SSD tensorflow及源码详解
原文地址https://blog.csdn.net/c20081052/article/details/80391627SSD tensorflow及源码详解
本文主要针对SSD的tensorflow框架下的实现的源码解读即对网络模型的理解。
【前言】
首先在github上下载tensorflow版的SSD repository:https://github.com/balancap/SSD-Tensorflow
同时附上论文地址:SSD 论文下载
解压SSD-Tensorflow-master.zip 到自己工作目录下。
SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为 的特征图,只需要采用 这样比较小的卷积核得到检测值;
SSD的检测值也与Yolo不太一样。对于每个单元的每个先验框,其都输出一套独立的检测值,对应一个边界框,主要分为两个部分。第一部分是各个类别的置信度或者评分,值得注意的是SSD将背景也当做了一个特殊的类别,如果检测目标共有 个类别,SSD其实需要预测 个置信度值,其中第一个置信度指的是不含目标或者属于背景的评分。后面当我们说 个类别置信度时,请记住里面包含背景那个特殊的类别,即真实的检测类别只有 个。在预测过程中,置信度最高的那个类别就是边界框所属的类别,特别地,当第一个置信度值最高时,表示边界框中并不包含目标。第二部分就是边界框的location,包含4个值 ,分别表示边界框的中心坐标以及宽高。但是真实预测值其实只是边界框相对于先验框的转换值(paper里面说是offset,但是觉得transformation更合适,参见R-CNN)。先验框位置用 表示,其对应边界框用 $表示,那么边界框的预测值 其实是 相对于 的转换值:
习惯上,我们称上面这个过程为边界框的编码(encode),预测时,你需要反向这个过程,即进行解码(decode),从预测值 中得到边界框的真实位置 :
然而,在SSD的Caffe源码实现中还有trick,那就是设置variance超参数来调整检测值,通过bool参数variance_encoded_in_target来控制两种模式,当其为True时,表示variance被包含在预测值中,就是上面那种情况。但是如果是False(大部分采用这种方式,训练更容易?),就需要手动设置超参数variance,用来对 的4个值进行放缩,此时边界框需要这样解码:
综上所述,对于一个大小 的特征图,共有 个单元,每个单元设置的先验框数目记为 ,那么每个单元共需要 个预测值,所有的单元共需要 个预测值,由于SSD采用卷积做检测,所以就需要 个卷积核完成这个特征图的检测过程。
VGG16中的Conv4_3层将作为用于检测的第一个特征图。conv4_3层特征图大小是 ,但是该层比较靠前,其norm较大,所以在其后面增加了一个L2 Normalization层(参见ParseNet),以保证和后面的检测层差异不是很大,这个和Batch Normalization层不太一样,其仅仅是对每个像素点在channle维度做归一化,而Batch Normalization层是在[batch_size, width, height]三个维度上做归一化。归一化后一般设置一个可训练的放缩变量gamma。
默认情况下,每个特征图会有一个 且尺度为 的先验框,除此之外,还会设置一个尺度为 且 的先验框,这样每个特征图都设置了两个长宽比为1但大小不同的正方形先验框。注意最后一个特征图需要参考一个虚拟 来计算 。因此,每个特征图一共有 个先验框 ,但是在实现时,Conv4_3,Conv10_2和Conv11_2层仅使用4个先验框,它们不使用长宽比为 的先验框。每个单元的先验框的中心点分布在各个单元的中心,即 ,其中 为特征图的大小。
训练过程
(1)先验框匹配
在训练过程中,首先要确定训练图片中的ground truth(真实目标)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。在Yolo中,ground truth的中心落在哪个单元格,该单元格中与其IOU最大的边界框负责预测它。但是在SSD中却完全不一样,SSD的先验框与ground truth的匹配原则主要有两点。首先,对于图片中每个ground truth,找到与其IOU最大的先验框,该先验框与其匹配,这样,可以保证每个ground truth一定与某个先验框匹配。通常称与ground truth匹配的先验框为正样本(其实应该是先验框对应的预测box,不过由于是一一对应的就这样称呼了),反之,若一个先验框没有与任何ground truth进行匹配,那么该先验框只能与背景匹配,就是负样本。一个图片中ground truth是非常少的, 而先验框却很多,如果仅按第一个原则匹配,很多先验框会是负样本,正负样本极其不平衡,所以需要第二个原则。第二个原则是:对于剩余的未匹配先验框,若某个ground truth的 大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。这意味着某个ground truth可能与多个先验框匹配,这是可以的。但是反过来却不可以,因为一个先验框只能匹配一个ground truth,如果多个ground truth与某个先验框 大于阈值,那么先验框只与IOU最大的那个先验框进行匹配。第二个原则一定在第一个原则之后进行,仔细考虑一下这种情况,如果某个ground truth所对应最大 小于阈值,并且所匹配的先验框却与另外一个ground truth的 大于阈值,那么该先验框应该匹配谁,答案应该是前者,首先要确保某个ground truth一定有一个先验框与之匹配。但是,这种情况我觉得基本上是不存在的。由于先验框很多,某个ground truth的最大 肯定大于阈值,所以可能只实施第二个原则既可以了,这里的TensorFlow版本就是只实施了第二个原则,但是这里的Pytorch两个原则都实施了。图8为一个匹配示意图,其中绿色的GT是ground truth,红色为先验框,FP表示负样本,TP表示正样本。
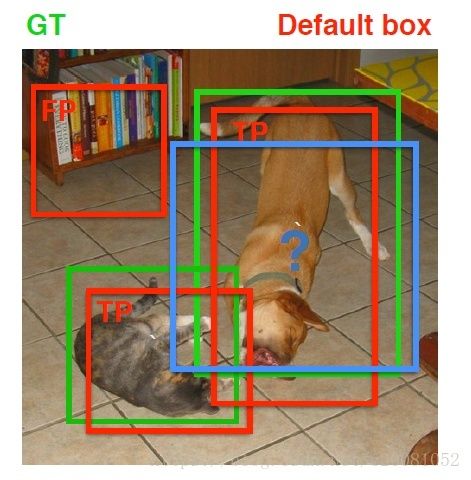
图8 先验框匹配示意图
尽管一个ground truth可以与多个先验框匹配,但是ground truth相对先验框还是太少了,所以负样本相对正样本会很多。为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
(2)损失函数
训练样本确定了,然后就是损失函数了。损失函数定义为位置误差(locatization loss, loc)与置信度误差(confidence loss, conf)的加权和:
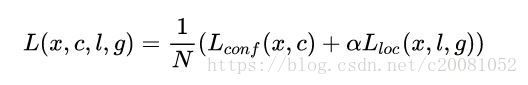
其中 是先验框的正样本数量。这里 为一个指示参数,当 时表示第 个先验框与第 个ground truth匹配,并且ground truth的类别为 。 为类别置信度预测值。 为先验框的所对应边界框的位置预测值,而 是ground truth的位置参数。对于位置误差,其采用Smooth L1 loss,定义如下:
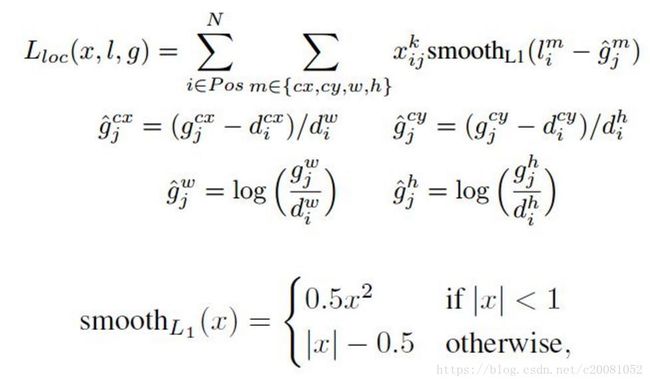
由于 的存在,所以位置误差仅针对正样本进行计算。值得注意的是,要先对ground truth的 进行编码得到 ,因为预测值 也是编码值,若设置variance_encoded_in_target=True,编码时要加上variance:
对于置信度误差,其采用softmax loss:
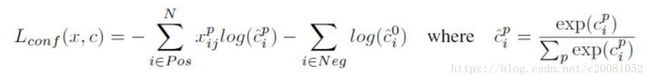
权重系数 通过交叉验证设置为1。
预测过程
预测过程比较简单,对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。
一. 源码解读;
其中ssd_vgg_300.py代码解析如下:
