http基本请求头详解
自己总结的太短少,直接放上大佬总结的
Accept:
例:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8
表示客户端支持的数据格式,或者说客户端“希望”接受到的内容类型。
这里只是希望,但是服务器具体返回什么样的内容类型,还是由服务器自己决定,但是无论服务器返回什么样的内容类型,客户端都会接收响应报文,不可能说因为内容类型不同,接收不到服务器响应报文,这不符合http协议规范。
我们通过浏览器发起get或post请求,该字段都是浏览器自动添加的,同样在服务器端也不会解析该字段的值;
通过ajax请求或其他手段,我们可以设置该字段的值,但是通常也不进行设置。
该字段的应用场景可以是这样的,有两个终端,比如一个是纯文本阅读器,如Kinder(不能显示图片),另一个是移动终端(可以播放图片和视频),均向服务器请求有关“斑马”的信息,那么这时候服务器端就需要判断什么样的终端应该返回什么样的信息,那么它就可以根据Accept的信息来进行判断,如果解析到的Accept的值为“text/plain”,那么就表示客户端只支持文本类型;如果向上面例子中的那样,则表示客户端文本图片视频都可以。如果我们不加判断,当返回给文本阅读器一张图片时,可能它显示的就是乱码。
Accept-Encoding:
例:
Accept-Encoding:gzip, deflate, br
表示客户端所支持的解码(解压缩)格式。
网路数据的传输都是占据带宽的,而将文件数据压缩能够降低数据量,减少传输时间。所以服务器在返回数据给客户端时,常常对数据进行压缩(对用户透明,通常由服务器或代理来做),而压缩的方式有多种,到底采用哪一种则需要看客户端支持哪种解码方式,这时候就可以根据header中Accept-Encoding的值。
文件或数据的压缩,由服务器或代理来做,一般不需要程序员干预;客户端接收到数据时解压缩,通常由浏览器自动完成,对用户透明。
对于我们主动发起的ajax请求,一般数据量较少,不需要设置该字段。
Accept-Language:
例
Accept-Language:zh-CN,zh;q=0.9
表示客户端支持的语言格式(不是编码格式),如中文/英文,通常浏览器直接发起请求时,浏览器会根据被设置的语言环境(默认语言),来附加上该字段。
一般我们服务器解析报文时,是不理会该字段的。
他的使用场景可以是这样的,假如有个文件,有各种语言的版本,这样当不同请求发来时,我们可以根据Accept-Language的值来判断到底返回哪种语言版本给客户端。
(其实这种应用场景也一般不采用判断Accept-Language字段的方法,不靠谱,还不如直接在url中体现语言版本呢)
Accept-Charset:
例:
Accept-Charset:gbk,utf-8;q=0.8
表示客户端支持编码格式。服务器在返回报文时,需要将字符按照一定的编码格式转换为字节序列发送给客户端,那么该采用哪种编码格式呢?
当然作为服务器端,他可以采用任何一种编码方式,客户端都得完完整整的接收响应报文。因为目前客户端几乎都支持常见编码类型,所以服务器在返回数据时,只需要按照既定的编码方式编码,然后在响应报文中告知客户端所使用的编码方式。这样客户端在接收到报文后按照该方式进行解码,就就不会出现乱码问题。
但是,如果客户端已经定了就使用某种解码方式,那么这时候服务器端就不能那么任性了,他就需要解析Accept-Charset字段,根据这个值,来设定采用的编码方式。
如上例中,以逗号分隔,客户端支持两种编码方式,gbk和utf-8(gbk优先级高于utf8),其中utf-8后的q值,表示utf-8占的“权重”。
题外话:
服务器端怎么通知浏览器所采用的编码格式呢?
如果不通知浏览器,那么浏览器会采用什么样的格式解码呢?
服务器端以原生的Servlet & JSP为例:
1)当返回的是HTML页面,那么页面meta charset就指定了编码格式
2)当返回的是JSP页面,那么页面pageEncoding就指定了编码格式
3)当通过resp的Outputstream返回原生内容时,我们可以通过设置响应头content-type/content-charset字段来指定编码格式
那么如果服务器不指定编码格式呢?
