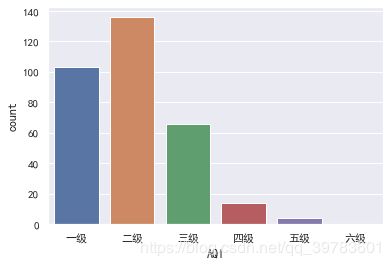
可见,我们城市的空气质量主要以一级(优)与二级(良)为主,三级(轻度污染)占一部分,更高污染的城市占少数。
5.2.2 空气质量指数分布
我们来绘制一下全国各城市的空气质量指数分布图。
sns.scatterplot(x="Longitude",y="Latitude",hue="AQI",palette=plt.cm.RdYlGn_r,data=data)
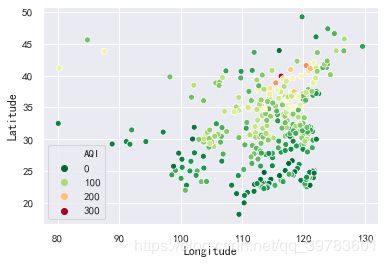
从结果图中我们可以看到,从大致的地理位置上看,西部城市好于东部城市,南部城市好于北部城市。
5.3 临海城市是否空气质量优于内陆城市?
5.3.1 数量统计
我们首先来统计下临海城市与内陆城市的数量。
display(data["Coastal"].value_counts())
sns.countplot(x="Coastal",data=data)

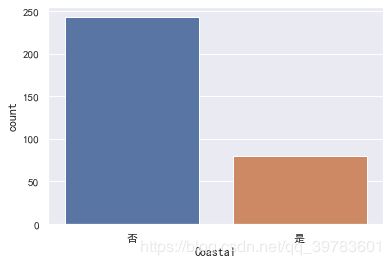
内陆城市明显多于沿海城市。
5.3.2 分布统计
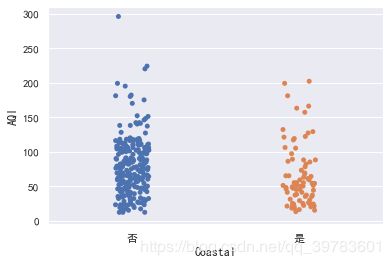
我们来观察下内陆城市和沿海城市的散点分布。
sns.stripplot(x="Coastal",y="AQI",data=data)
sns.swarmplot(x="Coastal",y="AQI",data=data)
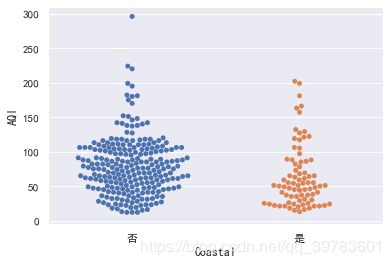
然后我们再来分组计算空气质量的均值。
display(data.groupby("Coastal")["AQI"].mean())
sns.barplot(x="Coastal",y="AQI",data=data)
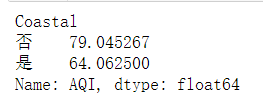