-
# Copyright 2016 Paul Balanca. All Rights Reserved.
-
#
-
# Licensed under the Apache License, Version 2.0 (the "License");
-
# you may not use this file except in compliance with the License.
-
# You may obtain a copy of the License at
-
#
-
# http://www.apache.org/licenses/LICENSE-2.0
-
#
-
# Unless required by applicable law or agreed to in writing, software
-
# distributed under the License is distributed on an "AS IS" BASIS,
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-
# See the License for the specific language governing permissions and
-
# limitations under the License.
-
# ==============================================================================
-
"""Definition of 300 VGG-based SSD network.
-
-
This model was initially introduced in:
-
SSD: Single Shot MultiBox Detector
-
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed,
-
Cheng-Yang Fu, Alexander C. Berg
-
https://arxiv.org/abs/1512.02325
-
-
Two variants of the model are defined: the 300x300 and 512x512 models, the
-
latter obtaining a slightly better accuracy on Pascal VOC.
-
-
Usage:
-
with slim.arg_scope(ssd_vgg.ssd_vgg()):
-
outputs, end_points = ssd_vgg.ssd_vgg(inputs)
-
-
This network port of the original Caffe model. The padding in TF and Caffe
-
is slightly different, and can lead to severe accuracy drop if not taken care
-
in a correct way!
-
-
In Caffe, the output size of convolution and pooling layers are computing as
-
following: h_o = (h_i + 2 * pad_h - kernel_h) / stride_h + 1
-
-
Nevertheless, there is a subtle difference between both for stride > 1. In
-
the case of convolution:
-
top_size = floor((bottom_size + 2*pad - kernel_size) / stride) + 1
-
whereas for pooling:
-
top_size = ceil((bottom_size + 2*pad - kernel_size) / stride) + 1
-
Hence implicitely allowing some additional padding even if pad = 0. This
-
behaviour explains why pooling with stride and kernel of size 2 are behaving
-
the same way in TensorFlow and Caffe.
-
-
Nevertheless, this is not the case anymore for other kernel sizes, hence
-
motivating the use of special padding layer for controlling these side-effects.
-
-
@@ssd_vgg_300
-
"""
-
import math
-
from collections
import namedtuple
-
-
import numpy
as np
-
import tensorflow
as tf
-
-
import tf_extended
as tfe
-
from nets
import custom_layers
-
from nets
import ssd_common
-
-
slim = tf.contrib.slim
-
-
-
# =========================================================================== #
-
# SSD class definition.
-
# =========================================================================== #
-
#collections模块的namedtuple子类不仅可以使用item的index访问item,还可以通过item的name进行访问可以将namedtuple理解为c中的struct结构,其首先将各个item命名,然后对每个item赋予数据
-
SSDParams = namedtuple(
'SSDParameters', [
'img_shape',
#输入图像大小
-
'num_classes',
#分类类别数
-
'no_annotation_label',
#无标注标签
-
'feat_layers',
#特征层
-
'feat_shapes',
#特征层形状大小
-
'anchor_size_bounds',
#锚点框大小上下边界,是与原图相比得到的小数值
-
'anchor_sizes',
#初始锚点框尺寸
-
'anchor_ratios',
#锚点框长宽比
-
'anchor_steps',
#特征图相对原始图像的缩放
-
'anchor_offset',
#锚点框中心的偏移
-
'normalizations',
#是否正则化
-
'prior_scaling'
#是对特征图参考框向gtbox做回归时用到的尺度缩放(0.1,0.1,0.2,0.2)
-
])
-
-
-
class SSDNet(object):
-
"""Implementation of the SSD VGG-based 300 network.
-
-
The default features layers with 300x300 image input are:
-
conv4 ==> 38 x 38
-
conv7 ==> 19 x 19
-
conv8 ==> 10 x 10
-
conv9 ==> 5 x 5
-
conv10 ==> 3 x 3
-
conv11 ==> 1 x 1
-
The default image size used to train this network is 300x300. #训练输入图像尺寸默认为300x300
-
"""
-
default_params = SSDParams(
#默认参数
-
img_shape=(
300,
300),
-
num_classes=
21,
#包含背景在内,共21类目标类别
-
no_annotation_label=
21,
-
feat_layers=[
'block4',
'block7',
'block8',
'block9',
'block10',
'block11'],
#特征层名字
-
feat_shapes=[(
38,
38), (
19,
19), (
10,
10), (
5,
5), (
3,
3), (
1,
1)],
#特征层尺寸
-
anchor_size_bounds=[
0.15,
0.90],
-
# anchor_size_bounds=[0.20, 0.90], #论文中初始预测框大小为0.2x300~0.9x300;实际代码是[45,270]
-
anchor_sizes=[(
21.,
45.),
#直接给出的每个特征图上起初的锚点框大小;如第一个特征层框大小是h:21;w:45; 共6个特征图用于回归
-
(
45.,
99.),
#越小的框能够得到原图上更多的局部信息,反之得到更多的全局信息;
-
(
99.,
153.),
-
(
153.,
207.),
-
(
207.,
261.),
-
(
261.,
315.)],
-
# anchor_sizes=[(30., 60.),
-
# (60., 111.),
-
# (111., 162.),
-
# (162., 213.),
-
# (213., 264.),
-
# (264., 315.)],
-
anchor_ratios=[[
2,
.5],
#每个特征层上的每个特征点预测的box长宽比及数量;如:block4: def_boxes:4
-
[
2,
.5,
3,
1./
3],
#block7: def_boxes:6 (ratios中的4个+默认的1:1+额外增加的一个=6)
-
[
2,
.5,
3,
1./
3],
#block8: def_boxes:6
-
[
2,
.5,
3,
1./
3],
#block9: def_boxes:6
-
[
2,
.5],
#block10: def_boxes:4
-
[
2,
.5]],
#block11: def_boxes:4 #备注:实际上略去了默认的ratio=1以及多加了一个sqrt(初始框宽*初始框高),后面代码有
-
anchor_steps=[
8,
16,
32,
64,
100,
300],
#特征图锚点框放大到原始图的缩放比例;
-
anchor_offset=
0.5,
#每个锚点框中心点在该特征图cell中心,因此offset=0.5
-
normalizations=[
20,
-1,
-1,
-1,
-1,
-1],
#是否归一化,大于0则进行,否则不做归一化;目前看来只对block_4进行正则化,因为该层比较靠前,其norm较大,需做L2正则化(仅仅对每个像素在channel维度做归一化)以保证和后面检测层差异不是很大;
-
prior_scaling=[
0.1,
0.1,
0.2,
0.2]
#特征图上每个目标与参考框间的尺寸缩放(y,x,h,w)解码时用到
-
)
-
-
def __init__(self, params=None):
#网络参数的初始化
-
"""Init the SSD net with some parameters. Use the default ones
-
if none provided.