我的测试环境为win10中文操作系统,浏览器:Chrome 64.0.3282.186(正式版本)
1)返回的html页面不设置meta标签,但是文件本身是utf-8或gbk编码,中文不乱码,
服务器会将html页面转换为字节流写给浏览器,浏览器读取字节流,由于找不到meta标签设置的文件格式,就会按照默认的格式解码。
这时出现的情况是,当原页面是gbk编码时,浏览器能正常显示页面;当原页面是utf-8编码时,浏览器显示中文乱码。
这说明当前Chrome浏览器的默认编码格式为gbk。使用微软自带的Microsoft Edge测试结果一样 。
2)返回JSP页面时,必须指定pageEncoding。
3)通过response的输入流,直接返回生成的字节流(GBK格式的),此时,不设置响应头的编码格式。
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//resp.setContentType("text/html;charset=gbk");
resp.setContentType("text/html;");
ServletOutputStream out = resp.getOutputStream();
out.write("好好学习
".getBytes("gbk"));
out.close();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1、直接在浏览器地址栏输入访问地址,不乱码

2、通过ajax发送get请求,乱码
var xhr = new XMLHttpRequest();
xhr.onload = function (argument) {
if(xhr.readyState==4){
alert(xhr.responseText);//打印接收的字符串
}
}
xhr.open('get','http://localhost:8080/mvctest/http',true);
xhr.send(null);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

当服务器使用gbk编码返回字节流时,地址栏的http请求不乱码,但是ajax请求响应乱码;
如果我们的服务器使用utf-8返回字节流时,地址栏的http请求乱码,但是ajax不乱码。
(第二种测试结果贴图省略)
这说明同一个浏览器,在不同的地方采用的编码格式不同,当浏览器解析页面时,它默认使用的是gbk编码(可能因为我们的中文操作系统,同时是中文版的软件,所以浏览器默认使用gbk格式来解析页面);当浏览器使用内核XMLHttpRequest对象来解析响应时,默认采用的是utf-8(这个应该跟操作系统语言没关系,内核层面的应该在哪个国家都一样)
所以,如果为了确保在各种情况下都不乱码,服务器一定要通知客户端所采用的编码格式
我们继续来说头字段的含义:
Referer:
例:
Referer:http://localhost:8080/test/11.html
表示当前请求是从哪个资源发起的;或者是请求的上一步的地址。
我在11.html页面发起一个请求,这时候浏览器封装的请求头就有上例中的referer字段,表示当前请求是这个资源链接中发起的。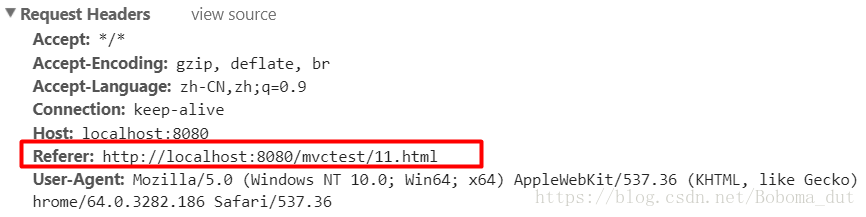
Referer是常用于网站的访问统计,比如我在很多地方都做了广告链接到我网站的主页,这时候我就可以通过Referer来查看哪些地方跳转过来的人多,就说广告的效果好。
另外,Referer还经常用于防盗链,具体可以参见这位兄台博客“http防盗链”
If-Modified-Since:
例:
If-Modified-Since:Thu, 29 Mar 2018 08:37:45 GMT
表示客户端缓存文件的时间。字面翻译的意思是,“如果从…时间改变了”(就请再发送给我一遍新的文件)。
当客户端访问服务器的静态文件时,通常会将资源结果缓存下来,并标记一下文件的缓存时间(根据响应头中的Last-Modified字段);当接下来再发送同样的请求时,会在请求头中添加上这个字段If-Modified-Since;
