我的大数据之路--2019拉钩网爬取(破解反爬虫)
拉钩拉钩,你都不给我钩,我怎么拉呀
序言:号称爬虫界的喜马拉雅–拉钩,今天看看威力如何吧!!!
只是用作简单学习,想要获得大数据,请联系拉钩工程师。
一、打开网页,输入数据挖掘。右键查看源代码(谷歌浏览器),发现什么鸟数据都没有。猜测是Ajax请求。然后F12分析源码

打开在线解析json 点这里 ,把Response返回的JSON格式输入进去,看是不是我们想要的。

恩恩,是这个没错了。接下来就搞它。
二、点开Headers,发现是个post请求,url单独请求肯定请求不到。

果然出现报错:

三、分析原因
1)不愧是爬虫界大佬,连真实的浏览器都封杀。
2)没有添加POST请求,另开一网页的可能你的Cookie已经发生变化,浏览器识别不到。
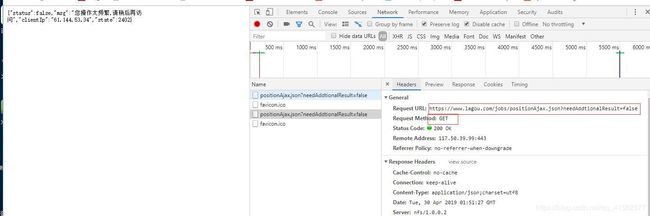
一开始本来是post请求的,另起一网页的时候已经成为get请求,当然请求不到。
四、开始写爬虫,单纯的添加
https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false 进行requets亲测不行。拉钩的机制要首先访问如下url
https://www.lagou.com/jobs/list_python?city=全国&cl=false&fromSearch=true&labelWords=&suginput=
获取其中的Cookie,再保持访问不中断的情况下,再请求下面那个url,这时的请求才会是post请求
https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false
lagou.py
#添加包
import random
import json
import requests
import time
lagou=open('lagou.txt','w',encoding='utf-8') #创建一个文本文档
def req(page):
first_url = 'https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput='
second_url = "https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false"
#构造足够多的浏览器
user_agent = [
'Mozilla/5.0 (Windows NT 6.1; rv:50.0) Gecko/20100101 Firefox/50.0',
'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Mozilla/5.0 (X11; Linux x86_64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.36',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; Trident/5.0)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/602.2.14 (KHTML, like Gecko) Version/10.0.1 Safari/602.2.14',
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36',
'Mozilla/5.0 (iPad; CPU OS 10_1_1 like Mac OS X) AppleWebKit/602.2.14 (KHTML, like Gecko) Version/10.0 Mobile/14B100 Safari/602.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:49.0) Gecko/20100101 Firefox/49.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
num = random.randint(0, 9) ##定义随机函数抽取浏览器访问
user_agent = user_agent[num]
#给全所有的headers
headers={
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content - Length': '55',
'Content - Type': 'application / x - www - form - urlencoded; charset = UTF - 8',
'Host': 'www.lagou.com',
'Origin': 'https: // www.lagou.com',
'Pragma': 'no-cache',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'User-Agent': str(user_agent),
'X - Anit - Forge - Code': '0',
'X - Anit - Forge - Token': 'None',
'X - Requested - With': 'XMLHttpRequest'
}
#在给表单参数,由于在第一页中的first和之后几页的first不同,所以需要判断
if page==1:
datas={
'first': 'true',
'pn': page,
'kd': '数据挖掘'
}
else:
datas = {
'first': 'false',
'pn': page,
'kd': '数据挖掘'
}
s=requests.Session() #持续保持通信
s.get(url=first_url,headers=headers,timeout=4) #开始构造第一个请求,获取cookie,,first_url为get请求
cookings=s.cookies
html=s.post(url=second_url,headers=headers,data=datas,cookies=cookings,timeout=3) #将得到的cookie继续请求senond_url,这样虽然会变得很慢,但是能爬
time.sleep(5) #在停它5秒
content=json.loads(html.text).get('content') #解析返回来的json
txt=json.dumps(content,ensure_ascii=False) #转为字符串,而且设置编码
lagou.write(txt) #书写
lagou.write('\n')
req(page+1) #回调函数
if __name__=='__main__':
req(1)
经测试,爬成功了,但是不让你爬那么多。
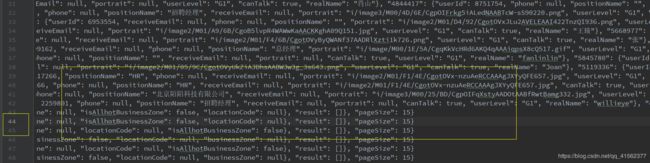
继续分析原因,刚刚说的cookie还没解析,现在解析一下
复制第一页的cookie

