Python机器学习入门1.7《使用决策树模型预测泰坦尼克号乘客的生还情况》
泰坦尼克号乘客数据查验:
#导入panadas用于数据分析
import pandas as pd
#利用pandas的read_csv模块直接从互联网读入数据
titanic=pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
#观察前几条数据,可以发现,数据种类各异,数值型、类别性,甚至还有缺失数据
#print(titanic.head())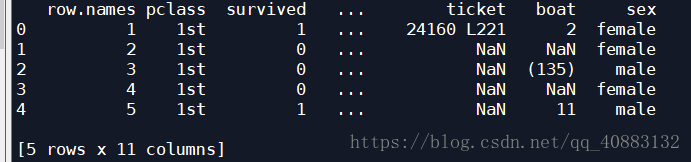
使用pandas,数据都传入独有的dataframe格式(二维数据表格),直接使用info(),查看数据的统计特性 :
titanic.info()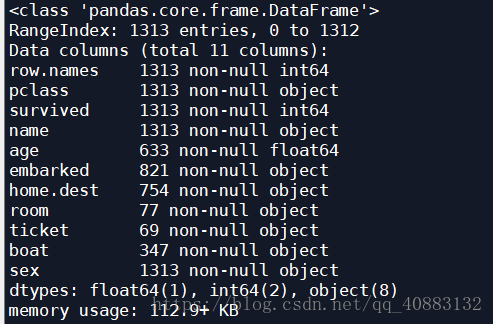
特征选择
X=titanic[['pclass','age','sex']]
y=titanic['survived']
#对当前选择的特征进行探查
#X.info()
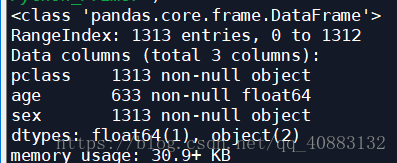
#补全age里面的数据,使用平均数或者中位数都是对模型偏离造成最小影响的策略
#第一个参数是填充的数据的平均数,第二个是替换设置为真
X['age'].fillna(X['age'].mean(),inplace=True)
#重新检查
#X.info()
数据分割:
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33)填特征转换:
#导入特征转化器
from sklearn.feature_extraction import DictVectorizer
vec=DictVectorizer(sparse=False)
X_train=vec.fit_transform(X_train.to_dict(orient='records'))
print (vec.feature_names_)
#print (X_train)
X_test=vec.transform(X_test.to_dict(orient='record'))to_dict:内部转化为字典,外层封装成列表
训练数据学习并预测:
#导入决策树
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier()
#使用分割到的训练数据进行模型学习
dtc.fit(X_train,y_train)
y_predict=dtc.predict(X_test)性能评估:
#决策树模型对泰坦尼克号乘客是否生还的预测性能
from sklearn.metrics import classification_report
#输出预测的准确性
print(dtc.score(X_test,y_test))
#输出更加详细的分类性能
print(classification_report(y_test,y_predict,target_names=['died','survived']))

相对于其他学习模型 ,决策树在模型描述上有着巨大的优势,决策树逻辑推理非常直观,可解释性,方便模型的可视化,所以无需进行量化甚至标准化的,决策树与K近邻模型不一样,任然需要参数,需要花费更多的时间训练数据。\
完整代码参考:
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 18 15:16:39 2018
Robert_Wang
@author: asus
"""
#导入panadas用于数据分析
import pandas as pd
#利用pandas的read_csv模块直接从互联网读入数据
titanic=pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
#观察前几条数据,可以发现,数据种类各异,数值型、类别性,甚至还有缺失数据
print(titanic.head())
#使用pandas,数据都传入独有的dataframe格式(二维数据表格),直接使用info(),查看数据的统计特性
#titanic.info()
#使用决策树模型预测泰坦尼克号乘客的生还情况
X=titanic[['pclass','age','sex']]
y=titanic['survived']
#对当前选择的特征进行探查
#X.info()
#补全age里面的数据,使用平均数或者中位数都是对模型偏离造成最小影响的策略
#第一个参数是填充的数据的平均数,第二个是替换设置为真
X['age'].fillna(X['age'].mean(),inplace=True)
#重新检查
#X.info()
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33)
#导入特征转化器
from sklearn.feature_extraction import DictVectorizer
vec=DictVectorizer(sparse=False)
X_train=vec.fit_transform(X_train.to_dict(orient='records'))
print (vec.feature_names_)
#print (X_train)
X_test=vec.transform(X_test.to_dict(orient='record'))
#导入决策树
from sklearn.tree import DecisionTreeClassifier
dtc=DecisionTreeClassifier()
#使用分割到的训练数据进行模型学习
dtc.fit(X_train,y_train)
y_predict=dtc.predict(X_test)
#决策树模型对泰坦尼克号乘客是否生还的预测性能
from sklearn.metrics import classification_report
#输出预测的准确性
print(dtc.score(X_test,y_test))
#输出更加详细的分类性能
print(classification_report(y_test,y_predict,target_names=['died','survived']))