Sincronia:Coflows的近似最优网络设计
本文为SIGCOMM 2018会议论文。
笔者翻译和总结了该论文的主要部分。由于时间仓促,且笔者英文能力有限,错误之处在所难免;欢迎读者批评指正。
本文及翻译版本仅用于学习使用。如果有任何不当,请联系笔者删除。
如需转载,请联系笔者。
摘要
我们提出了Sincronia,这是一种针对coflows的近乎最优的网络设计,可以在任何支持优先级调度的传输层上实现。 Sincronia使用一个关键的技术结果来实现这一点:我们表明,给定一个“正确”的coflow排序,任何每流(per-flow)速率分配机制都可以取得不超过最优值4倍的平均流完成时间,只要(co)flows按照排序赋予优先级。
Sincronia使用一种简单的贪婪机制来定期排序所有未完成的coflows; 每个主机使用相应的coflow顺序为其数据流设置优先级,并将流调度和速率分配卸载到底层的优先级使能的传输层。我们通过包含16台服务器和商用交换机的真实测试平台评估Sincronia,并在各种工作负载中使用模拟。评估结果表明,Sincronia不仅实现了一种实用的,接近最优的设计,而且还提升了最先进的coflow网络设计(有时甚至高达8倍)。
跨数据中心网络运行的分布式应用程序使用编程模型(例如,批量同步(bulk synchronous )编程和分区聚合(partition-aggregate)模型),这些模型需要优化多个数据流的性能而不是单个流量。 网络仍然优化了各个数据流的性能,导致应用的性能目标与网络设计的优化目标之间存在根本的不匹配。
Coflow抽象[7]缓解了这种不匹配,允许分布式应用程序更精确地向网络设施表达其性能目标。例如,许多具有严格性能限制的分布式服务必须阻塞,直到从数百甚至数千个远程服务器接收所有或几乎所有响应。 这些服务可以指定一组数据流(flow)作为coflows。网络设施现在优化平均Coflow完成时间(CCT)[7,10,12],其中coflow的CCT定义为coflow中某些百分比(可能是100%)的数据流的完成时间。 最近的几项评估表明,优化平均CCT可以显着提高应用程序的性能[7,10,12]。
但是,先前的设计使用集中协调器来执行复杂的每流速率分配,其中分配给数据流的速率取决于分配给网络中其他数据流的速率。这种集中的相互依赖的每流速率分配使得在实践中很难实现这些设计,这有几个原因。 首先,每流速率分配自然地需要了解网络中拥塞的位置以及每个(co)flow流所采用的路径,这使得当网络核心拥塞和/或拥塞动态变化时很难使用这些设计。其次,由于分配给数据流的速率是相关的,即使一个coflow的到达或离开也可能导致网络中每个数据流速率的重新分配。这种重新分配在数据中心是不切实际的,因为数据中心每秒可能会有数千个coflow同时到达。 因此,针对coflow的实际且近乎理想的网络设计仍然难以实现。
本文介绍了Sincronia,这是一种新的数据中心网络设计,用于实现接近最优的平均CCT,而无需任何显式的每流速率分配机制。Sincronia的高级设计可归纳为:
- 时间划分为代(epoch)
- 在每个代中,选择未完成的coflow的子集,并使用简单的贪婪算法进行“排序”;
- 每个主机独立地为其数据流设置优先级(基于相应的coflow的顺序),并将数据流卸载到优先级使能的传输层机制;
- 在代边界之间到达的coflow使用贪婪调度以实现工作保持。
