深度强化学习——从DQN到DDPG
引言
深度强化学习最近取得了很多进展,并在机器学习领域得到了很多的关注。传统的强化学习局限于动作空间和样本空间都很小,且一般是离散的情境下。然而比较复杂的、更加接近实际情况的任务则往往有着很大的状态空间和连续的动作空间。实现端到端的控制也是要求能处理高维的,如图像、声音等的数据输入。前些年开始兴起的深度学习,刚好可以应对高维的输入,如果能将两者结合,那么将使智能体同时拥有深度学习的理解能力和强化学习的决策能力。2013和2015年DeepMind的DQN可谓是将两者成功结合的开端,它用一个深度网络代表价值函数,依据强化学习中的Q-Learning,为深度网络提供目标值,对网络不断更新直至收敛。DQN用到了两个关键技术,一是用来打破样本间关联性的样本池,二是使训练稳定性和收敛性更好的固定目标网络。DQN可以应对高维输入,而对高维的动作输出则束手无策。随后,同样是DeepMind提出的DDPG,则可以解决有着高维或者说连续动作空间的情境。它包含一个策略网络用来生成动作,一个价值网络用来评判动作的好坏,并吸取DQN的成功经验,同样使用了样本池和固定目标网络,是一种结合了深度网络的Actor-Critic方法。
一、强化学习
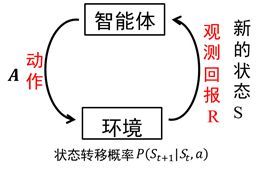
智能体在完成某项任务时,如上图所示,首先通过动作A与周围环境进行交互,在动作A和环境的作用下,智能体会产生新的状态,同时环境会给出一个立即回报。如此循环下去,智能体与环境进行不断地交互从而产生很多数据。强化学习算法利用产生的数据修改自身的动作策略,再与环境交互,产生新的数据,并利用新的数据进一步改善自身的行为,经过数次迭代学习后,智能体能最终地学到完成相应任务的最优动作(最优策略)。这就是一个强化学习的过程。

强化学习所面对的是一个连续决策过程。这一问题框架基于一个MDP过程,即马尔科夫决策过程,如上图所示。智能体面对的环境有一个状态空间X,智能体自己有一个动作空间U,智能体根据状态的观察值O来进行决策。环境动态模型或者说转移概率描述了状态间是如何转化的,策略描述了智能体如何决策。
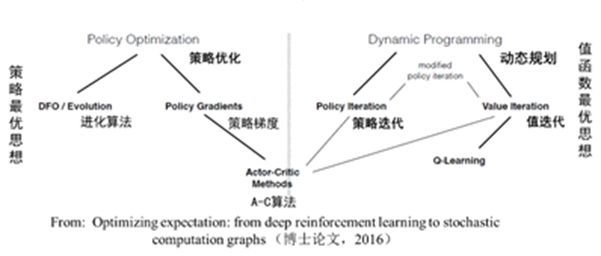
如上图所示,强化学习根据以策略为中心还是以值函数最优可以分为两大类,策略优化 方法和动态规划方法。其中策略优化方法又分为进化算法和策略梯度方法;动态规划方法分为策略迭代算法和值迭代算法。策略迭代算法和值迭代算法可以用广义策略迭代方法进行统一描述。另外,强化学习算法根据策略是否是随机的,分为确定性策略强化学习和随机性策略强化学习。根据转移概率是否已知可以分为基于模型的强化学习和无模型的强化学习算法。另外,强化学习算法中的回报函数r十分关键,根据回报函数是否已知,可以分为强化学习和逆向强化学习。逆向强化学习是根据专家演示将回报函数学习出来。
二、策略梯度
策略梯度方法中,将策略参数化表示为,计算出关于动作的策略函数梯度,不断调整动作,靠近最优策略。策略梯度的计算公式已由相关学者推导得到,且有两种策略梯度,一是随机性策略梯度,二是确定性策略梯度。
1、随机性策略梯度:

2、确定性策略梯度:

证明可参考相关论文。总之,策略梯度的直观理解是调整策略函数的参数,使得其给出的动作可以获得较大的Q值。
Actor-Critic方法是一种很重要的强化学习算法,其是一种时序差分方法(TD method),结合了基于值函数的方法和基于策略函数的方法。其中策略函数为行动者(Actor),给出动作;价值函数为评价者(Critic),评价行动者给出动作的好坏,并产生时序差分信号,来指导价值函数和策略函数的更新。其框架如下图:

将此方法与深度学习结合的话,则是分别用两个深度网络去代表价值函数和策略函数。之后所介绍的DDPG就是基于这样一种Actor-Critic架构的深度强化学习方法。
三、DQN
DeepMind在2013年提出的DQN算法(2015年提出了DQN的改进版本)可以说是深度学习和强化学习的第一次成功结合。要想将深度学习融合进强化学习,是有一些很关键的问题需要解决的,其中的两个问题如下:
1、深度学习需要大量有标签的数据样本;而强化学习是智能体主动获取样本,样本量稀疏且有延迟。
2、深度学习要求每个样本相互之间是独立同分布的;而强化学习获取的相邻样本相互关联,并不是相互独立的。
若想将这两者结合,必须解决包括上面两点在内的问题。
DQN具体来说,是基于经典强化学习算法Q-Learning,用深度神经网络拟合其中的Q值的一种方法。Q-Learning算法提供给深度网络目标值,使其进行更新。先来看Q-Learning的算法流程图:
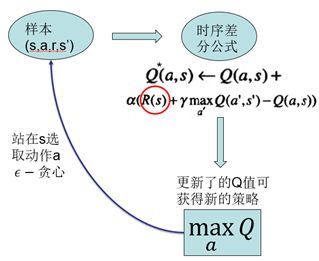
智能体采用off-policy即执行的和改进的不是同一个策略,这通过方法实现。用这种方式采样,并以在线更新的方式,每采集一个样本进行一次对Q函数的更新。更新所依据的是时序差分公式。以更新后的Q函数得到新的策略。而这种经典强化学习算法的局限性在于,无法应对高维的输入,且无法应用于大的动作空间,特别的,无法应用于连续动作输出。DQN所做的是用一个深度神经网络进行端到端的拟合,发挥深度网络对高维数据输入的处理能力。其2013年版本结构如下:

在2015年又发布了其改进版本:
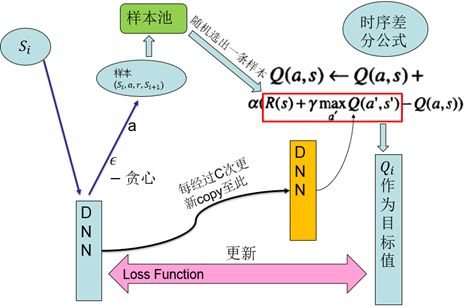
其有两个关键技术:
1、样本池(experience reply):将采集到的样本先放入样本池,然后从样本池中随机选出一条样本用于对网络的训练。这种处理打破了样本间的关联,使样本间相互独立。
2、固定目标值网络(fixed Q-target):计算网络目标值需用到现有的Q值,现用一个更新较慢的网络专门提供此Q值。这提高了训练的稳定性和收敛性。
四、DDPG
DQN是一种基于值函数的方法,基于值函数的方法难以应对的是大的动作空间,特别是连续动作情况。因为网络难以有这么多输出,且难以在这么多输出之中搜索最大的Q值。而DDPG是基于上面所讲到的Actor-Critic方法,在动作输出方面采用一个网络来拟合策略函数,直接输出动作,可以应对连续动作的输出及大的动作空间。
再来回顾一下Acror-Critic结构。如下图:

该结构包含两个网络,一个策略网络(Actor),一个价值网络(Critic)。策略网络输出动作,价值网络评判动作。两者都有自己的更新信息。策略网络通过梯度计算公式进行更新,而价值网络根据目标值进行更新。
DDPG采用了DQN的成功经验。即采用了样本池和固定目标值网络这两项技术。也就是说这两个网络分别有一个变化较慢的副本,该变化较慢的网络提供给更新信息中需要的一些值。DDPG的整体结构如下:

DDPG方法是深度学习和强化学习的又一次成功结合,是深度强化学习发展过程中很重要的一个研究成果。其可以应对高维的输入,实现端对端的控制,且可以输出连续动作,使得深度强化学习方法可以应用于较为复杂的有大的动作空间和连续动作空间的情境。
参考文献:
[1] Silver D, Lever G, Heess N, et al. Deterministic Policy Gradient
Algorithms[C]// International Conference on Machine Learning. 2014:387-395.
[2] Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through
deep reinforcement learning.[J]. Nature, 2015, 518(7540):529.
[3] Mnih V, Kavukcuoglu K, Silver D, et al. Playing Atari with Deep
Reinforcement Learning[J]. Computer Science, 2013.
[4] Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep
reinforcement learning[J]. Computer Science, 2015, 8(6):A187.
注:前四张图片来自别处,如有侵权立即修改。文字及后五张彩色图片为自己写的和画的,尤其是图片画得很用心~