Python「Word2vec」:训练词向量时,准确度太低的问题反思
最近在做毕设的原因,使用到了 python 的 word2vec 模块,将较大批量文本进行训练生成的词向量存在明显的准确度太低的情况(例如查找与某个词相似的 top10,给出的结果总是乱七八糟),这里找到了原因,做一下简单记录。
目录
一、原因
(一)错误的思路
(二)问题所在
二、解决方法
一、原因
(一)错误的思路
首先简单介绍一下我原本是怎么做的吧!
1. 获取停用词(停用词库下载)
# 获取停用词
def get_stopwords(stopwords_path):
# 停用词列表
stopwords = []
with open(stopwords_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
for j in lines:
line = j.replace('\n', '')
stopwords.append(line)
return stopwords2. 选择需要的词性
这里我只选择了在词向量训练过程中具有明显意义的词性:名词、地名、机构团体、英文、动词、形容词
# 词性
# 名词、地名、机构团体、英文、动词、形容词
my_flags = ('n', 'ns', 'nt', 'eng', 'v', 'a')3. jieba 分词
# 获取结巴分词
# file_path:文本路径,stopwords:停用词列表,car_path:自定义语料库路径,flags:词性,corpus_path:保存路径
def get_split(filenames, stopwords, car_path, flags, corpus_path):
split = ''
with open(filenames, 'r', encoding='utf-8') as f:
txt = f.read()
# 增加专业名词
jieba.load_userdict(car_path)
words = [w.word for w in jp.cut(txt) if w.flag in flags and w.word not in stopwords]
text = ' '.join(words)
split += text
with open(corpus_path, 'w', encoding='utf-8') as f:
f.write(split)这段代码中最重要的部分其实就是下面这一行:
words = [w.word for w in jp.cut(txt) if w.flag in flags and w.word not in stopwords]jp 来自于 import jieba.posseg as jp ,jp.cut() 的结果 w 具有两个属性:词(w.word)和词性(w.flag),这句话的含义就是:通过 jp.cut() 操作的 w ,如果其词 w.word 不在停用词 stopwords 中且词性 w.flag 在 flags 中,则将该词 w.word 保存在列表 words 中。
- 整体代码:split.py
import jieba
import jieba.posseg as jp
# 获取停用词
def get_stopwords(stopwords_path):
# 停用词列表
stopwords = []
with open(stopwords_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
for j in lines:
line = j.replace('\n', '')
stopwords.append(line)
return stopwords
# 获取结巴分词
# file_path:文本路径,stopwords:停用词列表,car_path:自定义语料库路径,flags:词性,corpus_path:保存路径
def get_split(file_path, stopwords, car_path, flags, corpus_path):
split = ''
with open(file_path, 'r', encoding='utf-8') as f:
txt = f.read()
# 增加专业名词
jieba.load_userdict(car_path)
words = [w.word for w in jp.cut(txt) if w.flag in flags and w.word not in stopwords]
text = ' '.join(words)
split += text
with open(corpus_path, 'w', encoding='utf-8') as f:
f.write(split)
if __name__ == '__main__':
# 停用词路径
my_stopwords_path = r'../../data/jieba_data/stopwords.txt'
# 文本路径
my_file_path = r'../../data/result_data/mouth.txt'
# 专业名词路径
my_car_path = r'../../data/jieba_data/car_name.txt'
# 语料库路径
my_corpus_path = r'../../data/result_data/corpus.txt'
# 词性
# 名词、地名、机构团体、英文、动词、形容词
my_flags = ('n', 'ns', 'nt', 'eng', 'v', 'a')
# 获取停用词
my_stopwords = get_stopwords(my_stopwords_path)
# 分词
get_split(my_file_path, my_stopwords, my_car_path, my_flags, my_corpus_path)4. 训练 word2vec
# 训练词向量
# corpus_path:语料库路径,vector_path:词向量保存路径,model_path:模型保存路径
def train_word2vec(corpus_path, vector_path, model_path):
# 把语料变成句子集合
sentences = LineSentence(corpus_path)
# 训练word2vec模型(size为向量维度,window为词向量上下文最大距离,min_count需要计算词向量的最小词频)
# (iter随机梯度下降法中迭代的最大次数,sg为3是Skip-Gram模型)
model = word2vec.Word2Vec(sentences, size=20, sg=3, window=5, min_count=1, workers=4, iter=5)
# 保存word2vec模型
model.save(model_path)
model.wv.save_word2vec_format(vector_path, binary=False)读者读到这里时,建议留意上述代码中的一句“sg为3是Skip-Gram模型”。
- 整体代码:word2vec.py
word2vec 编码参考了另一篇博客:《『词向量』用Word2Vec训练中文词向量(一)—— 采用搜狗新闻数据集》,作者:来日凭君发遣。
import gensim.models as word2vec
from gensim.models.word2vec import LineSentence
# 训练词向量
# corpus_path:语料库路径,vector_path:词向量保存路径,model_path:模型保存路径
def train_word2vec(corpus_path, vector_path, model_path):