-
"""
-
if isinstance(params, SSDParams):
#是否有参数输入,是则用输入的,否则使用默认的
-
self.params = params
#isinstance是python的內建函数,如果参数1与参数2的类型相同则返回true;
-
else:
-
self.params = SSDNet.default_params
-
-
# ======================================================================= #
-
def net(self, inputs, #定义网络模型
-
is_training=True, #是否训练
-
update_feat_shapes=True, #是否更新特征层的尺寸
-
dropout_keep_prob=0.5, #dropout=0.5
-
prediction_fn=slim.softmax, #采用softmax预测结果
-
reuse=None,
-
scope='ssd_300_vgg'):
#网络名:ssd_300_vgg (基础网络时VGG,输入训练图像size是300x300)
-
"""SSD network definition.
-
"""
-
r = ssd_net(inputs,
#网络输入参数r
-
num_classes=self.params.num_classes,
-
feat_layers=self.params.feat_layers,
-
anchor_sizes=self.params.anchor_sizes,
-
anchor_ratios=self.params.anchor_ratios,
-
normalizations=self.params.normalizations,
-
is_training=is_training,
-
dropout_keep_prob=dropout_keep_prob,
-
prediction_fn=prediction_fn,
-
reuse=reuse,
-
scope=scope)
-
# Update feature shapes (try at least!) #下面这步我的理解就是让读者自行更改特征层的输入,未必论文中介绍的那几个block
-
if update_feat_shapes:
#是否更新特征层图像尺寸?
-
shapes = ssd_feat_shapes_from_net(r[
0], self.params.feat_shapes)
#输入特征层图像尺寸以及inputs(应该是预测的特征尺寸),输出更新后的特征图尺寸列表
-
self.params = self.params._replace(feat_shapes=shapes)
#将更新的特征图尺寸shapes替换当前的特征图尺寸
-
return r
#更新网络输入参数r
-
-
def arg_scope(self, weight_decay=0.0005, data_format='NHWC'):
#定义权重衰减=0.0005,L2正则化项系数;数据类型是NHWC
-
"""Network arg_scope.
-
"""
-
return ssd_arg_scope(weight_decay, data_format=data_format)
-
-
def arg_scope_caffe(self, caffe_scope):
-
"""Caffe arg_scope used for weights importing.
-
"""
-
return ssd_arg_scope_caffe(caffe_scope)
-
-
# ======================================================================= #
-
def update_feature_shapes(self, predictions):
#更新特征形状尺寸(来自预测结果)
-
"""Update feature shapes from predictions collection (Tensor or Numpy
-
array).
-
"""
-
shapes = ssd_feat_shapes_from_net(predictions, self.params.feat_shapes)
-
self.params = self.params._replace(feat_shapes=shapes)
-
-
def anchors(self, img_shape, dtype=np.float32):
#输入原始图像尺寸;返回每个特征层每个参考锚点框的位置及尺寸信息(x,y,h,w)
-
"""Compute the default anchor boxes, given an image shape.
-
"""
-
return ssd_anchors_all_layers(img_shape,
#这是个关键函数;检测所有特征层中的参考锚点框位置和尺寸信息
-
self.params.feat_shapes,
-
self.params.anchor_sizes,
-
self.params.anchor_ratios,
-
self.params.anchor_steps,
-
self.params.anchor_offset,
-
dtype)
-
-
def bboxes_encode(self, labels, bboxes, anchors, #编码,用于将标签信息,真实目标信息和锚点框信息编码在一起;得到预测真实框到参考框的转换值
-
scope=None):
-
"""Encode labels and bounding boxes.
-
"""
-
return ssd_common.tf_ssd_bboxes_encode(
-
labels, bboxes, anchors,
-
self.params.num_classes,
-
self.params.no_annotation_label,
#未标注的标签(应该代表背景)
-
ignore_threshold=
0.5,
#IOU筛选阈值
-
prior_scaling=self.params.prior_scaling,
#特征图目标与参考框间的尺寸缩放(0.1,0.1,0.2,0.2)
-
scope=scope)
-
-
def bboxes_decode(self, feat_localizations, anchors, #解码,用锚点框信息,锚点框与预测真实框间的转换值,得到真是的预测框(ymin,xmin,ymax,xmax)
-
scope='ssd_bboxes_decode'):
-
"""Encode labels and bounding boxes.
-
"""
-
return ssd_common.tf_ssd_bboxes_decode(
-
feat_localizations, anchors,
-
prior_scaling=self.params.prior_scaling,
-
scope=scope)
-
-
def detected_bboxes(self, predictions, localisations, #通过SSD网络,得到检测到的bbox
-
select_threshold=None, nms_threshold=0.5,
-
clipping_bbox=None, top_k=400, keep_top_k=200):
-
"""Get the detected bounding boxes from the SSD network output.
-
"""
-
# Select top_k bboxes from predictions, and clip #选取top_k=400个框,并对框做修建(超出原图尺寸范围的切掉)
-
rscores, rbboxes = \
#得到对应某个类别的得分值以及bbox
-
ssd_common.tf_ssd_bboxes_select(predictions, localisations,
-
select_threshold=select_threshold,
-
num_classes=self.params.num_classes)
-
rscores, rbboxes = \
#按照得分高低,筛选出400个bbox和对应得分
-
tfe.bboxes_sort(rscores, rbboxes, top_k=top_k)
-
# Apply NMS algorithm. #应用非极大值抑制,筛选掉与得分最高bbox重叠率大于0.5的,保留200个
-
rscores, rbboxes = \
-
tfe.bboxes_nms_batch(rscores, rbboxes,
-
nms_threshold=nms_threshold,
-
keep_top_k=keep_top_k)
-
if clipping_bbox
is
not
None:
-
rbboxes = tfe.bboxes_clip(clipping_bbox, rbboxes)
-
return rscores, rbboxes
#返回裁剪好的bbox和对应得分
-
#尽管一个ground truth可以与多个先验框匹配,但是ground truth相对先验框还是太少了,
-
#所以负样本相对正样本会很多。为了保证正负样本尽量平衡,SSD采用了hard negative mining,
-
#就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,
-
#选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3
-
def losses(self, logits, localisations,
-
gclasses, glocalisations, gscores,
-
match_threshold=0.5,
-
negative_ratio=3.,
-
alpha=1.,
-
label_smoothing=0.,
-
scope='ssd_losses'):
-
"""Define the SSD network losses.