服务器端读取字段值,判断服务器端文件的最后修改时间,如果如果不晚于该值,说明浏览器缓存的文件是最新的,然后就不会重新发送文件内容,而是将相应报文的状态设置为304,表示你读取缓存的文件就可以了,这就很大程度上节省了带宽。
第一次请求头:
GET /mvctest/11.html HTTP/1.1
Host: localhost:8080
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
第一次响应头: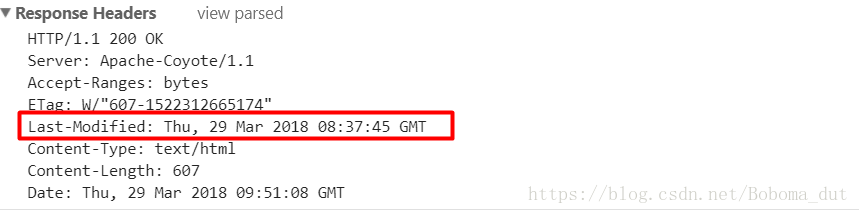
第二次请求头: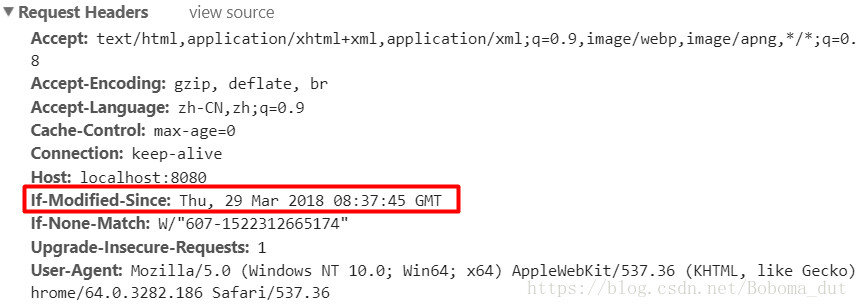
第二次响应头: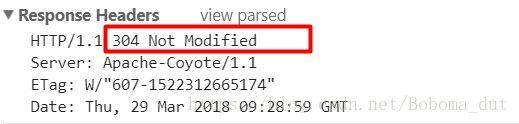
需要说明的是,If-Modified-Since字段的值,为服务器端文件最后修改的时间,不是请求的访问时间,时间值为GMT格林尼治时间,不是本地时间。
浏览器一般只对.html,.jpg,.css,.js等这些静态资源进行缓存,对于jsp页面以及ajax请求的动态结果,不缓存。服务器如Tomcat会自动给静态文件的响应报文添加“Last-Modified”字段,同时解析请求报文中的If-Modified-Since字段,这些都是对我们透明的。
例如,我们将11.html改为11.jsp,那么浏览器将不会缓存页面内容,服务器每次都响应一个完整的页面内容给客户端,也不会在响应报文中添加“Last-Modified”字段。
每次对于JSP请求的响应结果: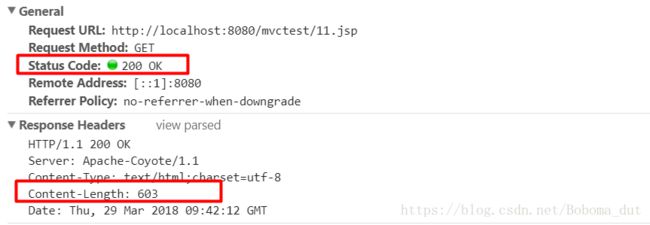
If-None-Match:
例:
If-None-Match:W/”607-1522312665174”
该字段同If-Modified-Since字段一样,都是用来表示资源文件是否是最新的。只不过If-Modified-Since的值为文件的最后修改时间,而该值为资源实体的哈希值,同样是由服务器生成的。
从上面的截图中我们可以看到:
第一次请求时,服务器的响应报文中有字段Etag,这就是实体的哈希值,浏览器会缓存文件并记录该值。
第二次请求时,请求头字段中就有If-None-Match,值为Etag的值,而服务器会判断该值与服务器中文件的哈希值是否相同,如果相同,就返回304,让浏览器读取缓存;否则会返回新的资源文件,并在响应头中设置新的Etag值。
Last-Modified/If-Modified-Since 和 Etag/If-None-Match这两对头字段都是来标记缓存资源的,但是后者的优先级要高于前者。
Cache-Control:
例:
Cache-Control:no-cache
字段的字面意思为“缓存-控制”,前面我们将了几个字段表面客户端/服务器如何使用缓存机制,而这个字段就是用来控制缓存的。
Cache-Control在请求/响应报文头中均可设置,分别表明不同的意思,下面我们以响应报文为例:cache-control在响应报文的的取值可以为:public、private、no-cache、no- store、no-transform、must-revalidate、proxy-revalidate、max-age。
所代表的意思为:
其中,no-cache、no-store、max-age为常用的取值。
比如,服务器在响应报文中添加Cache-Control:no-store,表示浏览器或各级代理,不要缓存本次的相应内容(即使响应报文中有Etag和Last-Modified);
比如,响应报文中有Cache-Control:no-cache,表示浏览器可以缓存响应文件,但是在使用缓存之前,必须通过令牌(Etag)来与服务器进行沟通确认缓存有效。
比如,响应报文中有Cache-Control:max-age=500,表示在接下来的500秒内,浏览器可以自主使用缓存内容,不需要向服务器发送同样的请求。
在请求报文中,也可以添加cache-control字段,其取值可以为no-cache、no-store、max-age、 max-stale、min-fresh、only-if-cached。
客户端在发送请求到服务器时,可能会经过很多层代理,而这些代理可能就缓存了本次请求想要的文件,而请求中的cache-control就可以控制,是否使用代理中的缓存文件。
