概率论总结(三):随机变量的数字特征
一、期望与方差
1.期望
(1)期望的计算:
设Y=g(X)
对于离散型:
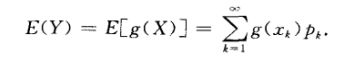
对于连续型:

(2)期望的性质
i. ![]()
ii. ![]()
iii. ![]()
vi. ![]() 当且仅当X,Y相互独立时
当且仅当X,Y相互独立时
2.方差
(1)方差的计算:
![D(X)=E\{[X-E[X]]^2\}\\=E\{X^2-2XE[X]+[E[X]]^2\}\\=E[X^2]-2E[x]E[x]+[E(X)]^2\\=E[X^2]-[E(X)]^2](http://img.e-com-net.com/image/info8/1fb2da38d2ce47fb9b4b0c99c9799d6e.gif)
(2)方差的性质
i. ![]()
ii. ![]()
iii. ![]()
vi.
![D(X+Y)=E\{[(X+Y)-E(X+Y)]^2\}\\=E\{[(X-E(X))+(Y-E(Y))]^2\}\\=E\{(X-E(X))^2\}+E\{(Y-E(Y))^2\}+2E\{[X-E(X)][Y-E(Y)]\}\\=D(X)+D(Y)+2E\{[X-E(X)][Y-E(Y)]](http://img.e-com-net.com/image/info8/8b3deb52ad3649988c304c473243b25c.gif)
![2E\{[X-E(X)][Y-E[Y]]\}\\=2E\{XY-XE[Y]-YE[X]+E[X]E[Y]\}\\= 2\{E(XY)-E[X]E[Y]-E[Y]E[X]+E[X]E[Y]\}\\=2\{E(XY)-E[X]E[Y]\}](http://img.e-com-net.com/image/info8/58eeacc9e8434dc08b7ca10056447f23.gif)
当X,Y相互独立时,由数学期望的性质4可知上式为0,于是
![]()
3.推论
(1)独立随机变量的线性组合的期望和方差,以正态分布为例
若![]()
则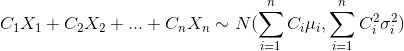
二、切比雪夫不等式和马尔可夫不等式
1.切比雪夫不等式
切比雪夫不等式描述的数字的是,大部分的数据都会分布在均值附近,分布的多少跟方差也有关。
![]()
或者写成以下形式:
![]()
或者写成以下形式:这条式子是我们高中时学的正态分布的三个百分比68.27%,95%,99%的来源
![]()
第三条式子有第一条式子进行变量替换得到,证明见下
2.马尔可夫不等式
![]()
马尔可夫是切比雪夫的学生,是俄罗斯的大数学家,根据他老师提出的切比雪夫不等式,提出了马尔可夫不等式,该不等式可以用来证明了切比雪夫不等式。
3.证明
(1)切比雪夫不等式的证明
这里积分区域一定,所以加上去的![]() , 同时第三个式子推导到第四个式子是因为其积分范围小于负无穷到正无穷,而积分变量是正的,所以积分区域越大,值越大。
, 同时第三个式子推导到第四个式子是因为其积分范围小于负无穷到正无穷,而积分变量是正的,所以积分区域越大,值越大。
(2)马尔可夫不等式的证明
(3)利用马尔可夫推导切比雪夫:

三、协方差及相关系数
1.协方差
(1)协方差的计算
在方差的性质当中,我们有:
![]()
经过上面的推导我们知道,如果X,Y相互独立,那么第三项为0,所以第三项反映了X,Y之间联系的紧密程度。我们把它定义为协方差。
![]()
X和X的协方差也就是它的方差,但在某些领域我们仍把他称为协方差(Coviariance) 。
(2)协方差的性质
![]()
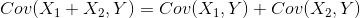
2.相关系数
定义为:
![]()
相关系数也称为Pearson系数,用来衡量两者的相关程度。
四、矩和协方差矩阵
1.矩
(1)物理意义