-
"""
-
return ssd_losses(logits, localisations,
-
gclasses, glocalisations, gscores,
-
match_threshold=match_threshold,
-
negative_ratio=negative_ratio,
-
alpha=alpha,
-
label_smoothing=label_smoothing,
-
scope=scope)
-
-
-
# =========================================================================== #
-
# SSD tools...
-
# =========================================================================== #
-
def ssd_size_bounds_to_values(size_bounds,
-
n_feat_layers,
-
img_shape=(300, 300)):
-
"""Compute the reference sizes of the anchor boxes from relative bounds.
-
The absolute values are measured in pixels, based on the network
-
default size (300 pixels).
-
-
This function follows the computation performed in the original
-
implementation of SSD in Caffe.
-
-
Return:
-
list of list containing the absolute sizes at each scale. For each scale,
-
the ratios only apply to the first value.
-
"""
-
assert img_shape[
0] == img_shape[
1]
-
-
img_size = img_shape[
0]
-
min_ratio = int(size_bounds[
0] *
100)
-
max_ratio = int(size_bounds[
1] *
100)
-
step = int(math.floor((max_ratio - min_ratio) / (n_feat_layers -
2)))
-
# Start with the following smallest sizes.
-
sizes = [[img_size * size_bounds[
0] /
2, img_size * size_bounds[
0]]]
-
for ratio
in range(min_ratio, max_ratio +
1, step):
-
sizes.append((img_size * ratio /
100.,
-
img_size * (ratio + step) /
100.))
-
return sizes
-
-
-
def ssd_feat_shapes_from_net(predictions, default_shapes=None):
-
"""Try to obtain the feature shapes from the prediction layers. The latter
-
can be either a Tensor or Numpy ndarray.
-
-
Return:
-
list of feature shapes. Default values if predictions shape not fully
-
determined.
-
"""
-
feat_shapes = []
-
for l
in predictions:
#l:是预测的特征形状
-
# Get the shape, from either a np array or a tensor.
-
if isinstance(l, np.ndarray):
#如果l是np.ndarray类型,则将l的形状赋给shape;否则将shape作为list
-
shape = l.shape
-
else:
-
shape = l.get_shape().as_list()
-
shape = shape[
1:
4]
-
# Problem: undetermined shape... #如果预测的特征尺寸未定,则使用默认的形状;否则将shape中的值赋给特征形状列表中
-
if
None
in shape:
-
return default_shapes
-
else:
-
feat_shapes.append(shape)
-
return feat_shapes
#返回更新后的特征尺寸list
-
-
-
def ssd_anchor_one_layer(img_shape, #检测单个特征图中所有锚点的坐标和尺寸信息(未与原图做除法)
-
feat_shape,
-
sizes,
-
ratios,
-
step,
-
offset=0.5,
-
dtype=np.float32):
-
"""Computer SSD default anchor boxes for one feature layer.
-
-
Determine the relative position grid of the centers, and the relative
-
width and height.
-
-
Arguments:
-
feat_shape: Feature shape, used for computing relative position grids;
-
size: Absolute reference sizes;
-
ratios: Ratios to use on these features;
-
img_shape: Image shape, used for computing height, width relatively to the
-
former;
-
offset: Grid offset.
-
-
Return:
-
y, x, h, w: Relative x and y grids, and height and width.
-
"""
-
# Compute the position grid: simple way.
-
# y, x = np.mgrid[0:feat_shape[0], 0:feat_shape[1]]
-
# y = (y.astype(dtype) + offset) / feat_shape[0]
-
# x = (x.astype(dtype) + offset) / feat_shape[1]
-
# Weird SSD-Caffe computation using steps values... #归一化到原图的锚点中心坐标(x,y);其坐标值域为(0,1)
-
y, x = np.mgrid[
0:feat_shape[
0],
0:feat_shape[
1]]
#对于第一个特征图(block4:38x38);y=[[0,0,……0],[1,1,……1],……[37,37,……,37]];而x=[[0,1,2……,37],[0,1,2……,37],……[0,1,2……,37]]
-
y = (y.astype(dtype) + offset) * step / img_shape[
0]
#将38个cell对应锚点框的y坐标偏移至每个cell中心,然后乘以相对原图缩放的比例,再除以原图
-
x = (x.astype(dtype) + offset) * step / img_shape[
1]
#可以得到在原图上,相对原图比例大小的每个锚点中心坐标x,y
-
-
# Expand dims to support easy broadcasting. #将锚点中心坐标扩大维度
-
y = np.expand_dims(y, axis=
-1)
#对于第一个特征图,y的shape=38x38x1;x的shape=38x38x1
-
x = np.expand_dims(x, axis=
-1)
-
-
# Compute relative height and width.
-
# Tries to follow the original implementation of SSD for the order.
-
num_anchors = len(sizes) + len(ratios)
#该特征图上每个点对应的锚点框数量;如:对于第一个特征图每个点预测4个锚点框(block4:38x38),2+2=4
-
h = np.zeros((num_anchors, ), dtype=dtype)
#对于第一个特征图,h的shape=4x;w的shape=4x
-
w = np.zeros((num_anchors, ), dtype=dtype)
-
# Add first anchor boxes with ratio=1.
-
h[
0] = sizes[
0] / img_shape[
0]
#第一个锚点框的高h[0]=起始锚点的高/原图大小的高;例如:h[0]=21/300
-
w[
0] = sizes[
0] / img_shape[
1]
#第一个锚点框的宽w[0]=起始锚点的宽/原图大小的宽;例如:w[0]=21/300
-
di =
1
#锚点宽个数偏移
-
if len(sizes) >
1:
-
h[
1] = math.sqrt(sizes[
0] * sizes[
1]) / img_shape[
0]
#第二个锚点框的高h[1]=sqrt(起始锚点的高*起始锚点的宽)/原图大小的高;例如:h[1]=sqrt(21*45)/300
-
w[
1] = math.sqrt(sizes[
0] * sizes[
1]) / img_shape[
1]
#第二个锚点框的高w[1]=sqrt(起始锚点的高*起始锚点的宽)/原图大小的宽;例如:w[1]=sqrt(21*45)/300
-
di +=
1
#di=2
-
for i, r
in enumerate(ratios):
#遍历长宽比例,第一个特征图,r只有两个,2和0.5;共四个锚点宽size(h[0]~h[3])
-
h[i+di] = sizes[
0] / img_shape[
0] / math.sqrt(r)
#例如:对于第一个特征图,h[0+2]=h[2]=21/300/sqrt(2);w[0+2]=w[2]=45/300*sqrt(2)
-
w[i+di] = sizes[
0] / img_shape[
1] * math.sqrt(r)
#例如:对于第一个特征图,h[1+2]=h[3]=21/300/sqrt(0.5);w[1+2]=w[3]=45/300*sqrt(0.5)
-
return y, x, h, w
#返回没有归一化前的锚点坐标和尺寸
-
-
-
def ssd_anchors_all_layers(img_shape, #检测所有特征图中锚点框的四个坐标信息; 输入原始图大小
-
layers_shape, #每个特征层形状尺寸
-
anchor_sizes, #起始特征图中框的长宽size
-
anchor_ratios, #锚点框长宽比列表
-
anchor_steps, #锚点框相对原图缩放比例
-
offset=0.5, #锚点中心在每个特征图cell中的偏移
-
dtype=np.float32):
-
"""Compute anchor boxes for all feature layers.
