R语言使用决策树预测NBA球员投篮结果
1、3种最常见的决策树:
CART分类回归树(classification and regression tree)(一棵二叉树)。每个节点采用二分法(与C4.5最大的区别,c4.5可以有很多分支);用Gini Ratio作为衡量指标,如果分散指标程度很高的说明数据有很多类别。
C4.5。最新有5.0版本;先建完整的决策树;使用自定义的错误率(Predicted Error Rate)对节点修剪。
CHAID 卡方自动交互检验 (Chi-squared Automatic Interaction)。计算节点中类别的p值。根据p值的大小决定决策树是否生长不需要修剪(与前两者的区别)。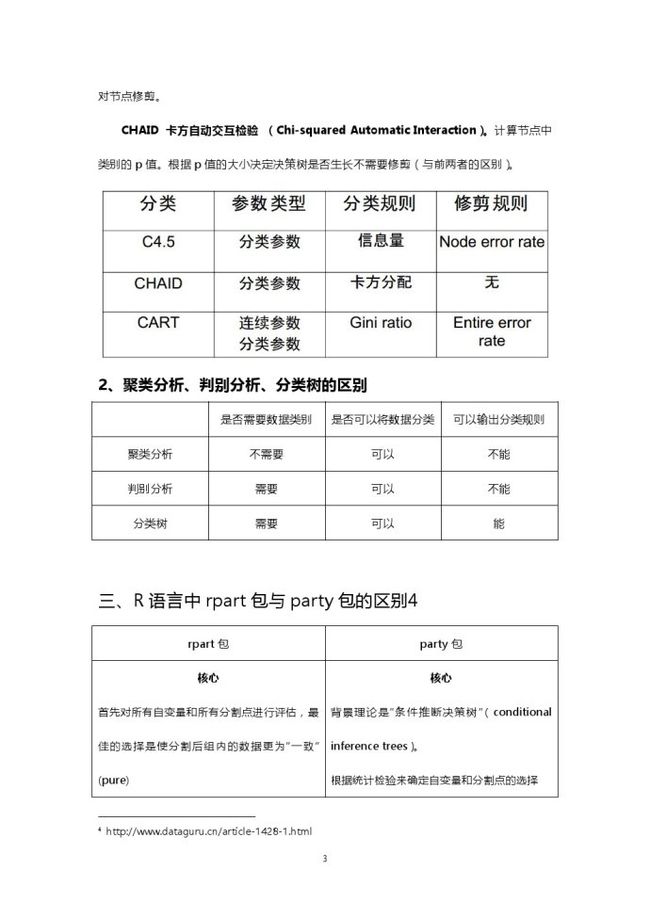

#条件推理决策树(CHAID算法)
#条件推理决策树(CHAID算法)
#探索和收集数据
setwd("D://data")
NBA<-read.table("shot_logs.csv",header = T,sep = ",")#读取数据
set.seed(1234)
hist(NBA$SHOT_DIST)#投球距离的直方图
NBA$SHOT_RESULT <- factor(NBA$SHOT_RESULT, levels=c("made","missed"),
labels=c("命中", "未中")) #分为投中和未投中球
set.seed(1234) #设置随机种子
train <- sample(nrow(NBA), 0.80*nrow(NBA)) #取训练集为80%,验证集为20%
testData <- NBA[train,] #测试集
trainData <- NBA[-train,] #验证集
table(trainData$SHOT_RESULT)
table(testData$SHOT_RESULT) #记录频数的方法
library(party)
#建立决策树模型预测投篮结果
myFormula <- SHOT_RESULT ~ LOCATION+FINAL_MARGIN+PERIOD+DRIBBLES+TOUCH_TIME+SHOT_DIST+PTS_TYPE+CLOSE_DEF_DIST
NBA_ctree <- ctree(myFormula, data=trainData)
# 查看预测的结果
table(predict(NBA_ctree), trainData$SHOT_RESULT)
#画出决策树图
plot(NBA_ctree, type="simple")
#在测试集上做预测
testPred <- predict(NBA_ctree, newdata = testData)
table(testPred, testData$SHOT_RESULT)
correct = sum(as.numeric(testPred)==as.numeric(testData$SHOT_RESULT))/nrow(testData)
correct
#在验证集上做预测
trainPred <- predict(NBA_ctree, newdata = trainData)
table(trainPred, trainData$SHOT_RESULT)
correct = sum(as.numeric(trainPred)==as.numeric(trainData$SHOT_RESULT))/nrow(trainData)
correct
1、CP参数定义
cp: complexity parameter复杂性参数,用来修剪树的.
当决策树复杂度超过一定程度后,随着复杂度的提高,测试集的分类精确度反而会降低。因此,建立的决策树不宜太复杂,需进行剪枝。该剪枝算法依赖于复杂性参数cp,cp随树复杂度的增加而减小,当增加一个节点引起的分类精确度变化量小于树复杂度变化的cp倍时,则须剪去该节点。故建立一棵既能精确分类,又不过度适合的决策树的关键是求解一个合适的cp值。一般选择错判率最小值对应的cp值来修树.
