lucene学习(一)


对于搜索,按被搜索的资源类型,分为两种:可以转为文本和多媒体类型。
1.2.什么是全文检索
全文检索(Full-Text Retrieval)是指以文本作为检索对象,找出含有指定词汇的文本。全面、准确和快速是衡量全文检索系统的关键指标。
关于全文检索,往往只处理文本,不处理语义。结果列表有相关度排序。并且可以对结果具有过滤高亮等能
1.3.全文检索与数据查询的区别
1).查询的方式与速度: 全文检索的速度大大快于SQL
(解释:lucene利用数据库中的数据形成数据文档,然后生成索引库,维护自己的索引表(每个词在哪些文档里面出现过,记录序号,如goods在0,1,2,3序号中出现过,one在0号文档出现过))

2).相关度排序
3).定位不一样
4).其它
1.4.lucene介绍
我们使用Lucene,主要是做站内搜索,即对一个系统内的资源进行搜索。如BBS、BLOG中的文章搜索,网上商店中的商品搜索等。
Lucene是一个软件库,一个开发工具包,而不是一个具有完整特征的搜索应用程序。
它采用的是一种称为反向索引(inverted index)的机制。反向索引简单理解就是维护一个词/短语表,对于这个表中的每个词/短语,都有一个相关信息描述了有哪些文档包含了这个词/短语。这样在用户输入查询条件的时候,就能非常快的得到搜索结果,它本身只关注文本的索引和搜索。Lucene使你可以为你的应用程序添加索引和搜索能力。通过lucene学习,我们就可以为自已的项目增加全文检索的功能。
2.Lucene环境与开发案例
导入的maven依赖:
org.apache.lucene
lucene-core
3.0.0
org.apache.lucene
lucene-queryparser
3.0.0
org.apache.lucene
lucene-highlighter
3.0.0
junit
junit
4.12
实体类Goods(商品)
package com.entity;
import java.io.Serializable;
public class Goods implements Serializable {
private static final long serialVersionUID = 6341267507850856097L;
private Integer goodsId;
private String goodsName;
private Double goodsPrice;
private String goodsRemark;
@Override
public String toString() {
return "Goods [goodsId=" + goodsId + ", goodsName=" + goodsName
+ ", goodsPrice=" + goodsPrice + ", goodsRemark=" + goodsRemark
+ "]";
}
public Integer getGoodsId() {
return goodsId;
}
public void setGoodsId(Integer goodsId) {
this.goodsId = goodsId;
}
public String getGoodsName() {
return goodsName;
}
public void setGoodsName(String goodsName) {
this.goodsName = goodsName;
}
public Double getGoodsPrice() {
return goodsPrice;
}
public void setGoodsPrice(Double goodsPrice) {
this.goodsPrice = goodsPrice;
}
public String getGoodsRemark() {
return goodsRemark;
}
public void setGoodsRemark(String goodsRemark) {
this.goodsRemark = goodsRemark;
}
}
2.3新建索引库操作类
2.3.1新增操作说明
关键步骤与代码解说:
1.构建索引库(首先要创建索引库,把索引库的位置指定,用来存放索引表)
Directory directory = FSDirectory.open(new File(“索引库目录”));
2.指定分词器,版本一般指定为最高(分词器用来分词)
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
3.创建文档对象,并添加相关字段值(因为indexWriter是对文档进行分析,所以要把需要分析的内容转化成Document形式)
Document doc = new Document();
doc.add(newField("goodsId",goods.getGoodsId().toString(),Store.YES,Index.NOT_ANALYZED));
4.创建增删改索引库的操作对象,添加文档并提交(解释:MaxFieldLength.LIMITED表示最多字段个数,IndexWriter把doc文档用analyzer分析完后,存储到directory索引库里面)
IndexWriter indexWriter = new IndexWriter(directory, analyzer, MaxFieldLength.LIMITED);