-
"""
-
layers_anchors = []
#用于存放所有特征图中锚点框位置尺寸信息
-
for i, s
in enumerate(layers_shape):
#6个特征图尺寸;如:第0个是38x38
-
anchor_bboxes = ssd_anchor_one_layer(img_shape, s,
#分别计算每个特征图中锚点框的位置尺寸信息;
-
anchor_sizes[i],
#输入:第i个特征图中起始锚点框大小;如第0个是(21., 45.)
-
anchor_ratios[i],
#输入:第i个特征图中锚点框长宽比列表;如第0个是[2, .5]
-
anchor_steps[i],
#输入:第i个特征图中锚点框相对原始图的缩放比;如第0个是8
-
offset=offset, dtype=dtype)
#输入:锚点中心在每个特征图cell中的偏移
-
layers_anchors.append(anchor_bboxes)
#将6个特征图中每个特征图上的点对应的锚点框(6个或4个)保存
-
return layers_anchors
-
-
-
# =========================================================================== #
-
# Functional definition of VGG-based SSD 300.
-
# =========================================================================== #
-
def tensor_shape(x, rank=3):
-
"""Returns the dimensions of a tensor.
-
Args:
-
image: A N-D Tensor of shape.
-
Returns:
-
A list of dimensions. Dimensions that are statically known are python
-
integers,otherwise they are integer scalar tensors.
-
"""
-
if x.get_shape().is_fully_defined():
-
return x.get_shape().as_list()
-
else:
-
static_shape = x.get_shape().with_rank(rank).as_list()
-
dynamic_shape = tf.unstack(tf.shape(x), rank)
-
return [s
if s
is
not
None
else d
-
for s, d
in zip(static_shape, dynamic_shape)]
-
-
-
def ssd_multibox_layer(inputs, #输入特征层
-
num_classes, #类别数
-
sizes, #参考先验框的尺度
-
ratios=[1], #默认的先验框长宽比为1
-
normalization=-1, #默认不做正则化
-
bn_normalization=False):
-
"""Construct a multibox layer, return a class and localization predictions.
-
"""
-
net = inputs
-
if normalization >
0:
#如果输入整数,则进行L2正则化
-
net = custom_layers.l2_normalization(net, scaling=
True)
#对通道所在维度进行正则化,随后乘以gamma缩放系数
-
# Number of anchors.
-
num_anchors = len(sizes) + len(ratios)
#每层特征图参考先验框的个数[4,6,6,6,4,4]
-
-
# Location. #每个先验框对应4个坐标信息
-
num_loc_pred = num_anchors *
4
#特征图上每个单元预测的坐标所需维度=锚点框数*4
-
loc_pred = slim.conv2d(net, num_loc_pred, [
3,
3], activation_fn=
None,
#通过对特征图进行3x3卷积得到位置信息和类别权重信息
-
scope=
'conv_loc')
#该部分是定位信息,输出维度为[特征图h,特征图w,每个单元所有锚点框坐标]
-
loc_pred = custom_layers.channel_to_last(loc_pred)
-
loc_pred = tf.reshape(loc_pred,
#最后整个特征图所有锚点框预测目标位置 tensor为[h*w*每个cell先验框数,4]
-
tensor_shape(loc_pred,
4)[:
-1]+[num_anchors,
4])
-
# Class prediction. #类别预测
-
num_cls_pred = num_anchors * num_classes
#特征图上每个单元预测的类别所需维度=锚点框数*种类数
-
cls_pred = slim.conv2d(net, num_cls_pred, [
3,
3], activation_fn=
None,
#该部分是类别信息,输出维度为[特征图h,特征图w,每个单元所有锚点框对应类别信息]
-
scope=
'conv_cls')
-
cls_pred = custom_layers.channel_to_last(cls_pred)
-
cls_pred = tf.reshape(cls_pred,
-
tensor_shape(cls_pred,
4)[:
-1]+[num_anchors, num_classes])
#最后整个特征图所有锚点框预测类别 tensor为[h*w*每个cell先验框数,种类数]
-
return cls_pred, loc_pred
#返回预测得到的类别和box位置 tensor
-
-
-
def ssd_net(inputs, #定义ssd网络结构
-
num_classes=SSDNet.default_params.num_classes, #分类数
-
feat_layers=SSDNet.default_params.feat_layers, #特征层
-
anchor_sizes=SSDNet.default_params.anchor_sizes,
-
anchor_ratios=SSDNet.default_params.anchor_ratios,
-
normalizations=SSDNet.default_params.normalizations, #正则化
-
is_training=True,
-
dropout_keep_prob=0.5,
-
prediction_fn=slim.softmax,
-
reuse=None,
-
scope='ssd_300_vgg'):
-
"""SSD net definition.
-
"""
-
# if data_format == 'NCHW':
-
# inputs = tf.transpose(inputs, perm=(0, 3, 1, 2))
-
-
# End_points collect relevant activations for external use.
-
end_points = {}
#用于收集每一层输出结果
-
with tf.variable_scope(scope,
'ssd_300_vgg', [inputs], reuse=reuse):
-
# Original VGG-16 blocks.
-
net = slim.repeat(inputs,
2, slim.conv2d,
64, [
3,
3], scope=
'conv1')
#VGG16网络的第一个conv,重复2次卷积,核为3x3,64个特征
-
end_points[
'block1'] = net
#conv1_2结果存入end_points,name='block1'
-
net = slim.max_pool2d(net, [
2,
2], scope=
'pool1')
-
# Block 2.
-
net = slim.repeat(net,
2, slim.conv2d,
128, [
3,
3], scope=
'conv2')
#重复2次卷积,核为3x3,128个特征
-
end_points[
'block2'] = net
#conv2_2结果存入end_points,name='block2'
-
net = slim.max_pool2d(net, [
2,
2], scope=
'pool2')
-
# Block 3.
-
net = slim.repeat(net,
3, slim.conv2d,
256, [
3,
3], scope=
'conv3')
#重复3次卷积,核为3x3,256个特征
-
end_points[
'block3'] = net
#conv3_3结果存入end_points,name='block3'
-
net = slim.max_pool2d(net, [
2,
2], scope=
'pool3')
