Software Construction学习——抽象数据类型(ADT)
抽象数据类型(Abstract Data Type)和表示独立性(Representative independence):使我们能够区分如何在程序中使用数据结构和数据结构本身的形式
· 抽象数据类型会避免客户对数据内部的表示进行猜测(即“表示泄漏”)。从而导致潜在的bug——即在用户和实现者之间建立起了一个防火墙。
一. 抽象(Abstraction)和用户(User-Defined)的类型
ADT的定义:是软件工程之中一个通用原则的实例,有许多部分:
· 抽象(Abstraction):用一个更加简单、高级的思想去隐藏或者忽略那些低层次的实现。
· 模块化(Modularity):将一个系统划分成多个元素或者模块,每一个模块都能进行独立的设计、实现、测试、复用,而不影响整个系统。
· 封装(Encapsulation):在模块之外“包上一堵墙”,因此模块就能只对自己内部的行为、bug负责,而且系统的其它部分并不能破坏该模块的完整性。
· 信息隐藏(Information hiding):在系统的其它部分隐藏模块的具体细节,因此这些细节可以被独立更改而不需要改变整个系统。
· 不同的“特征”(Concern/feature):对于每一个模块都有一个确定的责任,而不是让一个责任跨越多个模块。
用户定义的类型:除了编程语言所提供的基本数据类型和对象数据类型,程序员可定义自己的数据类型
数据抽象(Data abstraction):一个由一系列可以操作的操作所定义的类型,而不是由数据自身所定义的。
e.g. 数字可以加和乘 String可以相连接,也能获得子字符串
传统的类型定义是关注与数据的具体表示,例如Date就是用Integer属性来定义年、月、日
抽象类型则强调操作(operation):类型的使用者并不需要关心特定的值(value)是如何存储的,而只需要去设计/使用操作,关注与“作用于数据上的操作”即可
e.g. 一个Bool有如下的操作
- true: Bool
- false: Bool
- and: Bool * Bool -> Bool
- or: Bool * Bool -> Bool
- not: Bool -> Bool
这些操作本身以及他们的规约完全定义了这个类型,将其从数据结构、存储结构、和实现方法中抽象了出来。
因此这个Bool有各式各样的满足规约的实现方式:
- 字节1是true,字节0是false
- 整数5是true,整数8是false
- "true"是false,"false"是true
ADT的具体的值(value)是不透明的,这意味着用户并不能获得存储在数据类型内部的值,除非有相应的操作。ADT不仅仅隐藏了一个独立的函数,而是隐藏了一系列操作还有他所提供的数据(private fields)。
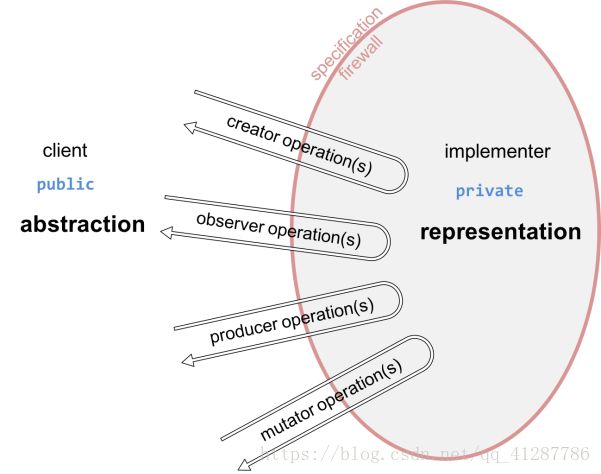
二. 操作和类型的分类
所有类型,不论是用户定义的还是内嵌的,都能被分为可变的(mutable)和不可变的(immutable)。
· 可变类型:提供了改变类型内部数据的值的操作。
e.g. Date就是可变数据类型,因为存在setMonth()来改变内部的值
· 不可变类型:其内部的操作不是改变值,而是创造了一个新的对象
e.g. String就是不可变数据类型,因为它相应的操作都是创造了一个新的String
· 有时候同一个类型既会有可变类型,也会有不可变类型。
e.g. StringBuilder就是String的一种可变类型(但是在java之中,两者并不相同)
ADT内部的方法分类:(T代表ADT,t代表其它类型,*表示可能出现,+表示至少出现一次)
构造器(Creator):创建一个新的对应的类型的对象。
- 构造器会将一些对象作为参数,但不是将要构造类型的对象。
t* -> T
生产器(Producer):由一个对应类型的旧的对象生成出一个新的该类型的对象。
- e.g. String的concat()就是一个Producer,它利用两个String类型生成出一个新的String
T+, t* -> T
观察器(Observer):以ADT的对象为基础,返回一个其它类型的对象来反应ADT对象。
- List的size()就是一个观察器,它的返回值就是一个int
T+, t* -> t
变值器(Mutators):改变对象本身,即改变对象的内部属性
- List的add()就是一个变值器。
T+, t* -> void |t| T
Creator:一个构造器可能实现为构造函数(像是 new ArrayList<>())或静态函数(像是Arrays.asList())
构造器的静态函数实现也通常被称为工厂方法。
e.g. String.valueOf(Object obj)就是java的一种以工厂方法实现的构造器。与Object.toString()正好是相对的。
Mutator:变值器通常返回void,而如果返回值是void则意味着它改变了某些对象的内部状态。但是变值器也可能返回非空类型,像是Set.add()会返回一个boolean来判断加入是否成功。
三. ADT实例
int是一个不可变类型,因此它没有变值器
- 构造器:数值(0,1,2 ....)
- 生产器:代数操作(+,-,/,*)
- 观察器:比较操作(==, !=, <, >)
String是一个不可变类型,因此也没有变值器
- 构造器:String构造器
- 生产器:concat, substring, toUpperCase
- 观察器:length, charAt
List是一个可变类型,List也还是一个接口,这意味着有其它的具体的类来实现了这个接口,像是ArrayList和LinkedList
- 构造器:ArrayList和LinkedList构造器,Collections.singleonList
- 生产器:Collections.unmodifiableList
- 观察器:size,get
- 变值器:add, remove, addAll, Collections.sort
java官方List说明