数学中矩的概念来自物理学。在物理学中,矩是表示距离和物理量乘积的物理量,表征物体的空间分布。由其定义,矩通常需要一个参考点(基点或参考系)来定义距离。如力和参考点距离乘积得到的力矩(或扭矩)。
i.原点矩
有一个船舵,有三个船员都用力转动船舵,不过着手点力臂分别为L1,L2,L3。那么平均力矩是:
![]()
有个问题,如果有个船员反向推动船舵,要怎样衡量大家用力的总能量呢?很简单,将力取平方。比如 L2 对应的力方向相反,则平均能量可以写成:
![]()
1)式即一阶原点矩,2)式即二阶原点矩。所谓一阶二阶,指代的是力矩的阶数。前者衡量的是力矩的平均水平,后者衡量的是能量。所谓“原点”,是因为力矩的计算是指向船舵原点的(也就是L=0),但既然有指向原点的“原点矩”,就有指向其他位置的矩,这种矩叫“中心矩”。
ii.中心矩
这个“中心”,指的是哪里呢?是平均值。为了便于理解,我们将上述例子中的力取相等的F。 那么一阶中心矩就是:
![]()
可见一阶中心矩恒等于零,所以中心矩一般是从二阶开始的。
下面就是二阶中心矩:
![]()
可以看到他就是方差,衡量的是三个力矩的离散程度。
下面总结以下各阶矩
| 名称 | 含义 |
| 一阶原点矩 | 平均值 |
| 二阶原点矩 | 平均能量 |
| 一阶中心矩 | 0 |
| 二阶中心矩 | 方差 |
| 三阶中心矩 | 偏度 |
| 四阶中心矩 | 峭度 |
(2) 数学意义
矩是物体形状识别的重要参数指标。在统计学中,矩表征随机量的分布。如一个“二阶矩”在一维上可测量其“宽度”,在更高阶的维度上由于其使用于橢球的空间分布,我们还可以对点的云结构进行测量和描述。其他矩用来描述诸如与均值的偏差分布情况(偏态),或峰值的分布情况(峰态)
定义在实数域的实函数相对于值c的n阶矩为:
![]()
如果点表示概率密度,则第零阶矩表示总概率(即1),1,2,3阶矩依次为以下三项。数学中的概念与物理学中矩的概念密切相关。
- 期望
随机变量的期望定义为其一阶原点矩: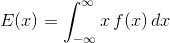
在方差等定义中,期望也成为随机变量的“中心”。
显然,任何随机变量的一阶中心据为0。
对于以下二阶及更高阶的矩,通常使用中心矩(围绕平均值c的矩,均值是一阶矩),而不是原点矩,因为中心矩能更清楚的体现关于分布形状的信息。 - 方差
随机变量的方差定义为其二阶中心矩:![Var(x)=\int_{-\infty}^{\infty} [x-E(x)]^2 \,f(x)\,dx](http://img.e-com-net.com/image/info8/53bc3478ac594603a0495cf236907f8a.gif)
归一化矩
归一化n阶中心矩或者说标准矩,是n阶中心矩除以标准差 σnσn,归一化n阶中心矩为
这些归一化矩是无量纲值,表示独立于任何尺度的线性变化的分布。举个栗子,对于电信号,一阶矩是其DC(直流)电平,二阶矩与平均功率成比例。
- 偏态
随机变量的偏态(衡量分布不对称性)定义为其三阶中心矩:![S(x)=\int _{-\infty }^{\infty }[x-E(x)]^{3}\,f(x)\,dx](http://img.e-com-net.com/image/info8/88f64714e31642e0870adeac90d82923.gif)
需要注意,任何对称分布偏态为0,归一化三阶矩被成为偏斜度,向左偏斜(分布尾部在左侧较长)具有负偏度(失效率数据常向左偏斜,如极少量的灯泡会立即烧坏),向右偏斜分布(分布尾部在右侧较长)具有正偏度(工资数据往往以这种方式偏斜,大多数人所得工资较少)。
- 峰度
一般随机变量的峰度定义为其四阶中心矩与方差平方的比值再减3,减3是为了让正态分布峰度为0,这也被称为超值峰度:![K(x)=\frac{\int _{-\infty }^{\infty }[x-E(x)]^{4}\,f(x)\,dx}{\sigma^2}-3](http://img.e-com-net.com/image/info8/cb4d82d96fc94a5aaed5946563109c28.gif)
