paper reading:Part-based Graph Convolutional Network for Action Recognition
paper reading:Part-based Graph Convolutional Network for Action Recognition
文章目录
- paper reading:Part-based Graph Convolutional Network for Action Recognition
- graph 与 skeleton:
- 传统的 action recognition from S-videos:
- 本文模型使用的两种信息:
- 本文主要贡献:
- 单图(无划分)的卷积公式:
- k-th neighborhood
- 1-th neighborhood
- Part-based Graph
- 图的划分的定义:
- two parts (b):
- four parts (c ) (推荐):
- six part (d) :
- 子图的连接:
- Part-based Graph Convolutions
- 邻域:
- 卷积:
- 子图卷积:
- 子图卷积结果聚合:
- Spatio-temporal Part-based Graph Convolutions
- 卷积的步骤
- 邻域的划分
- 标签的给定
- 卷积的全部公式!!!
- 子图的空间卷积
- 子图空间卷积的聚合
- 时域卷积
- 时域卷积
graph 与 skeleton:
Human skeleton is intuitively represented as a sparse graph with joints as nodes and natural connections between them as edges.
- nodes:joints
- edges:natural connections between joints
传统的 action recognition from S-videos:
- the whole skeleton is treated as a single graph
- 使用 3D coordinate
本文模型使用的两种信息:
- Geometric features:such as relative joint coordinates
- motion features:such as temporal displacements
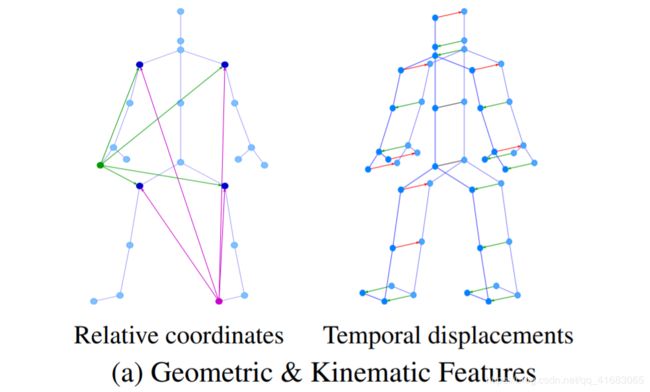
本文主要贡献:
-
Formulation of a general part-based graph convolutional network (PB-GCN) .
-
Use of geometric and motion features in place of 3D joint locations at each vertex.
即,几何信息(relative joint coordinates)和运动信息(temporal displacements)的使用
-
Exceeding the state-of-the-art on challenging benchmark datasets NTURGB+D and HDM05.
单图(无划分)的卷积公式:
k-th neighborhood
Y ( v i ) = ∑ v j ∈ N k ( v i ) W ( L ( v j ) ) X ( v j ) Y(v_i) = \sum_{v_j\in \ N_k (v_i)} W(L(v_j))X(v_j) Y(vi)=vj∈ Nk(vi)∑W(L(vj))X(vj)
- W ( ⋅ ) W(·) W(⋅): a filter weight vector of size of L L L indexed by the label assigned to neighbor v j v_j vj in the k k k-neighborhood N k ( v i ) N_k(v_i) Nk(vi)
- X ( v j ) X(v_j) X(vj):the input feature at v j v_j vj
- Y ( v j ) Y(v_j) Y(vj) :convolved output feature at root vertex v i v_i vi
1-th neighborhood
将邻域 N k ( v i ) N_k(v_i) Nk(vi)换一种表示形式(用邻接矩阵 A A A表示),且将邻域数从 k k k降为1,则得到下面的式子
Y ( v i ) = ∑ j A n o r m ( i , j ) W ( L ( v j ) ) X ( v j ) Y(v_i) = \sum_j A^{norm}(i, j) W(L(v_j)) X(v_j) Y(vi)=j∑Anorm(i,j)W(L(vj))X(vj)
- D ( i , i ) = ∑ j ( i , j ) D(i,i) = \sum_j(i,j) D(i,i)=∑j(i,j); A n o r m = D − 1 / 2 A D − 1 / 2 A^{norm}=D^{-1/2}AD^{-1/2} Anorm=D−1/2AD−1/2
Part-based Graph
In general, a part-based graph can be constructed as a combination of subgraphs where each subgraph has certain properties that define it.
