【信息检索】Java简易搜索引擎原理及实现(五)计算查询与文档相似度 + 搜索界面开发 + 服务器快速搭建
在上一篇文章:【信息检索】Java简易搜索引擎原理及实现(四)利用布尔模型和向量模型计算权值,我们已经计算出了最终数据呈现所需使用到的大部分数据,本篇我们将完成最后一步:对查询词进行预处理,并计算出查询词与相关文档的相似度,将文档按相似度由高到低排序。同时,完成搜索界面开发和服务器快速搭建的工作。
1.计算查询与文档相似度
(1)查询词预处理
我们在第三篇文章中,构建出了轮排 加上 B+树的索引结构,本次的查询就是基于该结构开展的,因此我们需要首先获取到构建好的B+树。
在第二篇文章中,其实我们也处理过了 AND 、OR、ANDNOT三种操作符,已经可以由单个词组成的查询链查询出匹配的DocId了。但在实际的查询中,用户可能输入并不是完全按照我们的假设,可能会在一个词的位置输入多个词组。
举个例子来说,例如用户希望查询 【数字图像处理 AND 竞赛】,竞赛就看做一个词,它是可以在我们的词库中查询到的;而数字图像处理这个词,在我们的词库中是找不到这样一个完整的词汇的,因为抓取下来的数据已经在存入B+树之前,就由分词器做过分词了,所以此时B+树中能找到的词只有【数字】、【图像】、【处理】。因此,针对这种情况,我们对每一个输入词进行处理,依然让其通过一次分词器,获取到输入词分词后的结果(DocId),将其与原本的输入词的查询结果(DocId)做并集操作。在这个例子中就是,把【数字图像处理】这个词变为【数字图像处理】OR 【数字】OR【图像】OR【处理】,这样即使造成查询出某些不符合用户原意的结果,也能因为后续还要计算相似度而排名靠后展示。
需要注意的是,由于我们的搜索引擎同时支持精确查询和通配符查询。因此,这种拆分搜索词的操作,我们只对精确查找的内容进行处理,对于含通配符的搜索词,我们是不做这一步的。
下面,我们就进行代码实现:我们假设你已经有了前面实验的代码。
public class Experiment6 {
private static Experiment2 experiment2 = new Experiment2();
private static Experiment3 experiment3 = new Experiment3();
public static Map<String, Integer> queryWord_map = new HashMap<>();
public static Integer queryWord_count = 0;
public static BplusTree bPlusTree;
public static void initBPlusTree() {
bPlusTree = experiment3.exp3(); //轮排 + B+树索引结构
}
/**
* 查询用户搜索内容匹配的DocId
* @param input 用户输入
* @param bPlusTree B+树和轮排的索引结构
* @return 查询出的所有匹配的DocId
*/
public static List<Integer> query(String input, BplusTree bPlusTree) {
String[] in_strs = input.split(" ");
//单独处理第一个搜索词
List<Integer> result = getDocList(experiment3.queryForList(in_strs[0], bPlusTree));
List<Integer> next;
//对输入的一个词进行分词并与原结果合并
if (!in_strs[0].contains("*")) {
result = splitWordMerge(in_strs[0], result); //只对精确查找的词进行此操作
}
int len = in_strs.length;
for (int i = 1; i < len; i += 2) { //i取奇数
next = getDocList(experiment3.queryForList(in_strs[i + 1], bPlusTree));
//对输入的一个词进行分词并与原结果合并
if (!in_strs[i + 1].contains("*")) {
next = splitWordMerge(in_strs[i + 1], next); //只对精确查找的词进行此操作
}
//根据操作数合并result和next的DocId
switch (in_strs[i]) {
case "AND":
result = experiment2.operator_AND(result, next);
break;
case "OR":
result = experiment2.operator_OR(result, next);
break;
case "ANDNOT":
result = experiment2.operator_ANDNOT(result, next);
break;
}
}
return result;
}
//对输入的一个词进行分词并与原结果合并
public static List<Integer> splitWordMerge(String word, List<Integer> result) {
String temp = NlpirMethod.NLPIR_ParagraphProcess(word, 0); //0表示不显示词性
String[] temps = temp.split(" ");
if (temps.length > 1) {
for (String str : temps) {
if (str.length() > 0) {
result = experiment2.operator_OR(result, getDocList(experiment3.queryForList(str, bPlusTree)));
}
}
}
return result;
}
//对List- 内的DocId做并集操作
public static List<Integer> getDocList(List<Item> itemList) {
Set<Integer> set = new TreeSet<>();
for (Item item : itemList) {
if (item != null) {
queryWord_map.put(item.term, queryWord_map.getOrDefault(item.term, 0) + 1);
queryWord_count++;
for (Item_ori ori : item.ori_item_list) {
set.add(ori.docId);
}
}
}
return new ArrayList<>(set);
}
}
(2)根据DocId列表,计算出每个DocId对应的文档与查询词的相似度,并按相似度从大到小排序。
从上一篇文章中,我们知道了查询与文档之间相似度的计算公式,这里直接利用公式计算相似度(需注意,如我们在上一篇文章中提到的那样,为了加快计算效率,我们只计算分子值来表征实际值)。
/**
* 本次实验的完整调用代码
* @param input 用户输入的查询内容
* @return
*/
public static List<Article> exp6(String input) {
//输入词查询
List<Integer> result = query(input, bPlusTree);
//存储相似度对应的文章列表
Map<Double, List<Integer>> sim_map = new TreeMap<>(Comparator.reverseOrder());
for (Integer docId : result) {
double sim = calSimDjAndQ(docId);
List<Integer> list = sim_map.getOrDefault(sim, new ArrayList<>());
list.add(docId);