峰度表示分布的波峰和尾部与正态分布的区别,峰度有助于初步了解数据分布的一般特征。
完全符合正态分布的数据峰度值为0,且正态分布曲线被称为基线。如果样本峰度显著偏离0,就可判断此数据不是正态分布。
2.协方差矩阵
(1)定义

(2)对协方差矩阵的进一步探讨:
首先我们以二维正态正态随机变量(X1,X2),它的概率密度可以转化为向量形式:


同样,该式子推广到n维正态分布一样适用,如下所示。
令向量x是一个服从均值向量为 ,协方差矩阵为
,协方差矩阵为 的多元正态分布,那么有:
的多元正态分布,那么有:
![]()
假设现在向量x=(x1,x2),x1和x2的方差均为1,那么可以用单位矩阵(identity matrix) I作为协方差矩阵,则生成的若干个随机数如图1所示:
 图1 标准的二元正态分布
图1 标准的二元正态分布
在生成的若干个随机数中,每个点的似然(likelihood, 即可能性大小)为
![]()
对图1中的所有点考虑一个线性变换(linear transformation): ![]() ,我们能够得到图2.
,我们能够得到图2.
 图2. 经过线性变换的二元正态分布,先将图1的纵坐标压缩0.5倍,再将所有点逆时针旋转30度得到
图2. 经过线性变换的二元正态分布,先将图1的纵坐标压缩0.5倍,再将所有点逆时针旋转30度得到
在线性变换中,矩阵A被称为变换矩阵(transformation matrix),为了将图1中的点经过线性变换得到我们想要的图2,其实我们需要构造两个矩阵:
- 尺度矩阵(scaling matrix):
![]()
- 旋转矩阵(rotation matrix):
![]()
其中,  为顺时针旋转的度数。
为顺时针旋转的度数。
变换矩阵、尺度矩阵和旋转矩阵三者的关系式:
![]()
t 是x经过线性变换的结果,可以说t是x的一个映射,那t的分布又是什么样子的呢?
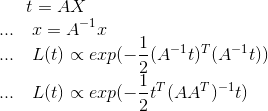
我们看到这时t的协方差矩阵是 , 这里很清楚地显示出t的协方差矩阵跟线性变换A息息相关,假设原始协方差矩阵为I,那么经过线性变换A之后的协方差矩阵变成了。
, 这里很清楚地显示出t的协方差矩阵跟线性变换A息息相关,假设原始协方差矩阵为I,那么经过线性变换A之后的协方差矩阵变成了。
回到我们已经学过的线性代数内容,对于任意对称矩阵  ,存在一个特征值分解(eigenvalue decomposition, EVD):
,存在一个特征值分解(eigenvalue decomposition, EVD):
![]()
其中, 的每一列都是相互正交的特征向量,且是单位向量,满足
的每一列都是相互正交的特征向量,且是单位向量,满足 ![]() ,对角线上的元素是从大到小排列的特征值,非对角线上的元素均为0。
,对角线上的元素是从大到小排列的特征值,非对角线上的元素均为0。
当然,这条公式在这里也可以很容易地写成如下形式:
![]()
其中,![]() , 这跟
, 这跟![]() 是一致的,即经过特征值分解,我们得到:
是一致的,即经过特征值分解,我们得到:
![]()
![]()
进一步,我们发现协方差矩阵的特征向量和线性变换A中的旋转变换相关,协方差矩阵的特征值和线性变换A中的尺度变换相关。换句话说,多元正态分布的概率密度是由协方差矩阵的特征向量控制旋转(rotation),特征值控制尺度(scale),除了协方差矩阵,均值向量会控制概率密度的位置,在图1和图2中,均值向量为 0 ,因此,概率密度的中心位于坐标原点。
五、参考资料
【1】《概率论与数理统计》浙大第四版
【2】https://zhuanlan.zhihu.com/p/37609917