indexWriter.addDocument(doc);
indexWriter.commit();
5.关闭操作对象
LuceneDaoImpl.java
package com.entity;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriter.MaxFieldLength;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
public class LuceneDaoImpl {
/* 1.构建索引库
Directory directory = FSDirectory.open(new File("索引库目录"));
2.指定分词器,版本一般指定为最高
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
3.创建文档对象,并添加相关字段值
Document doc = new Document();
doc.add(new Field("goodsId",goods.getGoodsId().toString(),Store.YES,Index.NOT_ANALYZED));
4.创建增删改索引库的操作对象,添加文档并提交
IndexWriter indexWriter = new IndexWriter(directory, analyzer, MaxFieldLength.LIMITED);
indexWriter.addDocument(doc);
indexWriter.commit();
5.关闭操作对象*/
/**
* @Title: 保存商品到文档库
* @auth:chufeng
* @Description: TODO(这里用一句话描述这个方法的作用)
* @param @param goods
* @return void 返回类型
*/
public void saveGoods(Goods goods){
IndexWriter indexWriter = null;
try {
Directory directory = FSDirectory.open(new File("d:\\testdir\\lucene35"));
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
Document document = new Document();
//Store.YES表示数据在存到文档库,
//Index.ANALYZED表示按规则进行分词;Index.NO_ANALYZED表示把整体的值作为关键字;Index.NO表示不作为索引
document.add(new Field("goodsId",goods.getGoodsId().toString(),Store.YES,Index.ANALYZED));
document.add(new Field("goodsName",goods.getGoodsName(),Store.YES,Index.ANALYZED));
document.add(new Field("goodsPrice",goods.getGoodsPrice().toString(),Store.YES,Index.ANALYZED));
document.add(new Field("goodsRemark",goods.getGoodsRemark(),Store.YES,Index.ANALYZED));
//通过操作类进行数据的存放
indexWriter = new IndexWriter(directory,analyzer,MaxFieldLength.LIMITED);
indexWriter.addDocument(document);
indexWriter.commit();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
if(indexWriter!=null){
try {
indexWriter.close();
} catch (CorruptIndexException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
/* 1.打开索引库
directory = FSDirectory.open(new File("索引库目录"));
2。创建查询分词器,版本号与写入文档的查询分词器一样
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
3。创建查询解析器,参数为版本号,查询字段名,分词器
QueryParser parser = new QueryParser(Version.LUCENE_30, "goodsName", analyzer);
4。构建查询信息对象
Query query = parser.parse(keyWord);
5。构建查询工具
searcher = new IndexSearcher(directory);
6。通过查询工具执行查询。参数1,查询信息对象;参数2。返回记录数;TopDocs包括总记录数、文档编号等
TopDocs topDocx=searcher.search(query, 20);
7。根据文档编号遍历真正的文档
