爬虫02_基于requests的动态加载数据的爬取
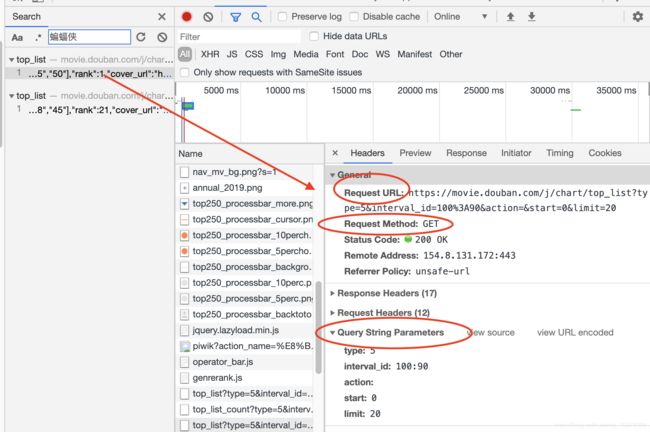
通过抓包工具,基于全局搜索,可以将动态加载数据的数据包定位到
捕获动态加载数据:
- 基于抓包工具进行全局搜索
- 定位到动态加载数据对应的数据包,从改数据包中就可以提取
- 1)请求的
url - 2)请求方式
- 3)请求携带的参数
- 4)看到响应数据
- 1)请求的
.json()方法:将获取到的响应中的字符串形式的json数据以字典或者列表形式返回

项目实战:
- 需求:豆瓣电影分类排行榜中动作电影的电影名称和评分的爬取,练习网址
- 项目代码
import requests
import os
url = 'https://movie.douban.com/j/chart/top_list'
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'
}
params = {
'type': '5',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': '5',
}
response = requests.get(url=url, params=params, headers=headers)
#.json()表示将获取的字符串形式的json数据序列化成字典或者列表
page_text = response.json()
#解析出电影的名称和评分
for movie in page_text:
movie_name = movie['title']
movie_socre = movie['score']
print(movie_name, movie_socre)
思考:为什么基于抓包工具进行全局搜索,不一定100%可以定位到动态加载数据对应的数据包?
原因:如果动态加载的数据是经过加密处理的密文数据,全局搜索是搜不到的,需要前台进行解密,例如js加解密的破解…