说电影《悲伤逆流成河》
说电影《悲伤逆流成河》
文章目录
- 说电影《悲伤逆流成河》
- 前言
- 爬取猫眼影评
- 数据可视化
- 词云
- 圆饼图
- 热力图
- 对差评点评
前言

电影《悲伤逆流成河》上映已经半个月了,热度消散,为什么现在还要来说呢?基于两点:
- 第一点:无聊,说说电影打发时间嘛;
- 第二点:因为热度消散,无论哪一方的水军都会撤退,数据会更贴近真实。
当然了,第一点是真实原因,第二点在瞎掰。
接下来将分三个部分。第一部分爬取猫眼关于《悲伤逆流成河》的影评存储到MongoDB中,第二部分用爬取到的数据简单实现一下数据可视化,第三部分是对差评的点评。
爬取猫眼影评
事实上直接访问猫眼官网,点进《悲伤逆流成》,浏览器拉到最下就是影评了,问题是我只看到了热门影评,没有加载更多的提示。
这个时候转换策略,可以考虑移动端。但并非一定要用Fiddler等稍微麻烦的工具,有时候浏览器可以帮我们搞定一切。
右键->检查,点击左上角第二个图标
我选择模拟iPhoneX,100%显示。此时你也许需要刷新一下界面,看起来才会正常。
现在就可以查看全部短评了。跟以前的每一次爬虫流程一样,下拉界面,在Network中监测数据,找到了后台接口(http://m.maoyan.com/mmdb/comments/movie/1217236.json)
这个时候我们可以利用requets模块写一个小爬虫,看能否成功返回数据(当然是可以的,因为我已经尝试过了)。
整个过程没有什么难点,但有个意外之处。虽然猫眼说可以查看3.9万的短评,但实际上这个接口只对外公开了1000多条短评。当偏移量(offset)等于1000的时候尚有评论的数据返回,等于1001的时候返回{total: 0}。所以这里有一个需要注意的地方,猫眼每次加载会返回15条评论,偏移量从0开始,到1000结束,如果我们遍历range(0, 1000, 15)来获取offset,事实上是得不到offset=1000的。
我这里的处理方式是构造一个生成器(自然也可以用穷举的策略,但是那样很可能会浪费内存):
class Offset(object):
"""生成偏移量,使其能够包含边界数"""
def __init__(self, left, right, step):
self.left = left
self.right = right
self.step = step
self.count = left
def __iter__(self):
