Python-爬取知乎热搜榜单信息
Python-爬取知乎热搜榜单信息(request、selenium两种方式)
对于selenium的介绍,在我之前的文章中就已经说过了,不再赘述。这里主要是通过正则表达式的方式来拿到节点中的信息,下面展示下代码和效果图。
- 爬虫地址
https://www.zhihu.com/billboard
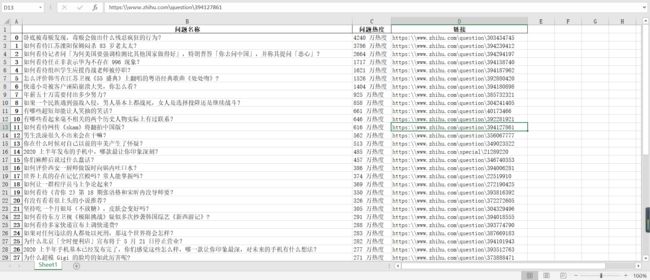
- 成果预览
- 实现代码1-request库
# -*- coding: utf-8 -*-
"""
@File : request200512_知乎热搜榜.py
@Author : [email protected]
@Time : 2020/03/07 17:41
@notice : 爬取知乎热搜榜列表&热度&链接
"""
import re
import requests
import datetime
import pandas as pd
from fake_useragent import UserAgent
Domain_Name = 'https:'
headers = {
'User-Agent': UserAgent().random,
'Referer': "https://www.zhihu.com/billboard"
}
url = 'https://www.zhihu.com/billboard'
response = requests.get(url, headers=headers)
html = response.text
print('----------------分割线----------------')
# 这里通过正则来解析页面
content = re.findall(r'([\s\S]+?)', html, re.M) # 获取问题内容
hot = re.findall(r'([\s\S]+?)', html, re.M) # 获取问题热度
url = re.findall(r'"link":{"url":"([\s\S]+?)"}},', html, re.M) # 获取问题超链接
describe = re.findall(r'"excerptArea":{"text":"([\s\S]+?)"},', html, re.M) # 获取问题超链接
dts = []
for i in range(len(content)):
lst = []
lst.append(content[i])
lst.append(hot[i])
lst.append(str(url[i]).replace('u002F', ''))
dts.append(lst)
df = pd.DataFrame(dts, columns=['问题名称', '问题热度', '链接'])
df.to_excel('./zhihu热搜榜' + str(datetime.datetime.now().strftime('%Y%m%d')) + '.xlsx',
encoding='gbk') # 写入excel中
print('爬取完成')
- 实现代码-selenium库
# -*- coding: utf-8 -*-
"""
@File : selenium200512_知乎热搜榜.py
@Author : [email protected]
@Time : 2020/03/07 17:41
@notice : 爬取知乎热搜榜列表&热度&链接
"""
import re
import time
import datetime
import pandas as pd
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.zhihu.com/billboard')
print('当前页面标题:' + driver.title)
print('当前页面地址:' + driver.current_url)
print('----------------分割线----------------')
html = driver.page_source
# dataList = html.xpath('//div[@class="HotList-itemTitle"]/text()')#获取问题内容
# 这里通过正则来解析页面
content = re.findall(r'([\s\S]+?)', html, re.M) # 获取问题内容
hot = re.findall(r'([\s\S]+?)', html, re.M) # 获取问题热度
url = re.findall(r'"link":{"url":"([\s\S]+?)"}},', html, re.M) # 获取问题超链接
describe = re.findall(r'"excerptArea":{"text":"([\s\S]+?)"},', html, re.M) # 获取问题超链接
time.sleep(1) # 操作暂停一秒
driver.close() # 关闭浏览器
dts = []
for i in range(len(content)):
lst = []
lst.append(content[i])
lst.append(hot[i])
lst.append(str(url[i]).replace('u002F', ''))
dts.append(lst)
df = pd.DataFrame(dts, columns=['问题名称', '问题热度', '链接'])
df.to_excel('./zhihu-hotkeyData' + str(datetime.datetime.now().strftime('%Y%m%d')) + '.xlsx',
encoding='gbk') # 写入excel中
print('爬取完成')
- 结尾
喜欢的朋友们可以点个关注,后续将持续更新,精彩无限^ - ^