ScoreDoc sd[] = topDocx.scoreDocs;
for(ScoreDoc scoreDoc:sd){
。。。
Document doc = searcher.doc(scoreDoc.doc);
8。转为java对象 goods.setGoodsId(Integer.parseInt(doc.get("goodsId")));
lists.add(goods);
9.关闭查询操作对象*/
/**
* @Title: 根据商品名称查询商品(列表)
* @auth:chufeng
* @Description: TODO(这里用一句话描述这个方法的作用)
* @param @param keyWord
* @param @return
* @return List 返回类型
*/
public List selectGoods(String keyWord){
List list= new ArrayList();
IndexSearcher indexSearcher = null;
try {
Directory directory = FSDirectory.open(new File("e:\\testdir\\lucene35"));
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
QueryParser parser = new QueryParser(Version.LUCENE_30,"goodsName",analyzer);
Query query = parser.parse(keyWord);
indexSearcher = new IndexSearcher(directory);
TopDocs topDocs = indexSearcher.search(query, 20);
System.out.println("总记录数:"+topDocs.totalHits);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for(ScoreDoc s:scoreDocs){
System.out.println("文档编号:"+s.doc);
//通过文档编号取出文档
Document document = indexSearcher.doc(s.doc);
//把文档对象的值给bean对象
Goods goods = new Goods();
goods.setGoodsId(Integer.parseInt(document.get("goodsId")));
goods.setGoodsName(document.get("goodsName"));
goods.setGoodsPrice(Double.parseDouble(document.get("goodsPrice")));
goods.setGoodsRemark(document.get("goodsRemark"));
list.add(goods);
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
if(indexSearcher!=null){
try {
indexSearcher.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
return list;
}
}
索引库查看工具的使用:
双击该jar包即可打开:

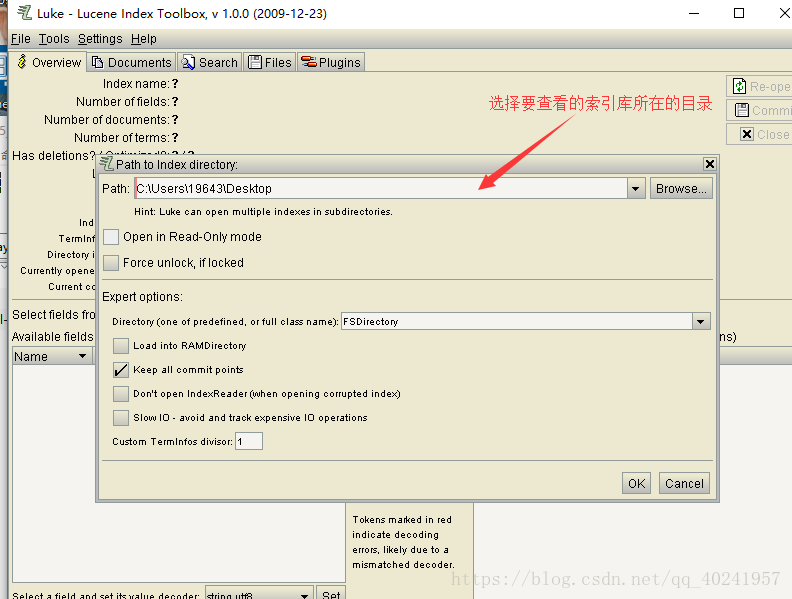
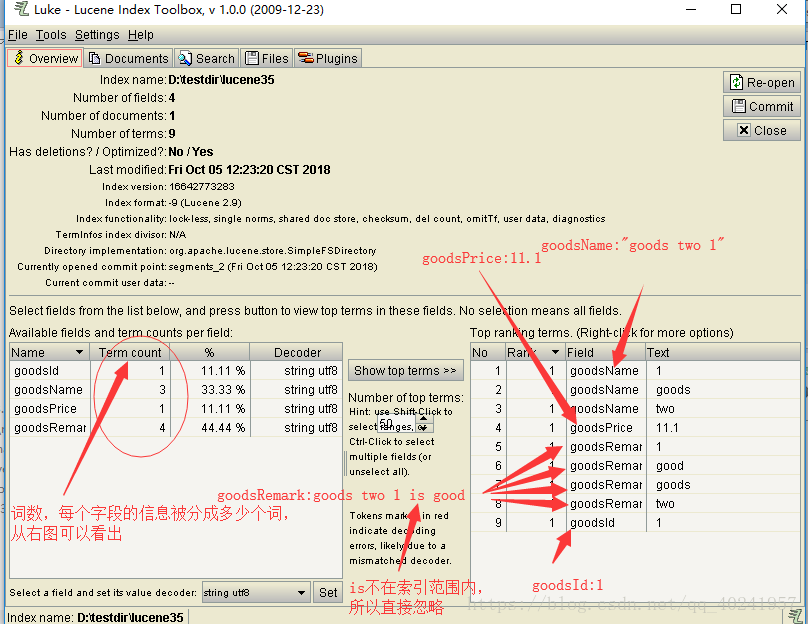
2.3.2查询操作说明
关键步骤与代码解说:
1.打开索引库
directory = FSDirectory.open(new File(“索引库目录”));
2。创建查询分词器,版本号与写入文档的查询分词器一样
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30);
3。创建查询解析器,参数为版本号,查询字段名,分词器
QueryParser parser = new QueryParser(Version.LUCENE_30, “goodsName”, analyzer);
4。构建查询信息对象
Query query = parser.parse(keyWord);
5。构建查询工具
searcher = new IndexSearcher(directory);
6。通过查询工具执行查询。参数1,查询信息对象;参数2。返回记录数;TopDocs包括总记录数、文档重要信息(编号)的列表等
TopDocs topDocx=searcher.search(query, 20);
7。根据文档编号遍历真正的文档
ScoreDoc sd[] = topDocx.scoreDocs;
for(ScoreDoc scoreDoc:sd){
。。。
Document doc = searcher.doc(scoreDoc.doc);
8。转为java对象 goods.setGoodsId(Integer.parseInt(doc.get(“goodsId”)));
lists.add(goods);
9.关闭查询操作对象
示例:
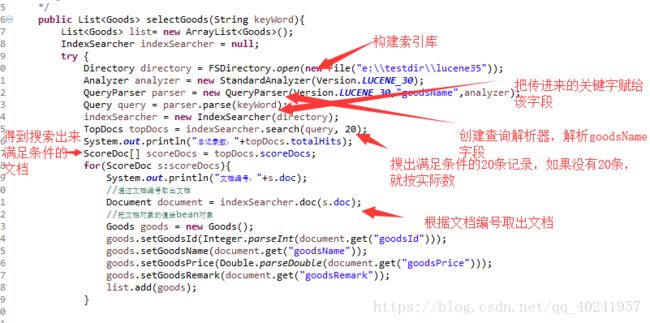
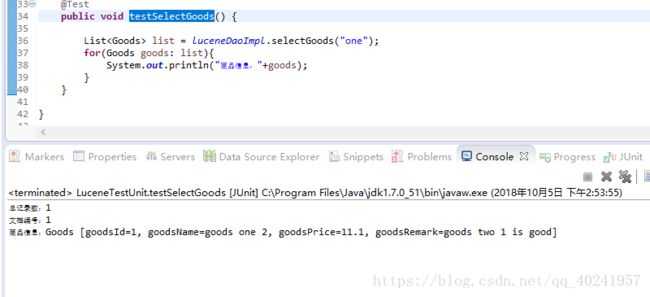