# 把语料变成句子集合
sentences = LineSentence(corpus_path)
# 训练word2vec模型(size为向量维度,window为词向量上下文最大距离,min_count需要计算词向量的最小词频)
# (iter随机梯度下降法中迭代的最大次数,sg为3是Skip-Gram模型)
model = word2vec.Word2Vec(sentences, size=20, sg=3, window=5, min_count=1, workers=4, iter=5)
# 保存word2vec模型
model.save(model_path)
model.wv.save_word2vec_format(vector_path, binary=False)
# 加载模型
def load_word2vec_model(model_path):
model = word2vec.Word2Vec.load(model_path)
return model
# 计算词语最相似的词
def calculate_most_similar(model, word):
similar_words = model.wv.most_similar(word)
print(word)
for j in similar_words:
print(j[0], j[1])
# 计算两个词相似度
def calculate_words_similar(model, word1, word2):
print(model.similarity(word1, word2))
# 找出不合群的词
def find_word_dis_match(model, lists):
print(model.wv.doesnt_match(lists))
if __name__ == '__main__':
# 语料库路径
my_corpus_path = r'../../data/result_data/corpus.txt'
# 语料向量路径
my_vector_path = r'../../data/result_data/corpus.vector'
# 模型路径
my_model_path = r'../../data/result_data/word2vec.model'
# 训练模型
train_word2vec(my_corpus_path, my_vector_path, my_model_path)
# # 加载模型
# my_model = load_word2vec_model(my_model_path)
#
# # 找相近词
# calculate_most_similar(my_model, "大众")
# # 两个词相似度
# calculate_words_similar(my_model, "奔驰", "奥迪")
# # 词向量
# print(my_model.wv.__getitem__('车'))
# my_lists = ["奔驰", "奥迪", "大众", "唐"]
#
# find_word_dis_match(my_model, my_lists)
- 效果
与“大众”相似的 top10:
血统 0.9097452163696289
低端 0.9042119979858398
大众呢 0.8991310000419617
样 0.8986610770225525
牌子 0.8938345909118652
个人爱好 0.8861078023910522
速腾 0.8810515403747559
韩国 0.8804070949554443
风格 0.8773608207702637
心意 0.875822901725769
(二)问题所在
按理说,上文中逻辑并没有什么问题,不就是文本预处理之后训练词向量吗,那问题出在哪里了?
为了说明问题我们得先说明另一个概念,也就是上面训练词向量时出现的 Skip-Gram 模型(如果想较为全面地了解的话,可看我的另一篇博客:《基于Hierarchical Softmax的CBOW模型》)。
简答来说,Skip-Gram 模型(n-gram 模型)依据马尔科夫假设:下一个词的出现仅依赖于它前面的  个词,实际应用中最常采用的是
个词,实际应用中最常采用的是 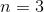 的三元模型(即依赖于该词之前的两个词)。
的三元模型(即依赖于该词之前的两个词)。
现在回想一下刚才文本预处理时,我们去停用词、根据词性筛选特定词等等,最终得到的语料库已经失去了文本原有的语义,这里以我实际的数据为例:
- 原始文本
油耗令人满意,看我的论坛5000公里油耗的文章,最低的时候到过7.2,现在在7.4。
- 文本预处理后的语料库
油耗 论坛 油耗 文章 最低
使用 Skip-Gram 模型 来处理这样的语料库,自然而然会出现准确度太低的原因。
二、解决方法
解决方法其实很简单,我们只需要在文本预处理时不再对文本进行去停用词、根据词性筛选特定词,就可保留文本语义。
直接给出全部代码:
- 分词:split_without.py
import jieba
import re
# 获取结巴分词
def get_split(file_path, car_path, corpus_path):
split = ''
# 标点符号
remove_chars = '[·’!"#$%&\'()*+,-./:;<=>?@,。?★、…【】《》?“”‘’![\\]^_`{|}~]+'
with open(file_path, 'r', encoding='utf-8') as f:
txt = f.read()
# 去除标点符号
txt = re.sub(remove_chars, "", txt)
# 增加专业名词
jieba.load_userdict(car_path)
words = [w for w in jieba.cut(txt, cut_all=False)]
text = ' '.join(words)
split += text
with open(corpus_path, 'w', encoding='utf-8') as f:
f.write(split)
if __name__ == '__main__':
# 源数据路径
my_file_path = r'../../data/result_data/mouth.txt'
# 专业名词路径
my_car_path = r'../../data/jieba_data/car_name.txt'
# 语料库路径
my_corpus_path = r'../../data/result_data/corpus.txt'
# 分词
get_split(my_file_path, my_car_path, my_corpus_path)
word2vec.py 代码当然九不需要修改了。
- 原始文本
油耗令人满意,看我的论坛5000公里油耗的文章,最低的时候到过7.2,现在在7.4。
- 文本预处理后的语料库
油耗 令人满意 看 我 的 论坛 5000 公里 油耗 的 文章 最低 的 时候 到 过 72 现在 在 74
- 效果
与“大众”相似的 top10:
一如既往 0.9303665161132812
长处 0.9040323495864868
心中 0.9030961990356445
新鲜感 0.9028049111366272
德系 0.896550714969635
牌子 0.8938297629356384
耶 0.8930386304855347
德系车 0.8929986953735352
情怀 0.8924524784088135
下滑 0.8921371102333069