return self
def __next__(self):
if self.count <= self.right:
num = self.count
self.count += self.step
elif (self.right+self.step) > self.count > self.right:
num = self.right
self.count += self.step
else:
raise StopIteration
return num
这样一来,就可以取到右边界的值了:
lyst = []
for offset in Offset(0, 100, 15):
lyst.append(offset)
print(lyst)
# 输出:
#[0, 15, 30, 45, 60, 75, 90, 100]
另一点,为给程序提速,我用了多线程来实现并发。这里我并非用的threading模块,而是concurrent.futures下的ThreadPoolExecutor,用它创建了一个线程池。这样会让程序看起来更简洁:
with ThreadPoolExecutor(max_workers=20) as pool:
# 与python中内置的map()相似
pool.map(main, Offset(0, 1000, 15))
爬虫程序的逻辑如下:
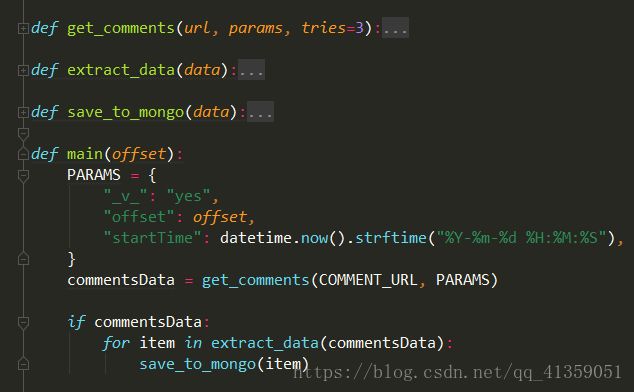
数据在MongoDB中:
前面说过,猫眼提供的这个接口只外放1000来条评论数据,这显然是挺少的。因此我们可以通过每隔一段时间就去访问这个接口,因为总有新的数据覆盖旧的,借此就可以获得更多的评论了。当然,应该有什么东西可以让程序定时自动地运行起来,我没使——
因为不会。其次是反正闲着也是闲着,躺尸在床上的我翻身就能一个“运行”键。
截止此刻,也就是写这篇东西的时候,在MongoDB里存放了2900多条评论(虽然仍然很少)。
数据可视化
这一部分我主要采用了pandas模块对数据进行简单清洗,可视化方面则使用的是wordcloud以及pyecharts。
词云
利用评论生成词云,这样可以有效的看到大多数人对电影的看法。

说实话,9.1的评分不是盖的。事实上我也在首映当天去看了,真心不错。
圆饼图
导入from pyecharts import Pie制作圆饼图。反映评分人数的占比。
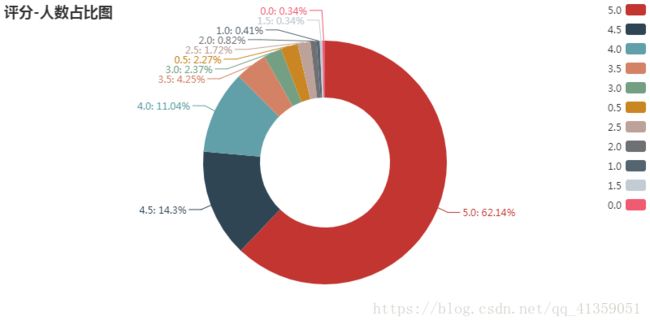