2.6查询过程分析
2.6.1代码处理流程

2.6.2数据处理分析

2.7使用总结
尽量减少不必要的字段存储.
不需要检索的内容不要建立索引.
非文本格式需要提前转化,字符串.
需要整体存放的内容不要分词,例如:ID、价格、专业词.
3.3bean工具类
反射技术实现的
3.1导入包

普通JAVABEAN对象转为DOCUMENT对象,关键代码:
Class clazz = obj.getClass();//根据某对象获取该对象的Class对象
clazz.getDeclaredFields();
(java.lang.reflect.Field)f.setAccessible(true);
(java.lang.reflect.Field)f.getName();
reflectMethod =clazz.getMethod(methodName, null)//获取Method对象,有可能异常
Object returnValue = reflectMethod.invoke(obj, null);// 获取obj对象该方法的返回结果
document.add(new Field(fieldName, returnValue.toString(),
Store.YES, Index.ANALYZED));
可在此基础上自己根据需要再调整或优化代码
public class BeanUtils {
// 普通JAVABEAN对象转为DOCUMENT对象
public static Document beanToDocument(Object obj) throws Exception {
Document document = new Document();
//利用这个方法就可以获得一个实例的类型类,类型类指的是代表一个类型的类.因为一切//皆是对象,类型也不例外,在Java使用类型类来表示一个类型。所有的类型类都是Class类//的实例。
Class clazz = obj.getClass();
//返回 Field 对象的一个数组,这些对象反映此 Class 对象所表示的类或接口所声明的//所有字段。
java.lang.reflect.Field[] reflectFields = clazz.getDeclaredFields();
for (java.lang.reflect.Field f : reflectFields) {
// 设置特权访问
f.setAccessible(true);
// 获取字段名
String fieldName = f.getName();
System.out.println("---------------fieldName:goodsName==getGoodsName()-------------:"
+ fieldName);
// 首写字母变大写,便于后继合成方法名,如getXxx(),Xxx单词的的第一个字母要大写
String init = fieldName.substring(0, 1).toUpperCase();
// 合成get方法
String methodName = "get" + init + fieldName.substring(1);
Method reflectMethod = getMethod(clazz, methodName);
if (reflectMethod != null) {
System.out.println("-----------not null ,methodname-------"
+ reflectMethod);
// 获取方法的返回结果
Object returnValue = reflectMethod.invoke(obj, null);
// 这里需要先对returnValue判断是否为空,以免出现空指针异常。
if (returnValue == null) {
continue;
}
document.add(new Field(fieldName, returnValue.toString(),
Store.YES, Index.ANALYZED));
} else {
System.out.println("----------- null ,methodname-------"
+ reflectMethod);
continue;
}
}
return document;
}
// 通过方法名获取方法,方法不存在返回null
private static Method getMethod(Class clazz, String methodName) {
Method reflectMethod = null;
// try {
// 获取方法,如果不存在,将会抛出异常
try {
//参数1:方法名,参数2:方法中的参数类型,没有参数,指定为null
reflectMethod = clazz.getMethod(methodName, null);
} catch (NoSuchMethodException e) {
// TODO Auto-generated catch block
// e.printStackTrace();
}
// }
return reflectMethod;
}
}
DOCUMENT对象转化为JAVABEAN对象
关键代码说明:
Object obj = clazz.newInstance();//返回class的object对象