Sincronia的简约设计基于一个关键的技术结果 :使用coflow的“正确”的顺序,就可以取得在最优值4倍范围内的平均CCT,只要coflow调度是“保序”的,即如果coflow C的排序高于coflow C',C中的流/数据包必须优先于C'中的流/数据包。
Coflow[7,10]是一系列具有共同性能目标(例如,最小化coflow中最后一个数据流的完成时间)的数据流。图1给出一个示例。
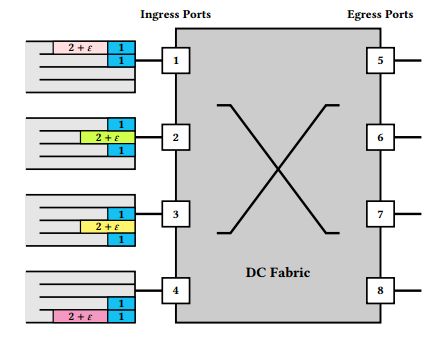
coflow中的数据流是独立的; 也就是说,数据流的输入不依赖于该coflow中另一个数据流的输出。假设有关coflow的信息(数据流集合,相应的源、目的和大小)在coflow到达时才能获知,而不能在这之前获知。
概念模型(用于理论界限)。 类似于用于网络流[4,13,15]和coflow[3,10,12,14,19,2]的传统抽象的近似最优网络设计,我们将数据中心网络抽象为一个互连服务器的大交换机。在这种大型交换机模型中,入口队列对应于NIC,出口队列对应于最后一跳TOR交换机。该模型假设网络核心可以维持100%的吞吐量,并且只有入口和出口队列是潜在的拥塞点。在此模型下,每个入口端口都有来自一个或多个coflow并到各个出口端口的数据流(参见图1)。为了便于说明,我们在入口端口将数据流组织到虚拟输出队列。我们使用这种抽象来简化我们的理论分析和算法描述,但我们不会在我们的设计和实验中强制要求这一抽象。
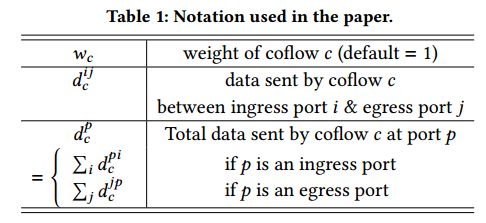
性能目标。形式上,我们假设网络是一个包含m个入口端口{1, 2, ... , m}和m个出口端口{m + 1, m + 2, ..., 2m}的大型交换机。 除非另有说明,否则所有端口都具有相同的带宽。给定n个coflow的集合C = {1, 2, ..., n},索引为c。每个coflow c可以被赋予权重wc(默认权重是1),具有到达时间ac并且包括一组数据流Fc。在时间ac,coflow中每个数据流的源、目的地和大小是已知的。入口端口i和出口端口j之间的coflow c发送的数据总量由dcij表示(有关符号及含义,请参见表1)。
coflow的完成时间(CCTc)是coflow中最后一个数据流的完成时间与其到达时间ac之间的差异。C的平均CCT是其中所有coflow的完成时间的平均值∑cCCTc/n。 加权平均CCT定义为(∑cwc*CCTc)/n。 鉴于这一表述,先前的工作已经确定:
- NP-难[10]。即使所有的coflow在时间0到达,并且它们的大小是事先知道的,最小化平均CCT的问题也是NP难的(通过concurrent open-shop scheduling problem [23]约简)。 因此,我们所能期望的最好的是近似算法。
- 下界[5,24]。即使在大交换机模型下,唯一已知的下界是数据流下界的自然推广: 在某个强于P≠NP的复杂理论假设下,也不可能在一个 2 - ε因子内的最小化(加权)平均CCT。
- 协调的必要性[8]。存在一个coflow调度问题的实例,其中不使用任何协调的调度算法将实现最优的平均CCT Ω()。 因此,至少需要一些协调才能实现任何有意义的近似。
我们的离线算法包含两个部分。第一个组件是组合原始对偶(combinatorial primal-dual)贪心算法(Bottleneck-Select-Scale-Iterate, BSSI),用于排序coflow; 第二个组成部分表明,工作保持的、抢占的并按照相应的coflow排序顺序的调度数据流的任何数据流速率分配机制都可以实现最优值4倍内的平均CCT。