可以看到给4分及以上的人数占有绝对优势。我之前说过了,现在《悲伤逆流成河》的热度已经消散,水军什么的自然对样本的影响也是尽可能低。说明大多数人对电影还是支持的,当然,从之前生成的词云也能得到这个结果。
热力图
导入from pyecharts import Geo。
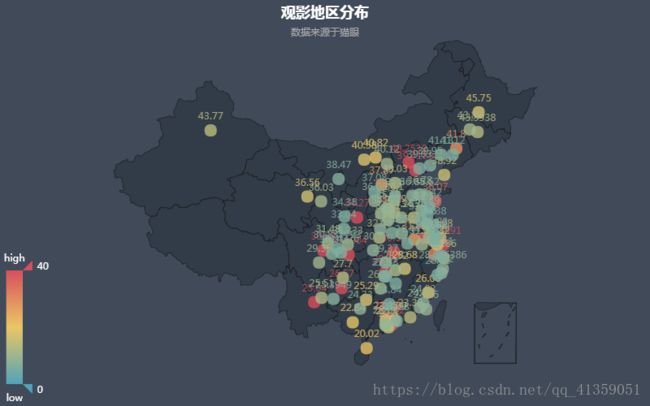
热力图能够反映城市与观影人数的之间的关系,通过左下角滑动滑块可以隐去不需要的部分,并且也可以放大缩小图画来满足自身的需求。
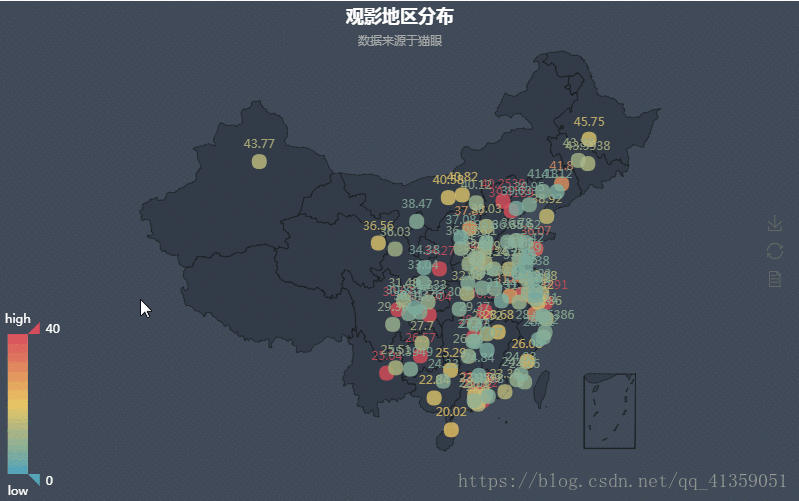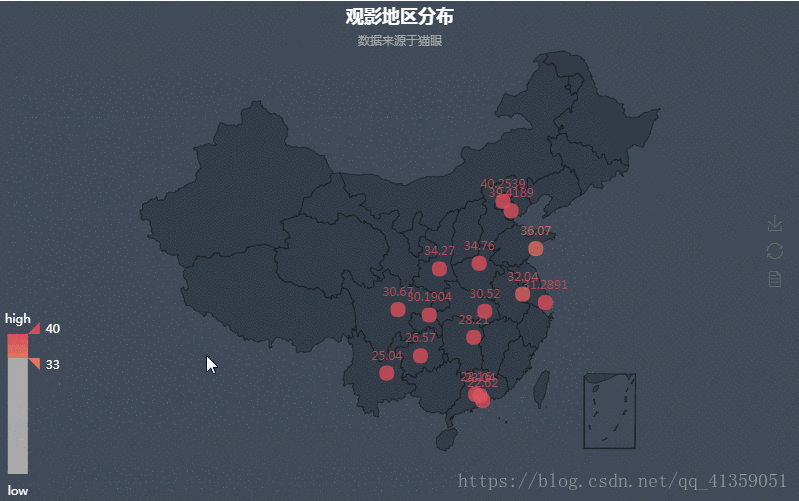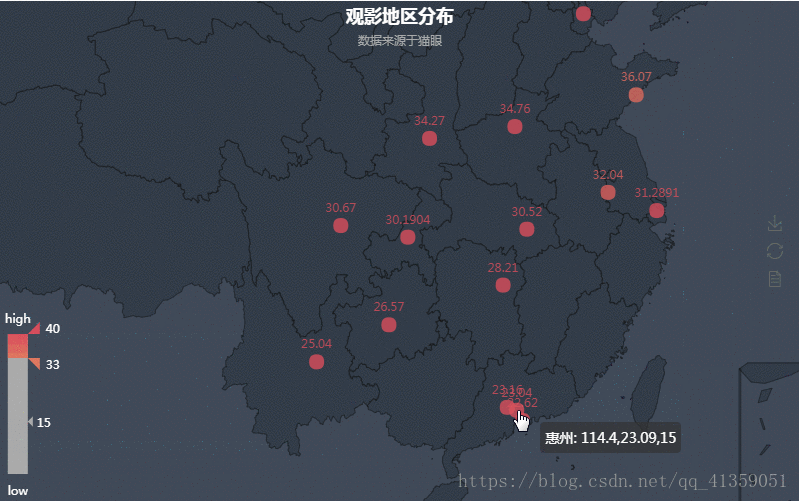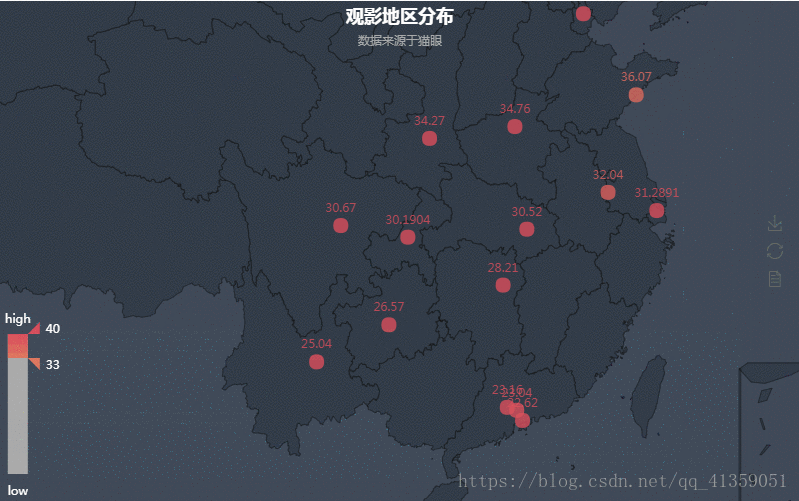
数据经过清洗以后,我这里得到了观影人数前四名的城市:深圳 > 成都 > 广州 > 北京。
有个坑需要特别强调一下。猫眼提供的城市信息在pyecharts的扩展包里可能会有些出入,也就说pyecharts对部分城市会报错:ValueError: No coordinate is specified for 达州(这里报错达州),这是因为它没有达州的坐标信息。起初我挨个手动添加坐标信息,但数据太多,浪费时间,最后在网上找到一个网友在GitHub上提供的坐标集合(https://github.com/focusxia/echarts-map-data.json)
添加方式:geo.add_coordinate_json(CITY_JSON_FILE) # 参数为json文件路径
但仍不能面面俱到,最后我决定把数量少的城市过滤到。不可否认,一些耳熟能详的城市,观影人数一般不会太少。(其实这个处理手段不是很好,应该有更好的方法)
# 只保留观影人数大于5的城市
cleanedData = {key:cityPerson[key] for key in cityPerson if cityPerson[key]>5}
但随着样本数量的增大,过滤人数小于5的方法可能就不奏效了。其实用占比更妥当些。
对差评点评
差评总是存在的。事实上在淘宝,无论这家店卖出的东西有多好,都会存在差评。所以我过滤拿到了《悲伤逆流成河》的差评,并存放到txt文件中。让我们来看看这些差评到底有多理直气壮吧!