图的划分的定义:
We consider scenarios in which the partitions can share vertices or have edges connecting them.
即,一个图被划分为不同的子图,不同的子图会共享顶点或共享边。
G = ⋃ p ∈ { 1 , . . . , n } P p ∣ P p = ( V p , ε p ) G = \bigcup_{p \in \{1,...,n\}} P_p |P_p=(V_p, \varepsilon _p) G=p∈{1,...,n}⋃Pp∣Pp=(Vp,εp)
- P p P_p Pp is the partition (or subgraph) p p p of the graph G G G

two parts (b):
- Axial skeleton
- Appendicular skeleton
four parts (c ) (推荐):
- head
- hands
- torso
- legs
We consider left and right parts of hands and legs together in order to be agnostic to laterality [31] (handedness / footedness) of the human when performing an action.
即,排除侧向性的干扰(左手招手和右手招手都是招手)。
six part (d) :
we divide the upper and lower components of appendicular skeleton into left and right (shown in Figure 1(d)), resulting in six parts
子图的连接:
图的连接有两种方式:点连接 & 边连接。此处采用的是点连接。
To cover all natural connections between joints in skeleton graph, we include an overlap of at least one joint between two adjacent parts.
即,每个子图之间有至少有一个公用的node。
Part-based Graph Convolutions
不同于上述提到的单图的卷积公式(Eq.2) ,划分为子图后,graph有新的卷积公式。
同时,有几个概念需要重新定义。
邻域:
- 空间邻域(Spatial neighbor):单个 frame 下(特定时间)一阶邻域(Figure 3(a))。
- 时间邻域(Temporal neighbor):单个 node 的 不同的时间的位置(Figure 3(a))。
- 时空邻域(Spatial-temporal neighbor):时空邻域的并集(Figure 3(b))。
卷积:
graph convolutions over a part identifies the properties of that subgraph and an aggregation across subgraphs learns the relations between them.
For a part-based graph, convolutions for each part are performed separately and the results are combined using an aggregation function F a g g F_{agg} Fagg
即,先通过子图内卷积(一阶邻域),再通过聚合函数 F a g g F_{agg} Fagg计算各子图的联系。
公式表达如下:
子图卷积:
Y p ( v i ) = ∑ v j ∈ N k p ( v i ) W p ( L p ( v j ) ) X p ( v j ) , p ∈ 1 , . . . , n Y_p(v_i) = \sum_{v_j\in N_{kp}(v_i)} W_p(L_p(v_j)) X_p(v_j), p \in {1,...,n} Yp(vi)=vj∈Nkp(vi)∑Wp(Lp(vj))Xp(vj),p∈1,...,n
- W p W_p Wp can be shared across parts or kept separate, while the neighbors of v i v_i vi only in that part ( N k p ( v i ) N_{kp}(v_i) Nkp(vi)) are considered
子图卷积结果聚合:
边共享形式:
Y ( v i ) = F a g g ( Y p 1 ( v i ) , Y p 2 ( v j ) ) ∣ ( v i , v j ) ∈ ε ( p 1 , p 2 ) , ( p 1 , p 2 ) ∈ { 1 , . . . , n } × { 1 , . . . , n } Y(v_i) = F_{agg}(Y_{p1}(v_i),Y_{p2}(v_j)) | (v_i, v_j) \in \varepsilon(p1,p2), (p1, p2) \in \{1,...,n\} × \{1,...,n\} Y(vi)=Fagg(Yp1(vi),Yp2(vj))∣(vi,vj)∈ε(p1,p2),(p1,p2)∈{1,...,n}×{1,...,n}
顶点共享形式:
Y ( v i ) = F a g g ( Y p 1 ( v i ) , Y p 2 ( v i ) ) ∣ ( p 1 , p 2 ) ∈ { 1 , . . . , n } × { 1 , . . . , n } Y(v_i) = F_{agg}(Y_{p1}(v_i),Y_{p2}(v_i)) | (p1, p2) \in \{1,...,n\} × \{1,...,n\} Y(vi)=Fagg(Yp1(vi),Yp2(vi))∣(p1,p2)∈{1,...,n}×{1,...,n}
Spatio-temporal Part-based Graph Convolutions
卷积的步骤
The S-videos are represented as spatio-temporal graphs.