第二页的cookie

第三页的cookie

第一种猜测,cookie的变化是根据时间戳来变化的。所以首先寻找看看有没有类似时间的标识。
为了更好的分析,建议放在Notepad++上
根据查看,猜测有个LGRID的好像是个时间戳,反正可以试一试。接下来我们改改代码,将这个LGRID给变掉
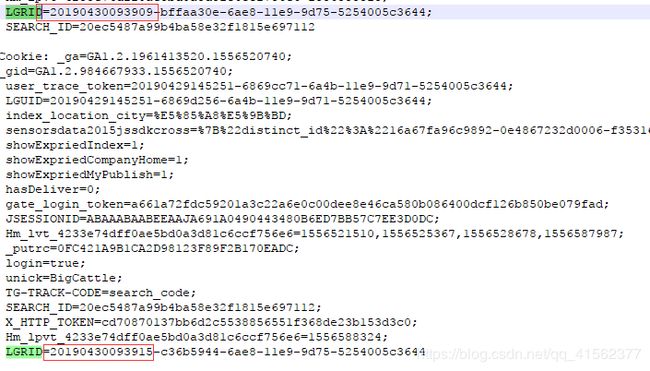
第二种代码测试,主要变化 LGRID={}-c36b5944-6ae8-11e9-9d75-5254005c3644’.format(time_now)
lagou2.py
import random
import json
import requests
import time
import datetime
lagou=open('lagou3.txt','w',encoding='utf-8')
def req(page):
#url1 = 'https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput='
url = "https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false"
now=datetime.datetime.now()
time_now = datetime.datetime.strftime(now, "%Y%m%d%H%M%S")
user_agent = [
'Mozilla/5.0 (Windows NT 6.1; rv:50.0) Gecko/20100101 Firefox/50.0',
'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Mozilla/5.0 (X11; Linux x86_64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.36',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; Trident/5.0)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/602.2.14 (KHTML, like Gecko) Version/10.0.1 Safari/602.2.14',
'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36',
'Mozilla/5.0 (iPad; CPU OS 10_1_1 like Mac OS X) AppleWebKit/602.2.14 (KHTML, like Gecko) Version/10.0 Mobile/14B100 Safari/602.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:49.0) Gecko/20100101 Firefox/49.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:50.0) Gecko/20100101 Firefox/50.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:45.0) Gecko/20100101 Firefox/45.0'
]
num = random.randint(0, 9) ##定义随机函数
user_agent = user_agent[num] ##用随机函数抽取
headers={
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content - Length': '55',
'Content - Type': 'application / x - www - form - urlencoded; charset = UTF - 8',
'Host': 'www.lagou.com',
'Origin': 'https: // www.lagou.com',
'Pragma': 'no-cache',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'User-Agent': str(user_agent),
'Cookie': '_ga=GA1.2.1961413520.1556520740; _gid=GA1.2.984667933.1556520740; user_trace_token=20190429145251-6869cc71-6a4b-11e9-9d71-5254005c3644; LGUID=20190429145251-6869d256-6a4b-11e9-9d71-5254005c3644; index_location_city=%E5%85%A8%E5%9B%BD; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216a67fa96c9892-0e4867232d0006-f353163-2073600-16a67fa96caa58%22%2C%22%24device_id%22%3A%2216a67fa96c9892-0e4867232d0006-f353163-2073600-16a67fa96caa58%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; gate_login_token=a661a72fdc59201a3c22a6e0c00dee8e46ca580b086400dcf126b850be079fad; JSESSIONID=ABAAABAABEEAAJA691A0490443480B6ED7BB57C7EE3D0DC; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1556521510,1556525367,1556528678,1556587987; _putrc=0FC421A9B1CA2D98123F89F2B170EADC; login=true; unick=BigCattle; TG-TRACK-CODE=search_code; SEARCH_ID=20ec5487a99b4ba58e32f1815e697112; X_HTTP_TOKEN=cd70870137bb6d2c5538856551f368de23b153d3c0; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1556588324; LGRID={}-c36b5944-6ae8-11e9-9d75-5254005c3644'.format(time_now),
'X - Anit - Forge - Code': '0',
'X - Anit - Forge - Token': 'None',
'X - Requested - With': 'XMLHttpRequest'
}
if page==1:
datas={
'first': 'true',
'pn': page,
'kd': '数据挖掘'
}
else:
datas = {
'first': 'false',
'pn': page,
'kd': '数据挖掘'
}
html=requests.post(url=url,headers=headers,data=datas,timeout=3)
time.sleep(7)
#print(html.text)
content=json.loads(html.text).get('content')
print(content)
wr=json.dumps(content,ensure_ascii=False)
lagou.write(wr)
lagou.write('\n')
req(page+1)
if __name__=='__main__':
req(1)
哈哈,一样可以成功,但是,拉钩超坏,都不给我爬超过50条。但是能爬还是挺开心的。

爬多数据的话,给个思路:
1、ip代理池是必须的了(真的花钱买的那种,不是网上随便抓的那种,不然没用),而且拉钩有一个机制是识别ip的。
2、拉钩数据的获取最重要的是cookie的构造,我猜测每个登录进拉钩的cookie,拉钩在后台都有一个记录机制,别说是爬虫了,就算是真是浏览器,拉钩都不给你看,还能不能好好的玩耍了??

3、我觉得拉钩另外还有一层,除了positionAjax.json之外,拉钩肯定还会有其他的json多个集中在一起的构造,之后有时间在lu它。就像解析会员视频的加密信息一样,要花的时间太多了。但是,爬虫不能投降
4、以上纯属瞎编。如有影响,立即删除!