2、CP选择问题。
建立树模型要权衡两方面问题,一个是要拟合得使分组后的变异较小,另一个是要防止过度拟合,而使模型的误差过大,前者的参数是CP,后者的参数是Xerror。所以要在Xerror最小的情况下,也使CP尽量小。
#分类回归树CART
#分类回归树CART
#NBA demo
#探索和收集数据
setwd("D://data")
NBA<-read.table("shot_logs_1.csv",header = T,sep = ",")
str(NBA)#查看表中的特征值
hist(NBA$SHOT_DIST)#投球距离的直方图
NBA$SHOT_RESULT <- factor(NBA$SHOT_RESULT, levels=c("made","missed"),
labels=c("命中", "未中")) #分为投中和未投中球
set.seed(12345) #设置随机种子
train <- sample(nrow(NBA), 0.80*nrow(NBA)) #取训练集为80%,验证集为20%
trainData <- NBA[train,]
testData <- NBA[-train,] #验证集
table(trainData$SHOT_RESULT)
table(testData$SHOT_RESULT) #记录频数的方法
#
library(rpart)
set.seed(12345)
#method="class"离散型:class,
#参数split可以是gini(基尼系数)或者information(信息增益);
#生成一棵树
dtree <- rpart(SHOT_RESULT ~ LOCATION+FINAL_MARGIN+PERIOD+DRIBBLES+TOUCH_TIME+SHOT_DIST+PTS_TYPE+CLOSE_DEF_DIST, data=trainData, method="class",
parms=list(split="information"))
dtree$cptable
#剪枝
plotcp(dtree)
#cp全称为complexity parameter,指某个点的复杂度,对每一步拆分,
#模型的拟合优度必须提高的程度,用来节省剪枝浪费的不必要的时间
NBA_ctree <- prune(dtree, cp=0.01)
library(rpart.plot)
#画决策树
rpart.plot(NBA_ctree, branch=1, branch.type=2, type=1, extra=102,
shadow.col="gray", box.col="green",
border.col="blue", split.col="red",
split.cex=1.2, main="决策树")
#在测试集上做预测
testPred <- predict(NBA_ctree, testData, type="class")
table(testPred, testData$SHOT_RESULT,dnn=c("真实值", "预测值"))
correct = sum(as.numeric(testPred)==as.numeric(testData$SHOT_RESULT))/nrow(testData)
correct
#在验证集上做预测
trainPred <- predict(NBA_ctree, trainData, type="class")
table(trainPred, trainData$SHOT_RESULT,dnn=c("真实值", "预测值"))
correct = sum(as.numeric(trainPred)==as.numeric(trainData$SHOT_RESULT))/nrow(trainData)
correct
#C4.5算法
#C4.5算法
library(RWeka)
library(party)
#探索和收集数据
setwd("D://data")
NBA<-read.table("shot_logs_1.csv",header = T,sep = ",")
NBA$SHOT_RESULT <- factor(NBA$SHOT_RESULT, levels=c("made","missed"),
labels=c("命中", "未中")) #分为投中和未投中球
set.seed(12345) #设置随机种子
train <- sample(nrow(NBA), 0.80*nrow(NBA)) #取训练集为80%,验证集为20%
trainData <- NBA[train,]
testData <- NBA[-train,] #验证集
NBA_ctree<-J48(SHOT_RESULT ~ FINAL_MARGIN+DRIBBLES+TOUCH_TIME+SHOT_DIST+CLOSE_DEF_DIST, data=trainData)
plot(NBA_ctree)
#在测试集上做预测
testPred <- predict(NBA_ctree, newdata = testData)
table(testPred, testData$SHOT_RESULT)
correct = sum(as.numeric(testPred)==as.numeric(testData$SHOT_RESULT))/nrow(testData)
correct
#在验证集上做预测
trainPred <- predict(NBA_ctree, newdata = trainData)
table(trainPred, trainData$SHOT_RESULT)
correct = sum(as.numeric(trainPred)==as.numeric(trainData$SHOT_RESULT))/nrow(trainData)
correct#随机森林
#随机森林
library(randomForest)
#探索和收集数据
setwd("D://data")
NBA<-read.table("shot_logs_1.csv",header = T,sep = ",")
NBA$SHOT_RESULT <- factor(NBA$SHOT_RESULT, levels=c("made","missed"),
labels=c("命中", "未中")) #分为投中和未投中球
set.seed(12345) #设置随机种子
train <- sample(nrow(NBA), 0.80*nrow(NBA)) #取训练集为80%,验证集为20%
trainData <- NBA[train,]
testData <- NBA[-train,] #验证集
rf <- randomForest(SHOT_RESULT ~ DRIBBLES, data=trainData)
NBA_ctree <- randomForest(SHOT_RESULT ~ CLOSE_DEF_DIST, data=trainData, ntree=10, proximity=TRUE)
plot(margin(rf, testData$SHOT_RESULT))
#在测试集上做预测
testPred <- predict(NBA_ctree, testData, type="class")
table(testPred, testData$SHOT_RESULT,dnn=c("真实值", "预测值"))
correct = sum(as.numeric(testPred)==as.numeric(testData$SHOT_RESULT))/nrow(testData)
correct
#在验证集上做预测
trainPred <- predict(NBA_ctree, trainData, type="class")
table(trainPred, trainData$SHOT_RESULT,dnn=c("真实值", "预测值"))
correct = sum(as.numeric(trainPred)==as.numeric(trainData$SHOT_RESULT))/nrow(trainData)
correct