sim_map.put(sim, list);
}
//输出查询结果
StringBuilder sb = new StringBuilder();
for (int i = 0; i < result.size(); i++) {
if (i == result.size() - 1) {
sb.append(result.get(i));
} else {
sb.append(result.get(i)).append(" --> ");
}
}
System.out.println(sb.toString());
List<Article> articleList = new ArrayList<>();
sb.delete(0, sb.length()); //清空StringBuilder
System.out.println("查询相似度排序:");
Iterator<Double> iterator = sim_map.keySet().iterator();
while (iterator.hasNext()) {
Double sim = iterator.next();
List<Integer> list = sim_map.get(sim);
for (Integer docId : list) {
sb.append(docId).append(" : ").append(sim).append("\n");
Article article = Experiment1.article_map.get(docId);
article.sim = Double.valueOf(String.format("%.2f", sim));
articleList.add(article);
}
}
System.out.println(sb.toString());
return articleList;
}
//计算文献dj和查询q的相似度sim(dj,q)
public static double calSimDjAndQ(Integer docId) {
double sim = 0;
Iterator<String> iterator = queryWord_map.keySet().iterator();
while (iterator.hasNext()) {
String term = iterator.next();
double W_ij = Experiment4.getW_ij(term, docId);
double W_iq = (double)queryWord_map.get(term) / queryWord_count;
sim += W_ij * W_iq;
}
return sim;
}
上述代码使用的到的代表文档的类Article代码如下:
public class Article {
public Integer docId; //文章编号
public String title; //文章标题
public String time; //发布时间
public String abstra; //文章摘要
public String url; //链接地址
public Double sim; //相关度
public Article(Integer docId, String title, String time, String abstra, String url) {
this.docId = docId;
this.title = title;
this.time = time;
this.abstra = abstra;
this.url = url;
}
public Integer getDocId() {
return docId;
}
public void setDocId(Integer docId) {
this.docId = docId;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
public String getAbstra() {
return abstra;
}
public void setAbstra(String abstra) {
this.abstra = abstra;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public Double getSim() {
return sim;
}
public void setSim(Double sim) {
this.sim = sim;
}
}
这里提及一下,我们从网站上爬取网页内容时,存储到本地的文档是按照如下图的格式存储的:

第一行是网页的URL,第二行是此文档的标题,第三行是文档的发布时间,第四行的数字表示正文在文档中的开始位置,第五行开始才是文档的正文。
(3)相似文档查询
对于上一步我们查询出的文档,用户可能会对某些文档的相似文档感兴趣,正好我们在上一篇文章中有写过计算两个文档间相似度的函数,因此我们在此可实现针对一篇文档的相似文档查询功能。
//相似文档查询
public static List<Article> findSimArticles(Integer docId) {
List<Article> articleList = new ArrayList<>();
TreeMap<Double, Article> treeMap = new TreeMap<>(Comparator.reverseOrder());
for (int i = 1; i < Experiment4.N; i++) {
if (i == docId) {
continue;
}
double sim = Experiment4.querySim(1, docId, i);
if (sim >= 20) {
Article article = Experiment1.article_map.get(i);
article.sim = sim;
treeMap.put(sim, article);
}
}
Iterator<Double> iterator = treeMap.keySet().iterator();
while (iterator.hasNext()) {
articleList.add(treeMap.get(iterator.next()));
}
return articleList;
}
至此,第一步我们就完成了。
2.搜索界面开发
我选用的是Web网页来做最后的结果呈现,我们要先写出一个网页来。
我采用的是Bootstrap + jQuery来实现的网页。Bootstrap为我们提供了许多已经封装好的组件,这里就直接使用了,关于Bootstrap的各种样式的使用方法,请参考Boostrap官方文档
界面需要实现的功能就是,用户在输入框内输入搜索词,点击搜索按钮后,在本页面的下方给出一条条的查询结果,每条查询结果中可点击【相似文档】链接,弹出一个模态框,显示与该文档匹配的相似文档列表。
由于这也不是我们本文的重点,便不多做解释。界面的代码也很长,文章中就不贴出来了,需要的同学可在最后提供的下载链接中下载到完整代码。
3.服务器快速搭建
我们需要把之前完成的所有功能代码,迁移到服务器上,才能和网页之间做一个数据交互。
我采用的是SpringBoot快速搭建出一个服务器。
服务器提供一个Controller,包含普通查询和相似文档查询两个函数,作为网页请求的接口。
由于我们需要服务器在启动的时候,执行一些初始化操作,构建出用于查询的B+树结构。因此,在代码中我们还提供一个MyCommandRunner类,实现了CommandLineRunner接口,用于在SpringBoot容器加载后自动执行初始化代码。
至此,我们最终就实现了一个简易的搜索引擎,效果就如第一篇文章中的那样:
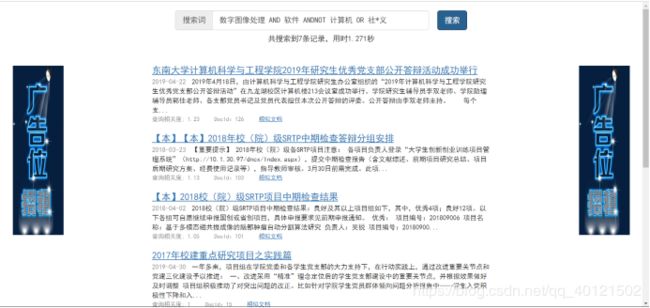

最后,奉上完整代码下载地址:https://download.csdn.net/download/qq_40121502/11214479
完结。