PPO算法OpenAI论文大致翻译
近年来,涌现出一些用于带有神经网络函数逼近器的强化学习的算法,主要有DQL,“vanilla”策略梯度算法和信任域/自然策略梯度算法。然而,这些算法在广泛性、数据效率和稳定性方面仍存在很大的上升空间。Q-learning不能很好地解决简单问题并且算法的理解性很差;“vanilla”策略梯度算法数据效率低,稳健性差;TRPO算法相对复杂且对包含噪声或者参数共享的结构不兼容。
因此急需提出一种新的算法,取前人之长,补前人之短。OpenAI最新提出的近端策略优化算法(PPO)既拥有TRPO算法数据效率高、训练结果可靠的优势,而且只进行一阶优化,大大降低了算法复杂度。PPO算法的目标函数新颖,带有截断概率比,这可以使策略的表现形成悲观估计。为了优化策略,PPO算法轮流进行从策略中数据采样和优化目标函数的工作。
PPO算法提出的背景
1.策略梯度算法
策略梯度算法的原理是大致是首先对策略梯度进行估计,然后把该估计代入一个随机上升算法中。最常见的梯度估计形式如下:

其中,![]() 代表随机策略,
代表随机策略,![]() 代表优势函数在时间步长为 t 时的估计。期望
代表优势函数在时间步长为 t 时的估计。期望![]() 表示有限批样本的经验平均值。构建目标函数,使目标函数的梯度为该策略梯度估计g,这就是利用自动微分软件进行算法实现的工作原理。对下面的目标函数进行微分可得估计g。
表示有限批样本的经验平均值。构建目标函数,使目标函数的梯度为该策略梯度估计g,这就是利用自动微分软件进行算法实现的工作原理。对下面的目标函数进行微分可得估计g。
![]()
尽管人们推荐对该损失![]() 用相同的轨迹进行多步优化,但是这么做并没有被证明是合理的。经验上可知,这种做法经常会造成破坏性的大范围策略更新。
用相同的轨迹进行多步优化,但是这么做并没有被证明是合理的。经验上可知,这种做法经常会造成破坏性的大范围策略更新。
2.TRPO算法
对于TRPO算法,在与策略更新的大小有关的约束条件下,目标函数被最大化。也就是:
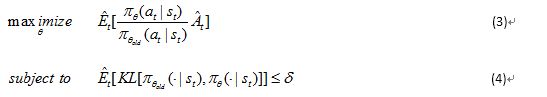
这里,![]() 表示策略参数更新之前的向量。在完成对目标的线性近似和对约束条件的二次近似后,该问题可以用conjugate gradient algorithm近似解决。
表示策略参数更新之前的向量。在完成对目标的线性近似和对约束条件的二次近似后,该问题可以用conjugate gradient algorithm近似解决。
此观点证明,TRPO推荐使用惩罚代替约束条件是合理可行的。即解决非约束的优化问题:
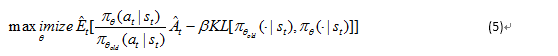
这是因为代理目标能够形成策略表现的下限。TRPO使用一个严格的约束而不是惩罚,因为选择![]() 的值很困难。
的值很困难。![]() 需要在不同的问题中都表现良好,或者在特征随着学习的东西不同而变化的简单问题中表现良好。因此,为了实现目标:获得一个能够达到TRPO算法改进效果的一阶算法,实验表明,仅仅选择一个固定的惩罚系数
需要在不同的问题中都表现良好,或者在特征随着学习的东西不同而变化的简单问题中表现良好。因此,为了实现目标:获得一个能够达到TRPO算法改进效果的一阶算法,实验表明,仅仅选择一个固定的惩罚系数![]() 并用SGD优化被惩罚了的目标式子是不够的。还需要进行修改。
并用SGD优化被惩罚了的目标式子是不够的。还需要进行修改。
3.截断代理目标
令![]() 表示概率比
表示概率比![]() ,所以
,所以![]() 。TRPO最大化一个代理目标:
。TRPO最大化一个代理目标:

上标CPI表示conservative policy iteration ,。因为没有约束条件,目标![]() 的最大值将导致过度的大范围策略更新。所以,我们考虑怎么修改目标来惩罚让概率比
的最大值将导致过度的大范围策略更新。所以,我们考虑怎么修改目标来惩罚让概率比![]() 远离1的策略的变化。
远离1的策略的变化。
我们提出的主要的目标如下:
![]()
这里![]() 是超参数,即,
是超参数,即,![]() 。这个目标的组成如下。里面的第一项是