更多的例子:

四. 抽象类型的设计
设计一个抽象类型需要选择好的操作以及它们的具体表现。即要设计其操作和其行为规约。
法则1:设计简洁、有效的操作,而不是很多复杂的操作;每一个操作都都应当定义好的规约,并且有着行为的连贯性,而不是针对某一种特殊情况。
e.g. 我们不会给List之中增加一个sum的操作,尽管这可能对于储存int类型的list有所帮助,但是对于String类型的list就可能会产生一些让人难以理解的东西。
法则2:操作要足以支持用户对数据所做的所有操作的需要,且用操作满足用户需要的难度要低。
- 一个好的测试是检查类型对象的每个属性值都可以被提取。
e.g. 如果没有get()操作,那么我们就无法得知list内部到底储存了什么。
- 基本的信息的获取应当是比较容易的。
e.g. size()操作对于list来说并不是必须的,因为我们可以遍历list来获取大小,但是这样就显得比较麻烦。
法则3:要么抽象,要么具体,不要混合——即要么针对抽象设计,要么针对具体应用设计。
五. 表示独立性(Representative Independence)
关键的是,一个好的ADT应当具有表示独立性:
· ADT的使用者应当与其内部表示(内部实现真正的数据结构和属性)独立开来,因此这些表示相应的改变并不会对代码的外在表现有所影响。
e.g. List的操作是独立的,无关它是以LinkedList还是ArrayList表示的
· 除非ADT的操作指明了具体的pre-condition和post-condition,否则不能改变ADT的内部表示。
String的不同表示:

测试用例:

一个最简单的表示方法: private char[] a;
因此,对应的MyString可以有如下实现
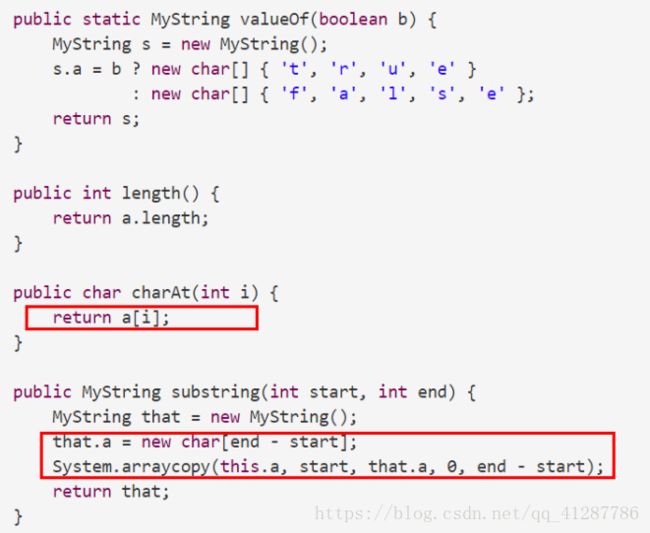
因为这是一个不可变数据类型,因此substring并不用拷贝一系列字符到新的char数组之中。故只需要指定char数组的开始和结尾即可。这种实现的表示为:

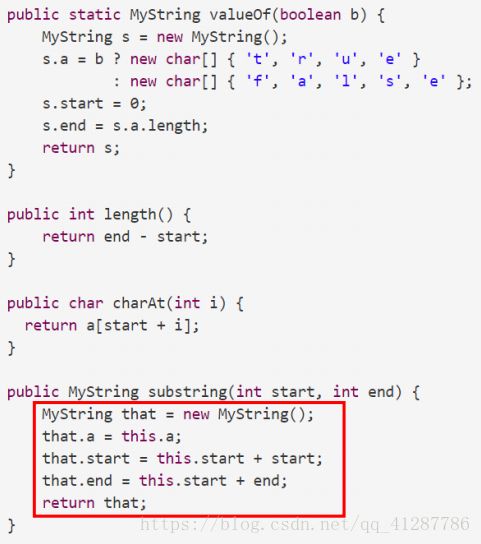
因为用户只关心其对于公共方法的规约,而不是其私有的属性,因此我们可以做出这样的更改,而不去改变客户端上的代码。
六. ADT的测试
测试构造器,生产器,变值器:调用观察器来观察这些操作是否满足规约。
测试观察器:调用构造器,生产器,变值器等方法产生或者改变对象,来看结果是否正确。

七. 不变量(Invariants)
一个好的ADT所有的最重要的性质是保持不变量。
不变量是指程序的一个恒为真的属性。
- 不变性(Immutability)是其中一个最为重要的不变量:一旦被创造,一个不可变对象的一生都应当表示一个相同的值。
ADT保持不变量是指ADT有责任保持这个不变量恒为真,而与客户端无关。
而保持不变量就是保持程序的正确性,而且也更容易发现错误。
如何保持不变量:
1.第一个危险是表示泄漏(representation exposure):对应类之外的代码也能直接修改类内部的表示
e.g.