比如,请求报文头中有cache-control:no-cache,那就表示,代理如果返回给我缓存文件时,需要到服务器端进行确认,缓存是不是最新的。
比如,请求报文头中有cache-control:no-store,那就表示,我不需要代理中的缓存文件,我需要直接请求服务器。
所以我们可以看到,cache-control就是用来控制缓存使用的,如是否缓存,是否使用缓存,缓存到期时间等,而Last-Modified/If-Modified-Since 和 Etag/If-None-Match是标识C/S之间怎么使用缓存。
缓存的使用都是服务器和客户端的默认行为,对用户和程序员的透明的,当然我们可以通过配置文件或程序修改他们的行为规则。
附:http协议中对缓存的说明
User-Agent:
例:
User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36
表示客户端的软件环境。如上可以看出使用的是Window10 64位操作系统,Chrome浏览器等信息。服务器可以根据该字段评估客户端的环境从而给出不同的响应。(比如根据请求是从手机端或是电脑端发起的,返回不同版本的页面)
Host:
例:
Host:localhost:8080
表示请求者的主机地址(IP地址)和端口号。
服务器端可以根据该字段进行ip过滤等操作。
响应头
Etag、Last-Modified、cache-control在前文中已经说明。
Content-Length:
例:
Content-Length:607
表示接收到的响应报文的总长度为607。
根据这个长度,客户端可以更准确的接收和解析报文内容。或者可以根据当前接收/解析的长度占总长度的百分比,做出进度条的效果。
Accept-Ranges:
例:
Accept-Ranges:bytes
表示服务器支持http中的Range功能,能够分段请求客户端能够分段请求服务器。
我们上网时常用的“断点续传”,或者服务器所谓的“多线程下载”就是靠的服务器端的Range技术。
Range功能的请求-响应流程如此:
客户端发起带range的请求:
GET /test.rar HTTP/1.1
Connection: close
Host: 116.1.219.219
Range: bytes=0-100- 1
- 2
- 3
- 4
在头中添加Range字段,表示我要请求[0-100]这101个字节的数据。
此处Range的值,可以添加多个片段,如 Range:bytes=0-100,200-300等。
服务器响应报文:
HTTP/1.1 206 OK
Content-Length: 801
Content-Type: application/octet-stream
Content-Location: http://www.onlinedown.net/hj_index.htm
Content-Range: bytes 0-100/2350 //2350:文件总大小
Last-Modified: Mon, 16 Feb 2009 16:10:12 GMT
Accept-Ranges: bytes
ETag: "d67a4bc5190c91:512"
Date: Wed, 18 Feb 2009 07:55:26 GMT- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
响应报文中有Content-Range字段,表示响应的报文片段内容范围,已经总的数据大小。
同时Range请求的正常的返回码是206,不是200。
而即使我们请求的不是Range功能请求,那么服务器的返回字段中会有Accept-Range,表示服务器支持Range功能。
Server:
例:
Server: Apache/2.4.1 (Unix)
表示服务器的名称,是Unix下的Apache服务器
--------------------- 本文来自 Boboma_dut 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/Boboma_dut/article/details/79741162?utm_source=copy