利用正则表达式爬取猫眼电影TOP100信息
本文利用requests库和正则表达式爬取了猫眼电影TOP100电影信息,并将电影封面和标题、主演等文字信息保存在了本地。本文完整代码链接:https://github.com/iapcoder/MaoYanTop100。运行里面的spider.py即可。
一、目标
- 练习使用正则表达式
- 使用python爬虫的库requests
- 爬取猫眼电影TOP100榜中电影的标题、主演、上映时间、评分、图片链接等信息
- 将每部电影的图片保存在imgs文件夹里,标题、主演等信息保存在results.txt里
二、 效果展示


三、爬虫分析
1.链接分析
抓取的网站为:https://maoyan.com/board/4,打开后便可以看到如下信息:
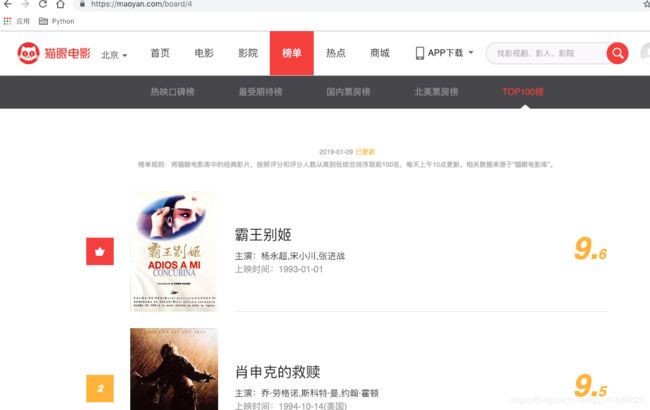 首页信息
首页信息
该页面显示的已经包含我们所需要的信息。 拉到页面下方,发现一共有10页,点击第二页,网页的链接变为:https://maoyan.com/board/4?offset=10,点击第三页链接变为:https://maoyan.com/board/4?offset=20,分析规律可以得出第i页的链接为http://maoyan.com/board/4?offset=10*(i-1)。
2.抓包分析
# -*- coding: utf-8 -*-
import requests
def main():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
url = 'https://maoyan.com/board/4'
response = requests.get(url, headers=headers).content.decode()
print(response)
if __name__ == '__main__':
main()运行上面代码,便可获取该链接的网页源代码,另一个简单的分析方法就式利用Chrome浏览器的开发者工具,注:不要在Elements选项卡里查看源代码,因为这是经过javascript渲染过的,不是我们通过爬虫获取的源代码,需要在Network选项卡里查看。
3.正则提取
在Network选项卡里查看源代码,分析可知每一部电影的信息用一组
标签包裹,打开其中一个标签,如下图
分析可知:
排名信息是在class为'board-index'的i标签内,因此正则表达式为:
.*?board-index.*?>(.*?).*? 图片链接 信息是在a标签下class为data-src的img标签里,正则表达式为:
.*?data-src="(.*?)".*? 电影名称信息是在class为name的p标签的a节点里,正则表达式为:
.*?name.*?a.*?>(.*?).*? 演员信息是在class为star的p标签里,正则表式为:
.*?star.*?>(.*?).*? 上映时间是在class为releasetime的p标签里,正则表达式为:
.*?releasetime.*?>(.*?).*? 评分是在class为score的i标签里,其中包括整数部分和小数部分,正则表达式为:
.*?integer.*?>(.*?).*?fraction.*?>(.*?).*? 接下来,通过正则便可以提取相应的内容信息了
def get_one_page(url, headers):
response = requests.get(url, headers=headers)
html_str = response.content.decode()
pattern = re.compile(
'.*?board-index.*?>(.*?)<.*?data-src="(.*?)".*?name.*?a.*?>(.*?).*?star.*?>(.*?).*?releasetime.*?>(.*?).*?integer.*?>(.*?).*?fraction.*?>(.*?).*? ',
re.S)
items = re.findall(pattern, html_str)
for item in items:
yield {
'rank': item[0], # 排名
'img_url': item[1], # 图片链接
'title': item[2], # 电影名字
'actors': item[3].strip(), # 主演
'date': item[4], # 上映时间
'score': item[5] + item[6] # 评分
}
四、保存图片和电影名字等信息到本地
1.保存图片信息到本地
def save_imgs(item, headers):
response = requests.get(item['img_url'], headers=headers).content
with open('./results/imgs/'+item['rank']+'_'+item['title']+'.jpg', 'wb') as f:
f.write(response)2.保存标题等信息到本地
def write2txt(item, save_path):
with open(save_path, 'a', encoding='utf-8') as f:
f.write(json.dumps(item, ensure_ascii=False, indent=2)+'\n')
五、分页爬取
def main():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
path = './results/imgs'
if not os.path.exists(path):
os.makedirs(path)
url = 'https://maoyan.com/board/4?offset={}'
for i in range(0,100,10):
items = get_one_page(url.format(str(i)), headers)
for item in items:
print(item)
write2txt(item, './results/result.txt') #写入文本
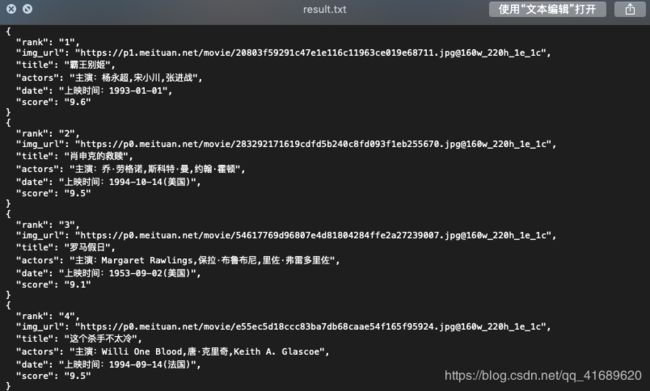
save_imgs(item, headers) # 保存图片到这里就可以爬取整个TOP100的电影信息里,打开results文件夹里的result.txt可以看到如下信息: