Self-supervised Learning of Motion Capture阅读笔记
备注:
1.作者
Hsiao-Yu Fish Tung,Katerina Fragkiadaki 卡耐基梅隆大学
一、概述
1. abstract
(1) 跟直接优化mesh and skeleton 的参数不一样的是,我们通过优化网络的权重来预测一个 monocular RGB video中的3D shape and skeleton 的配置;
(2) 模型采用end-to-end framework;
(3) 模型训练联合使用 strong supervision from synthetic(合成的) data 和 self supervision from differentiable rendering of skeleton keypoints, dense 3D mesh motion , human-background segmentation;
(4) 联合使用supervised learning 和 test-time optimization,监督学习在合适的时间对模型参数进行初始化,确保测试时候 good pose and surface initialization;
(5) 优点:self-supervision by BP through differentiable rendering allows(unsupervised) adaptation of model to the test data,and offer much tighter fit than a pretrained fixed model.
2 .应用方向
对于非设定实验场中单视觉的人体以及其运动理解是很重要的,可有以下应用场景:
automated gym, dancing teacher , rehabilitation guidance, patient monitoringand safer human-robot interactions;
对于影视行业的 character motion capture(MOCAP)and retargeting (that still require tedious labor effort of artists to achieve the disired accuracy ,or the use espensive multi-camera setups and green-scerrn backgrounds.)
二、网络架构
1. 主旨描述
(1)提出一个基于monocular video的运动捕捉的网络模型,学习将图片序列映射到相应的3D 网格序列;
(2)使用合成的渲染模型进行strong supervision;以及从3D 到2D的渲染模型 并对应于2D监测点的真实单目视频进行 self-supervision;
(3)self-supervision利用 2D body joint detection ,2D figure-ground segmentation, 2D optical flow;除此之外,2D身体关节标注更易获取,以及optical flow 能容易的从合成数据泛化到真实数据;
(4)跟以往的基于motion capture work进行优化的不同点,我们使用 differentiable warping and differentiable camera project for optical flow and segmantation losses ;这些方法的综合运用有利于进行end-to-end with BP的学习;
(5)使用SMPL 作为 dense human 3D mesh model;我们的任务是对 渲染过程进行 逆向工程操作,并且预测SMPL的参数;
(6)给出了连续两帧的三维网格预测,可微投影网格顶点的三维运动矢量,并将其与估计的二维光流矢量进行匹配;可微运动渲染和匹配需要顶点可见性估计,我们使用光线投射和我们的代码加速神经模型来完成;(如下图)相似的,in each frame,3D keypoint are projected and their distances to corresponding detected 2D keypoints are penalized.Differentiable segmentation matching using Chamfer distances penalizes under and over fitting of the projected vertices against 2D segmentation of the human foreground.Note that thess re-projection errors are only on the shape rather than the texture by design, since our predicted 3D meshes are textureless.
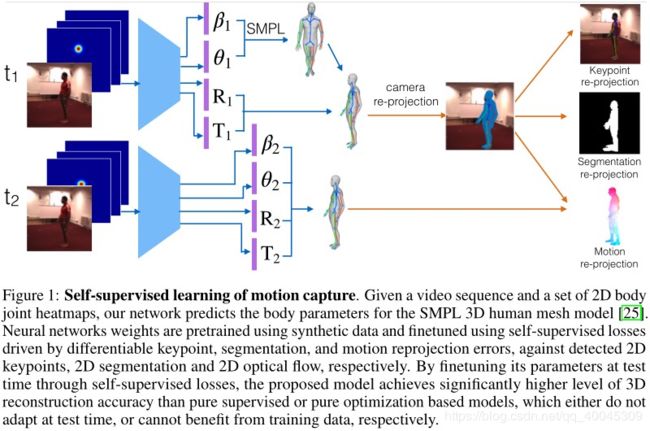
(7)文中成果总结
对比了相应版本的优化策略, 网格参数可以直接通过减小 self-supervision loss 进行优化,与supervised model不同的是,测试时不需要使用self-supervision;optimization baseline 很容易陷入 local minima,对初始化也很敏感。与之相反的是,基于supervised pretraining (on synthetic data)的MOCAP model在测试时,采用reasonable pose initialization; self-supervision adaptation取得相比于non-adapted model 的预训练更低的 3D reconstruction error 。最后还特别强调了三个 self-supervision losses.
(8)数据集
Surral and H3.6M dataset.
2. 相关工作
2.1 3D motion capture
(1)现有的工作很多取得了很好的成果,都是基于multiple cameras(four or more);
(Motion capture using joint skeleton tracking and surface estimation. CVPR 2009)
(2)基于single monocular camera,对于 skeleton-only capture/tracking 还有待研究;
(3)单目运动捕捉中的 ambiguity and occlusion是比较严重的问题,而且多数方法都是基于pose and motion的模型;之前的工作主要是采用 linear motion capture (Robust on-line appearance models for vision tracking; People tracking using hybrid monte carlo fifiltering,ICCV2001);
non-linear prior 有 Guassian process dynamical model and twin Guassian processes,这些比线性模型表现更好;
(Gaussian process dynamical models for 3d people tracking,CVPR2006;Twin gaussian processes for structured prediction.)
(4) Bogo提出 a static image pose and 3d dense shape prediction model,此模型分为两个步骤:a.先从图片中预测3D human skeleton ;b.用一个parametric 3D shape 去拟合这个prediction skeleton,在此期间skeleton 保持不变。
(Keep it SMPL: automatic estimation of 3d human pose and shape from a single image. ECCV, 2016)
(5)本文工作,用end-to-end differentiable framework 通过 test-time adaptation 对3D skeleton and 3D mesh进行估计。
2.2 3D human pose estimation
(1)之前的工作基于 优化 或者是 hard-coded anthropomorphic constraints(比如 关节是对称的) 来 解决 2D-3D 的 ambiguity 问题;
(Reconstructing 3d Human Pose from 2d Image Landmarks,ECCV2012)
(2)使用大量的监督训练集,通过神经网络,直接从RGB 图片中 回归3D pose ;
(Coarse-to-fifine volumetric prediction for single-image 3d human pose. 2016)
(3)把2D pose 作为一个 intermediate representation(A.B) 或者是多任务中的一个辅助性(CD)的任务设置;主要原因是有标签的2D 数据集较多,而3D 较少
(A.3d human pose estimation = 2d pose estimation + matching,2016;
B. Single image 3D interpreter network. In ECCV, 2016;
C. Lifting from the deep: Convolutional 3d pose estimation from a single image. , 2017.
D . Perspective transformer nets: Learning single-view 3d object reconstruction without 3d supervision,2016)
(4)本工作中:
Rogez and Schmid 通过合成3D渲染技术获取了大量的RGB 到3D 标注数据,其中一个数据集也在本工作中使用
(Mocap-guided data augmentation for 3d pose estimation in the wild. In NIPS,2016)
2.3 Deep geometry learning
(1)本工作结合 deep learning 和 geometric inferences;
(Adversarial inverse graphics networks: Learning 2d-to-3d lifting and image-to-image translation from unpaired supervision. ICCV, 2017)
(2)differentiable warping(A.B) and backpropable camera projection(C.D)使用去学习3D camera motion(E) and joint 3D camera and 3D object motion(F) in an end-to-end self-supervision fashion ,minimizing a photometric loss.
(A. Spatial transformer networks. In NIPS, 2015; B. Spatio-temporal video autoencoder with differentiable memory. 2015; C . Single image 3D interpreter network. In ECCV, 2016; D.Perspective transformer nets: Learning single-view 3d object reconstruction without 3d supervision.2016; E. Unsupervised learning of depth and ego-motion from video. In arxiv, 2017; F. Learning of structure and motion from video. In arxiv, 2017)
(3)(A)学习一个 monocular depth predictor, supervised by photometric error, given a stereo image pair with knoen baseline as input;
(A. Unsupervised cnn for single view depth estimation:Geometry to the rescue. Springer, 2016;)
(4)此工作使用了很多深度学习知识,以及geometric operation including a backpropable camera projection layer ,跟Yan(A) and Wu(B) 以及G (C)相似。
(A.Perspective transformer nets: Learning single-view 3d object reconstruction without 3d supervision,2016; B.Single image 3D interpreter network. In ECCV, 2016; C. Unsupervised cnn for single view depth estimation: Geometry to the rescue.Springer, 2016)
3. 网络详解
3.1 learning motion capture
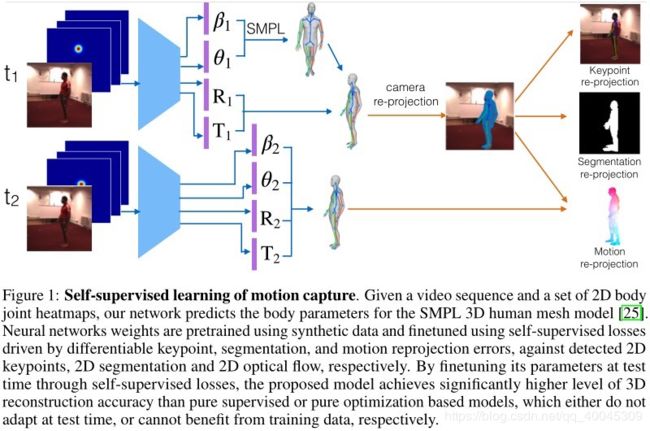
1. 网络结构如上图所示:使用SMPL作为3D的参数化模型(SMPL参数化模型中最重要的两个值是 theta 和 beta)
2. paired supervision from synthetic data: 使用synthetic Surreal dataset(包含了人类角色在二维图像背景下进行活动的单眼视频),这些合成数据使用SMPL 进行参数化,使用Human H3.6M dataset。(见文中细节)
3.1.1 self-supervision through differentiable rendering
模型中的自监督是基于3D-TO-2D 渲染,并对2D关键点估计 分割 和光流进行一致估计;训练和测试时都可以进行自监督,是的我们的模型能够在测试中的权重适合统计量。
1. keypoint re-projection error
一般情况下,给一个静态图片,3D body joint应该与2D keypoint detection能够一致;类似的关键点重构错误在之前的工作已经有所使用;
本文中的模型预测密集的3D 网格;利用3D mesh vertices 和 3D body joints之间的线性关系

为了估计3D 到 2D的投影,我们的模型进一步的预测focal length ,rotation of the camera,并且将三维网格从图像的中心平移,以便于三维网状的根节点能够准确的位于图像的中间;我们不预测Z方向的平移,因为the predicted focal length accounts for scaling of the person figure.
最终的error 是:
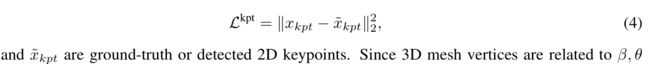
2. motion re-projection error
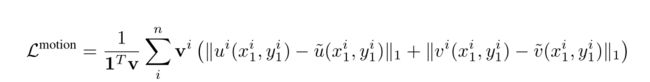
3. segmentation re-projection error
三、实验
1. 数据集处理
Surreal 是最大的人体运动的合成数据集,其包含单目视觉的描述人体日常活动特征的视频判断;GT 3D 网格也是可以使用的。把数据集分为训练和测试视频序列。
Human3.6M 是最大的真实视频数据(包含标注的3D skeletons),包含人体活动以及每一帧中2D 3D 关节位置标注数据,但是没有密集3D ground-truth。
2. 训练
2.1 训练说明
(1)首先,在Surreal 的训练集上,使用有监督的skeleton and surface parameters进行训练;
(2)self-supervision 使用differentiable rendering,在两个数据集上使用re-projection error进行优化; 使用2D keypoint and segmentations 作为GT.
注: Surreal上的segmentation mask是非常精确的,而在H3.6M,采用背景相减的方法得到,可能不是很精确; 我们的模型也改进了这种不精确的分割
(3) 密集运动的2D 光流使用FlowNet2.0 获得,在两个数据集上。
(4)没有使用H3.6M 中的3D GT,这样才能能够说明能够从SURREAL 到 H3.6M 成功的 domain transfer。
(5)在两个数据集上测试3D skeleton,但是仅在SURREAL数据集上测试dense 3D meshes.
2.2 evaluation metrics
1. 对于pre-joint error , reconstruction error 和surface error的度量方法,可以参见文章第七页
2. 基于两个方面与其他的两个标准模型进行比较:
(1) pretrained: 一个模型是仅仅使用合成数据进行监督训练,没有self-supervision adaptation
(2)direct optimization:
一个模型使用跟文中模型一致的 self-supervision losses,不同的是 它优化网络中的权重,直接优化每个body mesh的参数,rotation,translation, and focal length
3. 我们使用梯度下降法进行优化:
在初始化优化方面,使用了不同程度的监督优化策略: random initialization , ground-truth 3D translation, ground-truth rotation ,ground-truth theta angles( to estimaiton the surface parameters)
2.3 补充说明
网络结构 使用 5 convolution blocks,每一个block包含两个 卷积层(filter size 5*5, stride2; filter size 3*3,stride1),后接 batch normalization and leakly relu activation.
第一个block包含64 channels,随后的每一个block 使用双倍的channels;
在每一个block的开始,添加3 个全连层,然后最后一层resize成我们想要的输出;
input image size 128*128; 梯度下降打进行优化,learning rate = 0.0001, TensorFlow version ==1.1.0
文中还使用 Chamfer distance 和 Ray casting,对网络训练速度和精度进行优化,详细细节看文中第九页。
四、讨论
1. 文章工作
(1)提出一种基于合成数据的密集3D 网格跟踪监督模型; 通过网格运动,关键点, 分割的可渲染的自监督模型;并且能够与2D 统计量匹配
(2)使用无标签的数据
(3)联合使用supervised learning 和unsupervised adaptation对于3D mesh预测准确率是有帮助的; 基于自监督的学习模式联合最好的监督学习和测试优化,监督学习初始化学习参数;
(4)自监督模型通过可微渲染方法能够使得模型具备域适应的能力
(5)希望我们的3D mesh模型能够尽可能地 去fit test data,在最少的人为操作情况下提升追踪精确度。
2. 展望
(1)使用iterative additive feedback on the mesk,可以去的更高的3D reconstruction accuracy;允许在参数SMPL 模型上面学习 a residual free form deformation,而不是 in a self-supervised manner.
( Human pose estimation with iterative error feedback. 2015)