# 获取差评
def bad_comments(self):
"""以低于3分为标准,认为是差评, 保存指定txt文本中"""
# 数据过滤,只保留差评
badComments = [(item[2], item[3]) for item in self.data if item[2]<3]
# 对差评排序
sortedComments = sorted(badComments, key=lambda item: item[0])
# 写入txt文件
with open(BAD_COMMENTS_TXT, "w", encoding="utf-8") as file:
for comment in sortedComments:
file.write("{}\n".format(str(comment)))
效果如下:
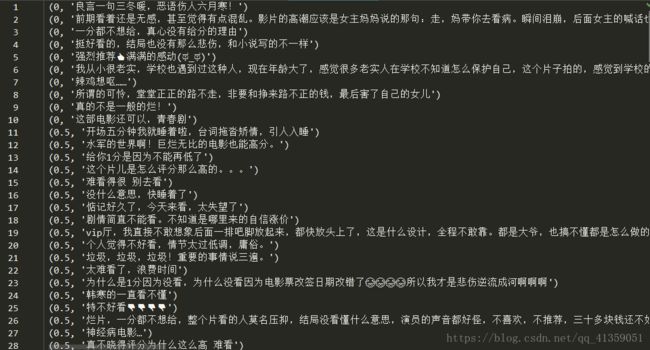
说明:左边为电影评分,右边为短评内容
差评1:(0, '良言一句三冬暖,恶语伤人六月寒!')
点评:你永远不知道别人会因为什么而不喜欢你(到底这句话和0分有什么关系呀!!!)
差评2:(0, '挺好看的,结局也没有那么悲伤,和小说写的不一样')
点评:所以这就是你给0分的原因?就是因为挺好看?然而这样的人不止一个,如:(0, '强烈推荐?满满的感动(ಥ_ಥ)')
差评3:(0.5, '韩寒的一直看不懂')
点评:谢谢,这是落落导的(不过老实说,韩寒的电影我也看不懂。)
差评4:
(0.5, '弘扬负能量,只能给1分。')(0.5, '这种爱情片子很恶心呀,')
点评:我一直以为中国对语文课,或者说阅读理解这一部分需要加强加强再加强。
差评5:(0.5, '滚!我过生日给我看这种烂片 还9.1分')
点评:老实说,不是我性别歧视,而是这样口气的一般都是女生。自从有了“小仙女”这个称号后,有些女生就飘了,真以为自己在天上一样。你过生很了不起吗?
差评6:(0.5, '不论电影如何,只要是郭敬明的电影,就该是低分')
点评:也不知道这个人是不是郭敬明的前前女友……
差评7:(1, '简直差评啊,跟书上不一样')
点评:因为跟原著不一样而给低分大有人在,我一直跟不上这群原著党的思维。我也是一个爱看书的人,但从根本上认可任何原著与其电影与其电视剧存在差异。
差评8:(2, '分是买的!鉴定完毕')
点评:这部分人通常会对自己不满意的高分电影推断,煞有介事的说:“因为水军”,这种人以自我为中心。大概以为地球是绕着它在转吧。我不喜欢国外许多大片,但它们通常能在中国市场捞得盆满钵满,怎么,因为水军?
差评9:(2.5, '替人买票,听闻还行')
点评:hhhhh,所以还行就是你给的2.5分的理由?
差评10:(2.5, '作为一个没有看过郭敬明作品的00后\n我想说这部电影承袭了郭敬明的作品一贯风格\n对上的是中学生的胃口 我无感\n但片中也有突破的方面 甚感欣慰')
点评:既然没看过人家的作品,风格一说何来?
太多太多,没办法一一细说了。但可以从上看出来,那些给差评的人有多随便,要么性格上存在缺陷,要么智商上需要训练。总的来说,尽管存在一些瑕疵,电影的好绝对大于坏的。也有人说台词矫情了些。但作为80、90后的我们,历经非主流时代,那时候的我们说话难道不矫情吗?我QQ空间里还残存一些矫情的话语。这真的很写真。
关于认知方面。一件事物的好坏应该自己评判,可我见过许多人是做不到这一点的,记得当初看电影《爵迹》,周围就有朋友跟我说:“诶听说挺难看的你居然还去”。又是“听说”?难不成自己只有耳朵没有眼睛?我不是一个随波逐流之人,我有自己的三观,有自己的审美能力以及标准。谁也别想对我强加认知,但我会参考一些恰当的看法。
当然,以上我的观点并不能做到真正的公平公正。
因为利益相关。因为喜欢。
在这里期待我落下一部电影(小说也行啊!哈哈哈)
完整代码已上传GitHub