-
# Block 4.
-
net = slim.repeat(net,
3, slim.conv2d,
512, [
3,
3], scope=
'conv4')
#重复3次卷积,核为3x3,512个特征
-
end_points[
'block4'] = net
#conv4_3结果存入end_points,name='block4'
-
net = slim.max_pool2d(net, [
2,
2], scope=
'pool4')
-
# Block 5.
-
net = slim.repeat(net,
3, slim.conv2d,
512, [
3,
3], scope=
'conv5')
#重复3次卷积,核为3x3,512个特征
-
end_points[
'block5'] = net
#conv5_3结果存入end_points,name='block5'
-
net = slim.max_pool2d(net, [
3,
3], stride=
1, scope=
'pool5')
-
-
# Additional SSD blocks. #去掉了VGG的全连接层
-
# Block 6: let's dilate the hell out of it!
-
net = slim.conv2d(net,
1024, [
3,
3], rate=
6, scope=
'conv6')
#将VGG基础网络最后的池化层结果做扩展卷积(带孔卷积);
-
end_points[
'block6'] = net
#conv6结果存入end_points,name='block6'
-
net = tf.layers.dropout(net, rate=dropout_keep_prob, training=is_training)
#dropout层
-
# Block 7: 1x1 conv. Because the fuck.
-
net = slim.conv2d(net,
1024, [
1,
1], scope=
'conv7')
#将dropout后的网络做1x1卷积,输出1024特征,name='block7'
-
end_points[
'block7'] = net
-
net = tf.layers.dropout(net, rate=dropout_keep_prob, training=is_training)
#将卷积后的网络继续做dropout
-
-
# Block 8/9/10/11: 1x1 and 3x3 convolutions stride 2 (except lasts).
-
end_point =
'block8'
-
with tf.variable_scope(end_point):
-
net = slim.conv2d(net,
256, [
1,
1], scope=
'conv1x1')
#对上述dropout的网络做1x1卷积,然后做3x3卷积,,输出512特征图,name=‘block8’
-
net = custom_layers.pad2d(net, pad=(
1,
1))
-
net = slim.conv2d(net,
512, [
3,
3], stride=
2, scope=
'conv3x3', padding=
'VALID')
-
end_points[end_point] = net
-
end_point =
'block9'
-
with tf.variable_scope(end_point):
-
net = slim.conv2d(net,
128, [
1,
1], scope=
'conv1x1')
#对上述网络做1x1卷积,然后做3x3卷积,输出256特征图,name=‘block9’
-
net = custom_layers.pad2d(net, pad=(
1,
1))
-
net = slim.conv2d(net,
256, [
3,
3], stride=
2, scope=
'conv3x3', padding=
'VALID')
-
end_points[end_point] = net
-
end_point =
'block10'
-
with tf.variable_scope(end_point):
-
net = slim.conv2d(net,
128, [
1,
1], scope=
'conv1x1')
#对上述网络做1x1卷积,然后做3x3卷积,输出256特征图,name=‘block10’
-
net = slim.conv2d(net,
256, [
3,
3], scope=
'conv3x3', padding=
'VALID')
-
end_points[end_point] = net
-
end_point =
'block11'
-
with tf.variable_scope(end_point):
-
net = slim.conv2d(net,
128, [
1,
1], scope=
'conv1x1')
#对上述网络做1x1卷积,然后做3x3卷积,输出256特征图,name=‘block11’
-
net = slim.conv2d(net,
256, [
3,
3], scope=
'conv3x3', padding=
'VALID')
-
end_points[end_point] = net
-
-
# Prediction and localisations layers. #预测和定位
-
predictions = []
-
logits = []
-
localisations = []
-
for i, layer
in enumerate(feat_layers):
#遍历特征层
-
with tf.variable_scope(layer +
'_box'):
#起个命名范围
-
p, l = ssd_multibox_layer(end_points[layer],
#做多尺度大小box预测的特征层,返回每个cell中每个先验框预测的类别p和预测的位置l
-
num_classes,
#种类数
-
anchor_sizes[i],
#先验框尺度(同一特征图上的先验框尺度和长宽比一致)
-
anchor_ratios[i],
#先验框长宽比
-
normalizations[i])
#每个特征正则化信息,目前是只对第一个特征图做归一化操作;
-
#把每一层的预测收集
-
predictions.append(prediction_fn(p))
#prediction_fn为softmax,预测类别
-
logits.append(p)
#把每个cell每个先验框预测的类别的概率值存在logits中
-
localisations.append(l)
#预测位置信息
-
-
return predictions, localisations, logits, end_points
#返回类别预测结果,位置预测结果,所属某个类别的概率值,以及特征层
-
ssd_net.default_image_size =
300
-
-
-
def ssd_arg_scope(weight_decay=0.0005, data_format='NHWC'):
#权重衰减系数=0.0005;其是L2正则化项的系数
-
"""Defines the VGG arg scope.
-
-
Args:
-
weight_decay: The l2 regularization coefficient.
-
-
Returns:
-
An arg_scope.
-
"""
-
with slim.arg_scope([slim.conv2d, slim.fully_connected],
-
activation_fn=tf.nn.relu,
-
weights_regularizer=slim.l2_regularizer(weight_decay),
-
weights_initializer=tf.contrib.layers.xavier_initializer(),
-
biases_initializer=tf.zeros_initializer()):
-
with slim.arg_scope([slim.conv2d, slim.max_pool2d],
-
padding=
'SAME',
-
data_format=data_format):
-
with slim.arg_scope([custom_layers.pad2d,
-
custom_layers.l2_normalization,
-
custom_layers.channel_to_last],
-
data_format=data_format)
as sc:
-
return sc
-
-
-
# =========================================================================== #
-
# Caffe scope: importing weights at initialization.
-
# =========================================================================== #
-
def ssd_arg_scope_caffe(caffe_scope):
-
"""Caffe scope definition.
-
-
Args:
-
caffe_scope: Caffe scope object with loaded weights.
-
-
Returns:
-
An arg_scope.
-
"""
-
# Default network arg scope.
-
with slim.arg_scope([slim.conv2d],
-
activation_fn=tf.nn.relu,
-
weights_initializer=caffe_scope.conv_weights_init(),
-
biases_initializer=caffe_scope.conv_biases_init()):
-
with slim.arg_scope([slim.fully_connected],
-
activation_fn=tf.nn.relu):
-
with slim.arg_scope([custom_layers.l2_normalization],
-
scale_initializer=caffe_scope.l2_norm_scale_init()):
-
with slim.arg_scope([slim.conv2d, slim.max_pool2d],
-
padding=
'SAME')
as sc:
-
return sc
-
-
-
# =========================================================================== #
-
# SSD loss function.
-
# =========================================================================== #
-
def ssd_losses(logits, localisations, #损失函数定义为位置误差和置信度误差的加权和;
-
gclasses, glocalisations, gscores,
-
match_threshold=0.5,
-
negative_ratio=3.,
-
alpha=1., #位置误差权重系数
-
label_smoothing=0.,
-
device='/cpu:0',
-
scope=None):
-
with tf.name_scope(scope,
'ssd_losses'):
-
lshape = tfe.get_shape(logits[
0],
5)
-
num_classes = lshape[
-1]
-
batch_size = lshape[
0]