即,S-video 的本质是 spatio-temporal graphs.
we spatially convolve each partition independently for each frame, aggregate them at each frame and perform temporal convolution on the temporal dimension of the aggregated graph.
即大致分为两步,细致可分为3步:
- Spatial convolution(空间卷积):
- 子图卷积:spatially convolve each partition independently for each frame
- 子图卷积结果聚合:aggregate result of partition convolution at each frame
- Temporal convolution(时间卷积):
- 对聚合结果进行时间卷积:temporal convolution on the temporal dimension of the aggregated graph。
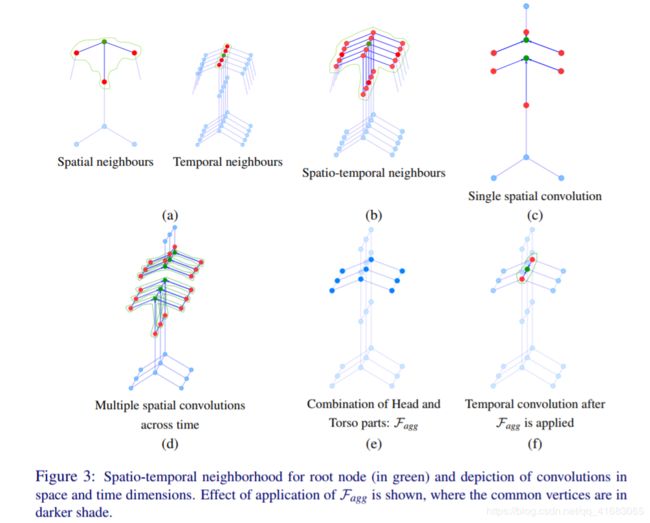
邻域的划分
For each vertex, we use 1-neighborhood ( k k k = 1) for spatial dimension ( N 1 N_1 N1) as the skeleton graph is not very large and a τ τ τ-neighborhood ( k k k = τ τ τ) for the temporal dimension ( N τ N_τ Nτ ), N τ N_τ Nτ is not part-specific.
空间邻域和时间邻域的划分,由下式表示:
N 1 p ( v i ) = { v j ∣ d ( v i , v j ) ≤ 1 , v i , v j ∈ V p } N_{1p}(v_i) = \{ v_j | d(v_i, v_j) ≤ 1, v_i, v_j \in V_p\} N1p(vi)={vj∣d(vi,vj)≤1,vi,vj∈Vp}
N τ ( v i t a ) = { v i t b ∣ d ( v i t a , v i t b ) ≤ ∣ τ 2 ∣ } N_τ (v_{it_a}) = \{v_{it_b} | d(v_{it_a}, v_{it_b}) ≤|\frac{τ}{2}|\} Nτ(vita)={vitb∣d(vita,vitb)≤∣2τ∣}
标签的给定
For ordering vertices in the receptive fields (or neighborhoods), we use a single label spatially ( L S : V → { 0 } ) L_S : V → \{0\}) LS:V→{0}) to weigh vertices in N 1 p N_{1p} N1p of each vertex equally and τ τ τ labels temporally ( L T : V → { 0 , . . . , τ − 1 } L_T : V → \{0,..., τ −1\} LT:V→{0,...,τ−1}) to weigh vertices across frames in N τ N_τ Nτ differently.