。这个目标的组成如下。里面的第一项是![]() ,第二项是
,第二项是![]() , 修改了代理目标通过截断概率比,这消除了把概率比
, 修改了代理目标通过截断概率比,这消除了把概率比![]() 移到区间
移到区间![]() 外面的激励。最后我们取截断目标和未截断目标的最小值,所以最后的目标是未截断目标的下限。通过这种方案,我们仅仅忽略当概率比使目标改进时概率比的变化,并且我们可以考虑概率比当它使目标变坏时。我们注意到在old附近,对一阶来说,
外面的激励。最后我们取截断目标和未截断目标的最小值,所以最后的目标是未截断目标的下限。通过这种方案,我们仅仅忽略当概率比使目标改进时概率比的变化,并且我们可以考虑概率比当它使目标变坏时。我们注意到在old附近,对一阶来说,![]() 。然鹅,两者不等,当远离old时。
。然鹅,两者不等,当远离old时。
4. 可变化的KL惩罚系数
另一种方法,这可以作为截断代理目标的代替方法,是对KL divergence进行惩罚,调整惩罚系数这样可以实现一些每次策略更新时KLdivergence的目标值。在我们的实验中,我们发现,KL惩罚的表现不如截断代理目标,然鹅我们这里介绍它是因为它是一个非常重要的基础。
在最简单的算法例程中,我们在每次策略更新运行下列步骤:
使用几个时期的最小批SGD优化KL惩罚目标
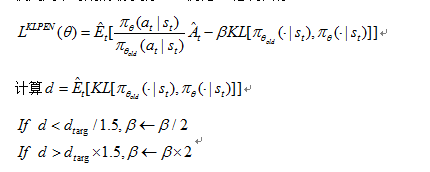
被更新的![]() 用来下次的策略更新。用这个方案,我们偶尔会看到策略更新到KL divergence 和d非常非常不一样的地方,然鹅,这些情况是罕见的,
用来下次的策略更新。用这个方案,我们偶尔会看到策略更新到KL divergence 和d非常非常不一样的地方,然鹅,这些情况是罕见的,![]() 会很快调整。参数1.5和2是通过试验得到的,但是该算法对此并不敏感。
会很快调整。参数1.5和2是通过试验得到的,但是该算法对此并不敏感。![]() 的初始值是另一个超参数,但是在实践中并不重要因为算法会很快对他进行调整。
的初始值是另一个超参数,但是在实践中并不重要因为算法会很快对他进行调整。
5.PPO算法
通过对典型策略梯度实现进行一个微小的改变,我们可以计算并微分前面部分的代理损失。对于使用自动微分的实现,只需要构建损失![]() ,并在此目标上执行随机梯度上升的多个步骤。
,并在此目标上执行随机梯度上升的多个步骤。
大多数计算方差减少的优势函数估计的技术使用一个学习状态值的函数![]() , 例如一般性优势估计或者有界估计。如果使用一个共享策略和值函数参数的神经网络结构,我们必须用一个结合策略代理和值函数误差项的损失函数。这个目标函数能被进一步增强通过加入熵奖励以确保充分探索。结合这些项,我们得到目标如下:该目标在每轮回合中被最大化。
, 例如一般性优势估计或者有界估计。如果使用一个共享策略和值函数参数的神经网络结构,我们必须用一个结合策略代理和值函数误差项的损失函数。这个目标函数能被进一步增强通过加入熵奖励以确保充分探索。结合这些项,我们得到目标如下:该目标在每轮回合中被最大化。
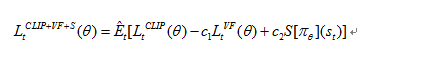
![]()
一个适用于RNNs的策略梯度实现方式是,运行T个时间步长的策略(T远小于回合长度),并用收集到的样本进行更新。这个方法需要一个不超过时间步长T的优势估计,即:
![]()
t代表[0,T]范围内的时间,在给定长度-T轨迹段内。一般化这个估计,我们可以使用截断形式的广义优势估计,当![]() 时,会减少成式子:
时,会减少成式子:
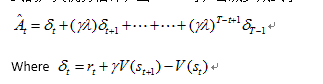
一个使用固定长度轨迹段的PPO算法如下所示:
每次迭代,每个N (并行)actor都收集T时间步长的数据。然后我们在这些NT时间步长的数据上构建代理损失,并用minibatch SGD对其进行优化K时期。
PPO应用
在PPO算法应用中,为了代表策略,我们用一个全连接MLP,带有两个隐层,64个神经元和tanh非线性核函数,输出是符合高斯分布的平均值,具有可变的标准偏差。我们没有共享策略和值函数之间的参数,也没有使用熵奖励。