java.lang.reflect.Field[] reflectFields = clazz.getDeclaredFields();
f.setAccessible(true);
String fieldName = f.getName();
String fieldValue = document.get(fieldName);
org.apache.commons.beanutils.BeanUtils.setProperty(obj, fieldName,fieldValue);//借助工具,不为空转换到普通java对象
完整示例:
// 将DOCUMENT对象转化为JAVABEAN对象
public static Object documentToBean(Document document, Class clazz)
throws Exception {
Object obj = clazz.newInstance();
java.lang.reflect.Field[] reflectFields = clazz.getDeclaredFields();
for (java.lang.reflect.Field f : reflectFields) {
f.setAccessible(true);
String fieldName = f.getName();
String fieldValue = document.get(fieldName);
System.out.println("beanutil fieldValue:" + fieldValue);
if (fieldValue == null) {
continue;
}
org.apache.commons.beanutils.BeanUtils.setProperty(obj, fieldName,
fieldValue);
}
return obj;
}
4.2.1修改数据
添加修改数据方法:
解释:根据Term字段和字段值到索引库匹配对应的文档,可能有一个或多个document匹配到,把匹配到的document全部删除,然后再添加updateDocument方法的第二个参数doc到索引库里面
indexWriter.updateDocument(new Term(“goodsId”,paramGoods.getGoodsId().toString()), doc);
public void updateGoods(Goods paramGoods){
IndexWriter indexWriter = null;
try {
indexWriter = new IndexWriter(Configuration.DIRECTOTY,Configuration.ANALYZER,MaxFieldLength.LIMITED);
Document doc = BeanUtil.BeanToDocument(paramGoods);
/*
*根据字段的值进行修改数据内容;原则,先删除再添加
*如果字段值不存在,将新增一条记录(文档)
*如果字段值唯一,那就相当 于根据主键修改数据;
*如果字段值对应有多条数据记录(文档),则其它记录(文档)将被逻辑删除后,再添加一记录(文档)
*/
indexWriter.updateDocument(new Term("goodsId",paramGoods.getGoodsId().toString()), doc);
indexWriter.commit();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally{
try {
indexWriter.close();
} catch (CorruptIndexException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
4.3删除数据
4.3.1修改操作类
添加删除方法:
解释:根据deleteDocument方法里的Term字段和字段值匹配索引库里面的document,把匹配到的document全部从索引库删除
indexWriter.deleteDocuments(new Term(“goodsId”,
String.valueOf(goodsId)));
public void deleteGoods(int goodsId) {
IndexWriter indexWriter = null;
try {
indexWriter = new IndexWriter(Configuration.getDIRECTORY(),
Configuration.ANALYZER, MaxFieldLength.LIMITED);
// 参数一:指定处理的字段,参数二:指定关键字(词),如果对应多条记录,多条记录也被删除
indexWriter.deleteDocuments(new Term("goodsId",
String.valueOf(goodsId)));
// 提交事务
indexWriter.commit();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
try {
indexWriter.close();
} catch (CorruptIndexException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}