- 表示泄漏不仅仅威胁了不变量,也威胁到了表示的独立性
- 如果发生表示泄漏,那么就不能轻易改变该类的实现,因为会影响到所有直接使用该类内部表示的客户端。
因此,要防止表示泄漏
private / final
e.g.
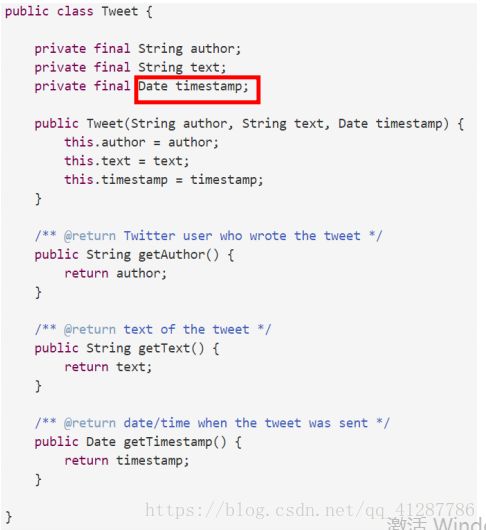
但是仍然存在表示泄漏
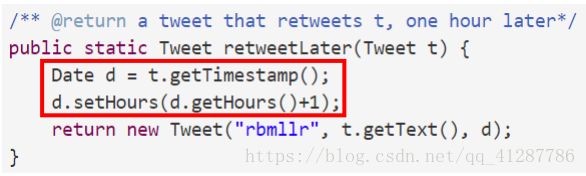
这个会导致同样的一个Tweet,在调用了setHours前后,其内部的表示发生了变化(发送时间推迟了一个小时)。
原因是Date类型是一个可变数据类型,因此在返回时间后,可以通过不同的引用对其进行修改,而不创建新的对象,从而导致了Tweet的不变量被破坏
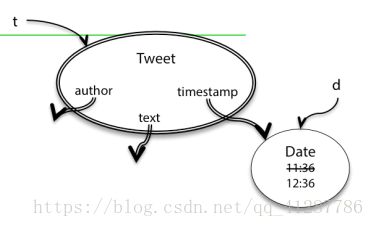
因此我们可以使用一种防御性复制(defensive copy)的策略来防止这种事情的发生。
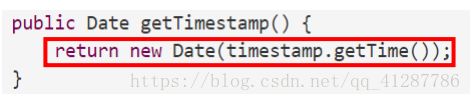
然而在确保了观察器不会导致内部泄漏后,还是不能确保Tweet类的不变性
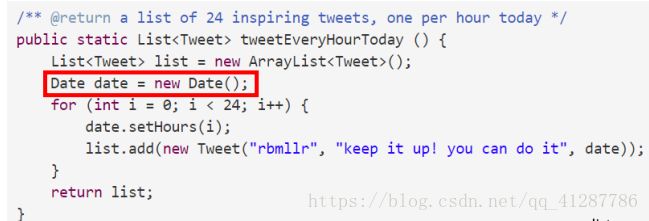
显然,这种会导致list之中的所有Tweet的发送时间都是一样的。
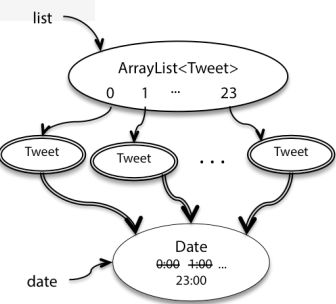
因此,对于构造器,也要采取防御性复制的策略。
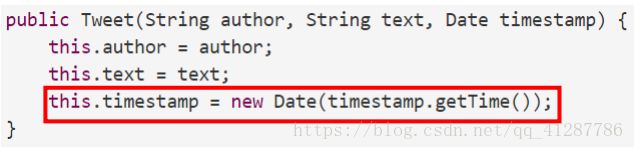
因此,对于ADT之中的表示,如果其中任何类型时可变的,那么就要保证对其的任何实现方式都不能返回一个对于可变数据的直接的引用。
但是有时候,这样的复制的代价是很高的,就需要在spec之中写明,靠客户端来保证不去更改内部表示。但是这样会导致很多的潜在bug,因此除非迫不得已,否则不要把希望寄托于客户端之上,ADT有责任保证自己的不变量,并避免表示泄漏,最好的办法就是使用不可变类型。
八. 表示不变量(Rep Invariant)和抽象函数(Abstraction Function)
ADT之中的值可以表示为两个空间之中的元素
R:表示空间,值通过表示所实现的具体实例。
-一般情况下ADT的表示都比较简单,有时候需要复杂表示
A:抽象值构成的空间,客户端看到和使用的值
-只是理想下的存在,实际上并不以所看到的形式存在,而是以该种形式将其存在表示出来。
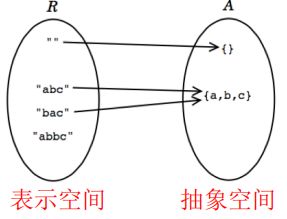
ADT实现者关注表示空间R,而用户更关注抽象空间A
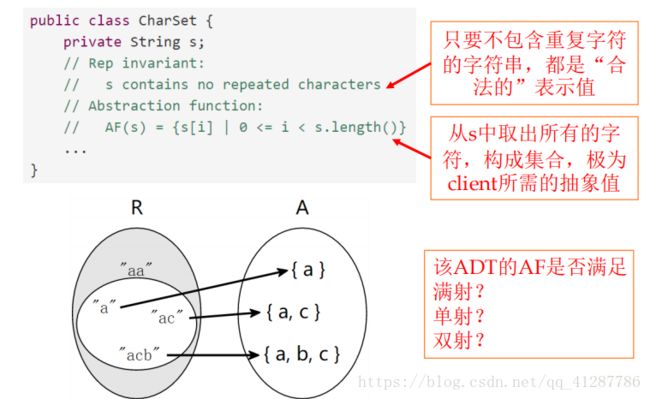
e.g.假设我们用一个字符串来表示一串字符