BSSI推广了一种接近最优的流量调度机制(即 “Shortest Remaining Processing Time” first (SRPT-first) [4])以用于coflow的情形。
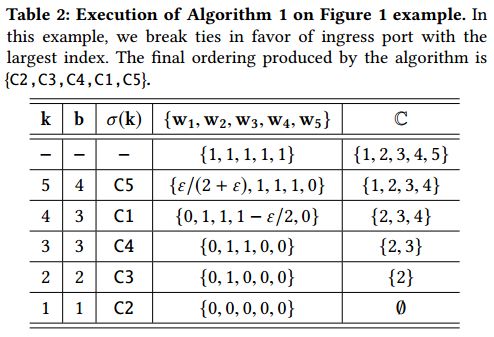
BSSI分为四个步骤: 瓶颈、选择、缩放、迭代。在前两个步骤中,BSSI将数据流的SRPT-first策略推广到coflow的情形。直观地,它使用SRPT的替代视图: Largest Remaining Processing Time last (LRPT-last)。具体地,第一步找到具有最大瓶颈的入口端口或出口端口(比如说b,定义为所有无序coflow中发送或接收最大数据量的端口); 第二步然后实现LRPT-last:它选择在端口b具有最大剩余加权处理时间的coflow,并将该coflow放在所有无序coflow中的最后一个。BSSI的第三步缩放所有无序coflow的权重,以捕获在第二步中选择的coflow的排序如何影响所有剩余coflow的完成时间。最后一步是简单地迭代一组无序流,直到所有的coflow都被排序。
例子。表2示出在图1示例上的算法1的执行过程。在第一次迭代(k = 5)中,算法选择瓶颈端口b = 4,并且LRPT coflow σ(5) = C5。然后算法缩放权重: 在这个例子中,它最终减少了coflow C1的权重,同时保持其他权重不变。这种权重的减少允许C1在下一次迭代(k = 4)中被选择作为LRPT coflow。图2比较了Sincronia与Varys [10]的性能,以及此示例的最优值。 通过在上面的例子中添加更多的端口和相应的coflow,可以证明Varys的平均CCT与Sincronia(和最佳)相比可以任意地变得更加恶劣[2]。

我们使用约3000行c++代码实现了Sincronia。这包括一个中央协调器和位于每个服务器上应用程序和传输层之间的层(见图4)。
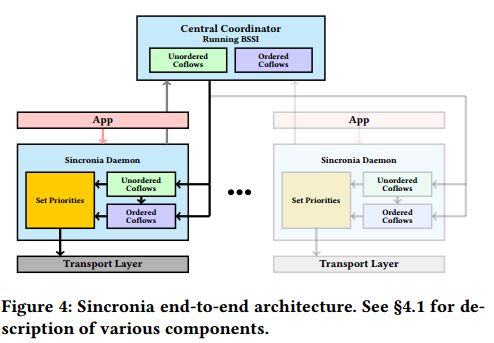
coflow到达后,应用告知Sincronia守护进程关于coflow的信息(coflow ID,包含的数据流,相应的源、目的地址和大小等); 守护进程将此coflow添加到“无序coflow”列表中(用于工作保持),然后使用上述信息向协调器注册coflow。守护进程还维护一个“有序coflow”列表,这是已由协调器分配了顺序的coflows。 当正在进行的数据流结束时,守护进程从当前最高有序的coflow(如果存在)或从无序列表中(如果不存在有序的coflow)选择一个数据流,并为该数据流分配适当的优先级,并将其发送到传输层。守护进程还会从协调器中注销已完成的(co)flow。分配给有序和无序coflow的优先级取决于底层传输层机制。
协调器执行以下任务。它将时间划分为代。 协调器维护一个“无序coflow”列表,表示已经注册但尚未排序(排序仅在每个代开始时完成)的coflow。在每个代的开始,协调器从无序coflow列表中选择一组coflow,并使用离线算法对这些coflow进行排序。一旦计算完成,协调器就会从无序coflow列表中删除有序coflow,并将“有序coflow”列表发送给所有包含未完成coflow的服务器; 我们在这里使用了几个优化,这样协调器只通知服务器有序列表中的更改,而不是重新发送整个有序列表。 请注意,每个服务器都不知道协调器维护的代; 因此,服务器不需要与协调器进行时间同步。