-
-
# Flatten out all vectors!
-
flogits = []
-
fgclasses = []
-
fgscores = []
-
flocalisations = []
-
fglocalisations = []
-
for i
in range(len(logits)):
-
flogits.append(tf.reshape(logits[i], [
-1, num_classes]))
#将类别的概率值reshape成(-1,21)
-
fgclasses.append(tf.reshape(gclasses[i], [
-1]))
#真实类别
-
fgscores.append(tf.reshape(gscores[i], [
-1]))
#预测真实目标的得分
-
flocalisations.append(tf.reshape(localisations[i], [
-1,
4]))
#预测真实目标边框坐标(编码形式的值)
-
fglocalisations.append(tf.reshape(glocalisations[i], [
-1,
4]))
#用于将真实目标gt的坐标进行编码存储
-
# And concat the crap!
-
logits = tf.concat(flogits, axis=
0)
-
gclasses = tf.concat(fgclasses, axis=
0)
-
gscores = tf.concat(fgscores, axis=
0)
-
localisations = tf.concat(flocalisations, axis=
0)
-
glocalisations = tf.concat(fglocalisations, axis=
0)
-
dtype = logits.dtype
-
-
# Compute positive matching mask...
-
pmask = gscores > match_threshold
#预测框与真实框IOU>0.5则将这个先验作为正样本
-
fpmask = tf.cast(pmask, dtype)
-
n_positives = tf.reduce_sum(fpmask)
#求正样本数量N
-
-
# Hard negative mining... 为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3
-
no_classes = tf.cast(pmask, tf.int32)
-
predictions = slim.softmax(logits)
#类别预测
-
nmask = tf.logical_and(tf.logical_not(pmask),
-
gscores >
-0.5)
-
fnmask = tf.cast(nmask, dtype)
-
nvalues = tf.where(nmask,
-
predictions[:,
0],
-
1. - fnmask)
-
nvalues_flat = tf.reshape(nvalues, [
-1])
-
# Number of negative entries to select.
-
max_neg_entries = tf.cast(tf.reduce_sum(fnmask), tf.int32)
-
n_neg = tf.cast(negative_ratio * n_positives, tf.int32) + batch_size
#负样本数量,保证是正样本3倍
-
n_neg = tf.minimum(n_neg, max_neg_entries)
-
-
val, idxes = tf.nn.top_k(-nvalues_flat, k=n_neg)
#抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本
-
max_hard_pred = -val[
-1]
-
# Final negative mask.
-
nmask = tf.logical_and(nmask, nvalues < max_hard_pred)
-
fnmask = tf.cast(nmask, dtype)
-
-
# Add cross-entropy loss. #交叉熵
-
with tf.name_scope(
'cross_entropy_pos'):
-
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
#类别置信度误差
-
labels=gclasses)
-
loss = tf.div(tf.reduce_sum(loss * fpmask), batch_size, name=
'value')
#将置信度误差除以正样本数后除以batch-size
-
tf.losses.add_loss(loss)
-
-
with tf.name_scope(
'cross_entropy_neg'):
-
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
-
labels=no_classes)
-
loss = tf.div(tf.reduce_sum(loss * fnmask), batch_size, name=
'value')
-
tf.losses.add_loss(loss)
-
-
# Add localization loss: smooth L1, L2, ...
-
with tf.name_scope(
'localization'):
-
# Weights Tensor: positive mask + random negative.
-
weights = tf.expand_dims(alpha * fpmask, axis=
-1)
-
loss = custom_layers.abs_smooth(localisations - glocalisations)
#先验框对应边界的位置预测值-真实位置;然后做Smooth L1 loss
-
loss = tf.div(tf.reduce_sum(loss * weights), batch_size, name=
'value')
#将上面的loss*权重(=alpha/正样本数)求和后除以batch-size
-
tf.losses.add_loss(loss)
#获得置信度误差和位置误差的加权和
-
-
-
def ssd_losses_old(logits, localisations,
-
gclasses, glocalisations, gscores,
-
match_threshold=0.5,
-
negative_ratio=3.,
-
alpha=1.,
-
label_smoothing=0.,
-
device='/cpu:0',
-
scope=None):
-
"""Loss functions for training the SSD 300 VGG network.
-
-
This function defines the different loss components of the SSD, and
-
adds them to the TF loss collection.
-
-
Arguments:
-
logits: (list of) predictions logits Tensors;
-
localisations: (list of) localisations Tensors;
-
gclasses: (list of) groundtruth labels Tensors;
-
glocalisations: (list of) groundtruth localisations Tensors;
-
gscores: (list of) groundtruth score Tensors;
-
"""
-
with tf.device(device):
-
with tf.name_scope(scope,
'ssd_losses'):
-
l_cross_pos = []
-
l_cross_neg = []
-
l_loc = []
-
for i
in range(len(logits)):
-
dtype = logits[i].dtype
-
with tf.name_scope(
'block_%i' % i):
-
# Sizing weight...
-
wsize = tfe.get_shape(logits[i], rank=
5)
-
wsize = wsize[
1] * wsize[
2] * wsize[
3]
-
-
# Positive mask.
-
pmask = gscores[i] > match_threshold
-
fpmask = tf.cast(pmask, dtype)
-
n_positives = tf.reduce_sum(fpmask)
-
-
# Select some random negative entries.
-
# n_entries = np.prod(gclasses[i].get_shape().as_list())
-
# r_positive = n_positives / n_entries
-
# r_negative = negative_ratio * n_positives / (n_entries - n_positives)
-
-
# Negative mask.
-
no_classes = tf.cast(pmask, tf.int32)
-
predictions = slim.softmax(logits[i])
-
nmask = tf.logical_and(tf.logical_not(pmask),
-
gscores[i] >
-0.5)
-
fnmask = tf.cast(nmask, dtype)
-
nvalues = tf.where(nmask,
-
predictions[:, :, :, :,
0],
-
1. - fnmask)
-
nvalues_flat = tf.reshape(nvalues, [
-1])
-
# Number of negative entries to select.
-
n_neg = tf.cast(negative_ratio * n_positives, tf.int32)
-
n_neg = tf.maximum(n_neg, tf.size(nvalues_flat) //
8)
-
n_neg = tf.maximum(n_neg, tf.shape(nvalues)[
0] *
4)
-
max_neg_entries =
1 + tf.cast(tf.reduce_sum(fnmask), tf.int32)
-
n_neg = tf.minimum(n_neg, max_neg_entries)
-
-
val, idxes = tf.nn.top_k(-nvalues_flat, k=n_neg)
-
max_hard_pred = -val[
-1]
-
# Final negative mask.
-
nmask = tf.logical_and(nmask, nvalues < max_hard_pred)
-
fnmask = tf.cast(nmask, dtype)