那么R空间内是一个字符串“abc”,而A之中所含的则是'a', 'b', 'c'。
R与A之间的函数关系:
因此我们可以看到,ADT实现者对于客户的每一种输入在R空间内都有相应的值,故R与A之间是满射。
但是显然,对于R空间内的多个值,他们在A空间之中的所体现的东西可能是相同的,因此R与A之间未必是单射
因此,R与A之间也未必是双射
抽象函数:R与A之间映射关系的函数
AF : R -> A
表示不变性(RI):即判断一个表示是否为恒为真
RI:R -> boolean
对于任何一个表示值r,如果RI(r)为真,只有当r满足AF,即r是合法的
也可以说,RI描述了什么样的表示值是合法的
或者说,RI是一个集合,是所有表示值的一个子集,包含了所有合法的表示值
e.g.
什么决定了AF和RI?
不同的内部表示,需要设计不同AF和RI。比如一系列字符,我们可以用一个字符串来表示,也可以用一个字节向量来表示,显然我们需要对这两种不同抽象表示方法定义不同的AF和RI
选择某种特定的表示方式R,进而指定某个子集是“合法”的(RI),并为该子集中的每一个元素做出“解释”(AF)——即如何将表示空间中的值映射到抽象空间之中。
e.g. 显然,对于不同的RI,所确定的合法的子集是不同的

一个最基本的点是在设计ADT时,我们不仅仅要确定两个空间,还要确定我们要使用何种表示方法,并且如何解释它。即
1.选择R和A 2.确定RI——合法的表示值 3.如何解释合法的表示值——AF
做出合理而具体的解释:每个rep value是如何映射到abstract value,并且要将这种选择和解释写入注释
由于RI是一个恒为真的表示,因此我们需要在ADT之中随时检查RI是否被满足
- 在对象的初始状态时,不变量为true;在对象发生变化时,不变量也要为true
- 构造器和生产器在创建对象时要保证不变量为true
- 变值器和观察器在执行时要保持不变性
- 表示泄漏也可能会导致ADT内部表示在程序的任何位置发生改变,从而导致不变量不为true
通常是调用checkRep()在类之中的构造器和变值器之中来进行检查
九. 有益的可变性
虽然我们之前提及了ADT最好使用不可变的数据类型来防止潜在的bug和表示泄漏。但是有些时候,表示值的改变是可以接受,只要这个表示值仍然对应于抽象空间之中一个相同的值。那么这种变化就被称为是有益的可变性(beneficent mutation)。
十. RI,AF和Safety from Rep Exposure
在代码之中用注释的形式来记录RI和AF,也要记录表示泄漏的安全声明——给出自己所写的代码为什么不会发生表示泄漏的理由。
e.g.

ADT的规约里只能使用客户端可见的内容来撰写,包括参数、返回值、异常等。即规约内部不能出现表示空间R之中的值,但是可以用抽象空间A之中值来声明。ADT的内部表示(私有属性)对外部都应该严格不可见。故在代码中以注释形式写出的AF和RI而不能再javadoc文档之中,防止被外部看到而破坏独立性。
资料来源 MIT 6.031 哈工大软件构造课程