即,对于 root 节点,空间邻域内 label 相同(为0),时间邻域内 label 不同。
公式表达如下:
L S ( v j t ) = { 0 ∣ v j t ∈ N 1 p ( v i t ) } L_S(v_{jt}) = \{0 | v_{jt} \in N_{1p}(v_{it})\} LS(vjt)={0∣vjt∈N1p(vit)}
L T ( v i t b ) = { ( ( t b − t a ) + ∣ τ 2 ∣ ) ∣ v i t b ∈ N τ ( v i t a ) } L_T (v_{it_b}) = \{((t_b −t_a) +|\frac{τ}{2}|) | v_{it_b} ∈ N_τ (v_{it_a} )\} LT(vitb)={((tb−ta)+∣2τ∣)∣vitb∈Nτ(vita)}
卷积的全部公式!!!
子图的空间卷积
Z p ( v j t ) = W p ( L S ( v j t ) ) X p ( v j t ) Z_p(v_{jt}) = W_p(L_S(v_{jt})) X_p(v_{jt}) Zp(vjt)=Wp(LS(vjt))Xp(vjt)
- W p ∈ R C ′ × C × 1 × 1 W_p \in \R^{C \ ' × C × 1 × 1} Wp∈RC ′×C×1×1:part-specific channel transform kernel (pointwise operation)
- L S L_S LS for each part is same but N 1 p N_{1p} N1p is part-specific
- Z p Z_p Zp:output from applying W p W_p Wp on input features X p X_p Xp at each vertex
Y p ( v i t ) = ∑ v j t ∈ N 1 p ( v i t ) A p ( i , j ) Z p ( v j t ) ∣ p ∈ { 1 , . . . , 4 } Y_p(v_{it}) = \sum_{v_{jt} \in N_{1p}(v_{it})} A_p(i, j)Z_p(v_{jt}) | p \in \{1,...,4\} Yp(vit)=vjt∈N1p(vit)∑Ap(i,j)Zp(vjt)∣p∈{1,...,4}
- A p A_p Ap:normalized adjacency matrix for part p p p
- W T ∈ R C ′ × C ′ × τ × 1 W_T \in \R^{C \ ' ×C \ '×τ×1} WT∈RC ′×C ′×τ×1:temporal convolution kernel
子图空间卷积的聚合
Y S ( v i t ) = F a g g ( { Y 1 ( v i t ) , . . . , Y n ( v i t ) } ) Y_S(v_{it}) = F_{agg}(\{Y_1(v_{it}),...,Y_n(v_{it})\}) YS(vit)=Fagg({Y1(vit),...,Yn(vit)})
- Y s Y_s Ys:output obtained after aggregating all partition graphs at one frame
时域卷积
Y T ( v i t a ) = ∑ v j t b ∈ N τ ( v i t a ) W T ( L T ( v i t b ) ) Y S ( v i t b ) Y_T (v_{it_a}) = \sum_{v_{jt_b} \in N_τ (v_{it_a})} W_T (L_T(v_{it_b})) Y_S(v_{it_b}) YT(vita)=vjtb∈Nτ(vita)∑WT(LT(vitb))YS(vitb)
g}({Y_1(v_{it}),…,Y_n(v_{it})})
$$
- Y s Y_s Ys:output obtained after aggregating all partition graphs at one frame
时域卷积
Y T ( v i t a ) = ∑ v j t b ∈ N τ ( v i t a ) W T ( L T ( v i t b ) ) Y S ( v i t b ) Y_T (v_{it_a}) = \sum_{v_{jt_b} \in N_τ (v_{it_a})} W_T (L_T(v_{it_b})) Y_S(v_{it_b}) YT(vita)=vjtb∈Nτ(vita)∑WT(LT(vitb))YS(vitb)
- Y T Y_T YT:output after applying temporal convolution on Y S Y_S YS output of τ frames