-
-
# Add cross-entropy loss.
-
with tf.name_scope(
'cross_entropy_pos'):
-
fpmask = wsize * fpmask
-
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits[i],
-
labels=gclasses[i])
-
loss = tf.losses.compute_weighted_loss(loss, fpmask)
-
l_cross_pos.append(loss)
-
-
with tf.name_scope(
'cross_entropy_neg'):
-
fnmask = wsize * fnmask
-
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits[i],
-
labels=no_classes)
-
loss = tf.losses.compute_weighted_loss(loss, fnmask)
-
l_cross_neg.append(loss)
-
-
# Add localization loss: smooth L1, L2, ...
-
with tf.name_scope(
'localization'):
-
# Weights Tensor: positive mask + random negative.
-
weights = tf.expand_dims(alpha * fpmask, axis=
-1)
-
loss = custom_layers.abs_smooth(localisations[i] - glocalisations[i])
-
loss = tf.losses.compute_weighted_loss(loss, weights)
-
l_loc.append(loss)
-
-
# Additional total losses...
-
with tf.name_scope(
'total'):
-
total_cross_pos = tf.add_n(l_cross_pos,
'cross_entropy_pos')
-
total_cross_neg = tf.add_n(l_cross_neg,
'cross_entropy_neg')
-
total_cross = tf.add(total_cross_pos, total_cross_neg,
'cross_entropy')
-
total_loc = tf.add_n(l_loc,
'localization')
-
-
# Add to EXTRA LOSSES TF.collection
-
tf.add_to_collection(
'EXTRA_LOSSES', total_cross_pos)
-
tf.add_to_collection(
'EXTRA_LOSSES', total_cross_neg)
-
tf.add_to_collection(
'EXTRA_LOSSES', total_cross)
-
tf.add_to_collection(
'EXTRA_LOSSES', total_loc)
其中custom_layers.py的代码解析如下:
-
# Copyright 2015 Paul Balanca. All Rights Reserved.
-
#
-
# Licensed under the Apache License, Version 2.0 (the "License");
-
# you may not use this file except in compliance with the License.
-
# You may obtain a copy of the License at
-
#
-
# http://www.apache.org/licenses/LICENSE-2.0
-
#
-
# Unless required by applicable law or agreed to in writing, software
-
# distributed under the License is distributed on an "AS IS" BASIS,
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-
# See the License for the specific language governing permissions and
-
# limitations under the License.
-
# ==============================================================================
-
"""Implement some custom layers, not provided by TensorFlow.
-
-
Trying to follow as much as possible the style/standards used in
-
tf.contrib.layers
-
"""
-
import tensorflow
as tf
-
-
from tensorflow.contrib.framework.python.ops
import add_arg_scope
-
from tensorflow.contrib.layers.python.layers
import initializers
-
from tensorflow.contrib.framework.python.ops
import variables
-
from tensorflow.contrib.layers.python.layers
import utils
-
from tensorflow.python.ops
import nn
-
from tensorflow.python.ops
import init_ops
-
from tensorflow.python.ops
import variable_scope
-
-
-
def abs_smooth(x):
-
"""Smoothed absolute function. Useful to compute an L1 smooth error. 当预测值与目标值相差很大时, 梯度容易爆炸,因此L1 loss对噪声(outliers)更鲁棒
-
-
Define as:
-
x^2 / 2 if abs(x) < 1
-
abs(x) - 0.5 if abs(x) > 1
-
We use here a differentiable definition using min(x) and abs(x). Clearly
-
not optimal, but good enough for our purpose!
-
"""
-
absx = tf.abs(x)
-
minx = tf.minimum(absx,
1)
-
r =
0.5 * ((absx -
1) * minx + absx)
#计算得到L1 smooth loss
-
return r
-
-
-
@add_arg_scope
-
def l2_normalization( #L2正则化:稀疏正则化操作
-
inputs, #输入特征层,[batch_size,h,w,c]
-
scaling=False, #默认归一化后是否设置缩放变量gamma
-
scale_initializer=init_ops.ones_initializer(), #scale初始化为1
-
reuse=None,
-
variables_collections=None,
-
outputs_collections=None,
-
data_format='NHWC',
-
trainable=True,
-
scope=None):
-
"""Implement L2 normalization on every feature (i.e. spatial normalization).
-
-
Should be extended in some near future to other dimensions, providing a more
-
flexible normalization framework.
-
-
Args:
-
inputs: a 4-D tensor with dimensions [batch_size, height, width, channels].
-
scaling: whether or not to add a post scaling operation along the dimensions
-
which have been normalized.
-
scale_initializer: An initializer for the weights.
-
reuse: whether or not the layer and its variables should be reused. To be
-
able to reuse the layer scope must be given.
-
variables_collections: optional list of collections for all the variables or
-
a dictionary containing a different list of collection per variable.
-
outputs_collections: collection to add the outputs.
-
data_format: NHWC or NCHW data format.
-
trainable: If `True` also add variables to the graph collection
-
`GraphKeys.TRAINABLE_VARIABLES` (see tf.Variable).
-
scope: Optional scope for `variable_scope`.
-
Returns:
-
A `Tensor` representing the output of the operation.
-
"""
-
-
with variable_scope.variable_scope(
-
scope,
'L2Normalization', [inputs], reuse=reuse)
as sc:
-
inputs_shape = inputs.get_shape()
#得到输入特征层的维度信息
-
inputs_rank = inputs_shape.ndims
#维度数=4
-
dtype = inputs.dtype.base_dtype
#数据类型
-
if data_format ==
'NHWC':
-
# norm_dim = tf.range(1, inputs_rank-1)
-
norm_dim = tf.range(inputs_rank
-1, inputs_rank)
#需要正则化的维度是4-1=3即channel这个维度
-
params_shape = inputs_shape[
-1:]
#通道数
-
elif data_format ==
'NCHW':
-
# norm_dim = tf.range(2, inputs_rank)
-
norm_dim = tf.range(
1,
2)
#需要正则化的维度是第1维,即channel这个维度
-
params_shape = (inputs_shape[
1])
#通道数
-
-
# Normalize along spatial dimensions.
-
outputs = nn.l2_normalize(inputs, norm_dim, epsilon=
1e-12)
#对通道所在维度进行正则化,其中epsilon是避免除0风险
-
# Additional scaling.
-
if scaling:
#判断是否对正则化后设置缩放变量
-
scale_collections = utils.get_variable_collections(
-
variables_collections,
'scale')
-
scale = variables.model_variable(
'gamma',
-
shape=params_shape,
-
dtype=dtype,
-
initializer=scale_initializer,
-
collections=scale_collections,
-
trainable=trainable)
-
if data_format ==
'NHWC':
-
outputs = tf.multiply(outputs, scale)
-
elif data_format ==
'NCHW':
-
scale = tf.expand_dims(scale, axis=
-1)
-
scale = tf.expand_dims(scale, axis=
-1)
-
outputs = tf.multiply(outputs, scale)
-
# outputs = tf.transpose(outputs, perm=(0, 2, 3, 1))
-
-
return utils.collect_named_outputs(outputs_collections,
#即返回L2_norm*gamma
-
sc.original_name_