SKlearn - ValueError: Unknown label type: 'continuous'
ValueError: Unknown label type: 'continuous' - sklearn
- 程序代码如下
- 错误信息
- 处理方案:
程序代码如下
// An highlighted block
def modelfit(alg,dtrain,predictors,targets,performCV=True,printFeatureImportance=True,cv_folds=5):
#
alg.fit(dtrain[predictors],dtrain[targets].astype(int))
#
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
#
if performCV:
cv_score = cross_val_score(alg, dtrain[predictors], dtrain[targets].astype(int), cv=cv_folds)
#cv_score = cross_val_score(alg, dtrain[predictors], dtrain[targets].astype(int), cv=cv_folds, scoring='roc_auc')
#Print model report:
print("\nModel Report")
print("Accuracy : %.4g" % metrics.accuracy_score(dtrain[targets].values, dtrain_predictions))
#print("AUC Score (Train): %f" % metrics.roc_auc_score(dtrain[targets], dtrain_predprob))
if performCV:
print("CV Score : Mean - %.7g | Std - %.7g | Min - %.7g | Max - %.7g" % (np.mean(cv_score),np.std(cv_score),np.min(cv_score),np.max(cv_score)))
print(type(alg.feature_importances_))
#Print Feature Importance:
if printFeatureImportance:
feat_imp = pd.Series(alg.feature_importances_[0:30], predictors[0:30]).sort_values(ascending=False)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')
param_test2 = {'max_depth':range(5,16,2), 'min_samples_split':range(200,1001,200)}
gsearch2 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=60, max_features='sqrt', subsample=0.8, random_state=10),
param_grid = param_test2,n_jobs=4,iid=False, cv=5)
gsearch2.fit(train[predictors],train[results])
gsearch2.best_params_, gsearch2.best_score_
错误信息
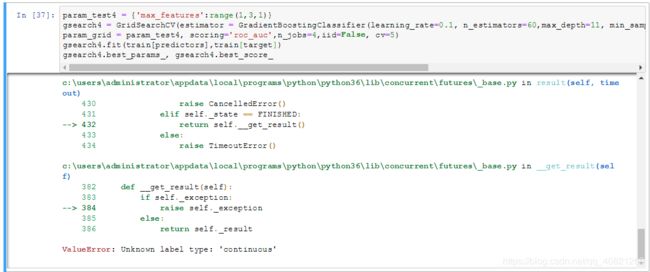
处理方案:
错误原因是由于label的数据类型不是整型导致的数据格式错误,修改程序如下所示;将相应的训练集数据强制转换为整型数据。
param_test2 = {'max_depth':range(5,16,2), 'min_samples_split':range(200,1001,200)}
gsearch2 = GridSearchCV(estimator = GradientBoostingClassifier(learning_rate=0.1, n_estimators=60, max_features='sqrt', subsample=0.8, random_state=10),
param_grid = param_test2,n_jobs=4,iid=False, cv=5)
gsearch2.fit(train[predictors],train[results].astype(int))
gsearch2.best_params_, gsearch2.best_score_
参考资料:
https://blog.csdn.net/weixin_39777626/article/details/79683378