以上柱形图中的两条线指的是什么?
指的是置信区间,默认为95%的置信度,总体均值在95%的概率下是不会超过线(置信区间)的。
在柱形图中,仅显示了内陆城市和沿海城市空气质量指数(AQI)的均值对比,我们可以使用箱线图来显示更多的信息。
sns.boxplot(x="Coastal",y="AQI",data=data)
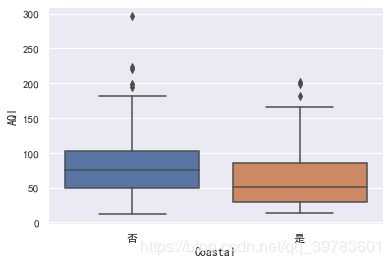
我们还可以绘制小提琴图,除了能够展示箱线图的信息外,还能呈现出分布的密度。
sns.violinplot(x="Coastal",y="AQI",data=data)
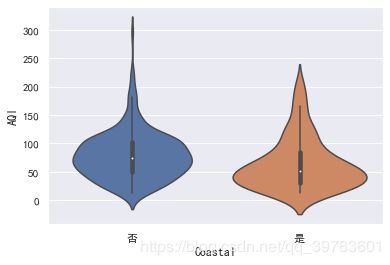
我们还可以将散点与箱线图或小提琴图结合在一起进行绘制,下面以小提琴图为例。
sns.violinplot(x="Coastal",y="AQI",data=data,inner=None)
sns.swarmplot(x="Coastal",y="AQI",color="g",data=data)
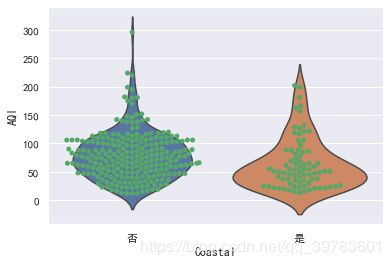
从以上信息(样本)数据中可以得出沿海城市的空气质量要比内陆城市的好很多,但是这不能代表全国空气质量检测的最终数据,因为我们目前查看的就是样本中几百条数据的信息,我们还没有总体上去比较沿海和内陆城市对于空气质量的差别。
5.3.3 差异检验
这里,我们可以进行两样本 t 检验,来查看临海城市与内陆城市的均值差异是否显著。
两样本t检验:
是指两个独立的样本,又称为成组t检验,根据样本数据对两个样本来自的两个独立总体的均值是否有显著差异进行判断。
检验两样本背后的均值是否一致:
原假设:均值一致
备择假设:均值不一致
from scipy import stats
coastal = data[data["Coastal"]=="是"]["AQI"]
inland = data[data["Coastal"]=="否"]["AQI"]
#进行方差齐性检验,为后续的两样本t检验服务
stats.levene(coastal,inland)
stats.levene利用levene检验,检验两总体是否具有方差齐性。
结果:
![]()
结果中的统计量我们不用看,我们只需要看p值,从p值可以看到是有76%是支持原假设的,也就是方差是齐性的。
# 进行两样本t检验,注意:两样本的方差相同与不相同 ,取得的结果是不同的。
r = stats.ttest_ind(coastal,inland,equal_var=True)
print(r)
p = stats.t.sf(r.statistic,df=len(coastal)+len(inland)-2)
print(p)
equal_var=True 表示方差是相等的。
结果:有99%的几率可以认为沿海城市的空气质量普遍好于内陆城市。

两独立样本T检验补充笔记:
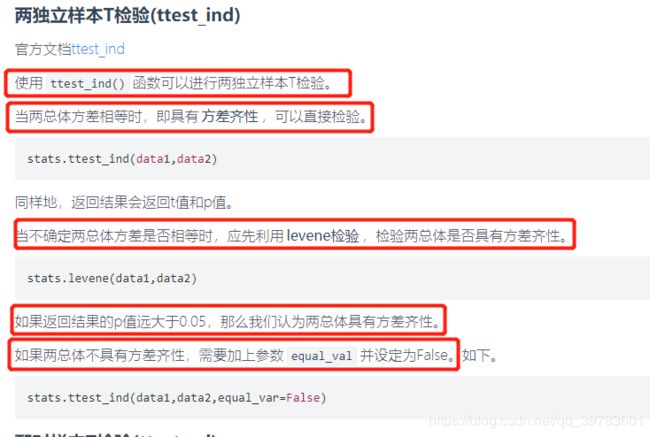
使用边界值替换与分箱离散化在AQI分析与预测下部分会详细讲解。
期待AQI 分析与预测下部分的学习吧,包括散点图矩阵、相关系数等。

引用相关学习链接:
https://www.jianshu.com/p/7066558bd386
https://www.cnblogs.com/IvyWong/p/10134012.html
未完待续!!!
案例:通过空气质量指数AQI学习统计分析并进行预测(下)