Google 机器学习术语表 Part 2 of 4
文章目录
- 1. 背景
- 5. D
- 5.1. 数据分析 (data analysis)
- 5.2. DataFrame
- 5.3. 数据集 (data set)
- 5.4. Dataset API (tf.data)
- 5.5. 决策边界 (decision boundary)
- 5.6. 密集层 (dense layer)
- 5.7. 深度模型 (deep model)
- 5.8. 密集特征 (dense feature)
- 5.9. 设备 (device)
- 5.10. 离散特征 (discrete feature)
- 5.11. 丢弃正则化 (dropout regularization)
- 5.12. 动态模型 (dynamic model)
- 6. E
- 6.1. 早停法 (early stopping)
- 6.2. 嵌套 (embeddings)
- 6.3. 经验风险最小化 (ERM, empirical risk minimization)
- 6.4. 集成学习 (ensemble)
- 6.5. 周期 (epoch)
- 6.6. Estimator
- 6.7. 样本 (example)
- 7. F
- 7.1. 假负例 (FN, false negative)
- 7.2. 假正例 (FP, false positive)
- 7.3. 假正例率(false positive rate, 简称 FP 率)
- 7.4. 特征 (feature)
- 7.5. 特征列 (tf.feature_column)
- 7.6. 特征组合 (feature cross)
- 7.7. 特征工程 (feature engineering)
- 7.8. 特征集 (feature set)
- 7.9. 特征规范 (feature spec)
- 7.10. 少量样本学习 (few-shot learning)
- 7.11. 完整 softmax (full softmax)
- 7.12. 全连接层 (fully connected layer)
- 8. G
- 8.1. 泛化 (generalization)
- 8.2. 广义线性模型 (generalized linear model)
- 8.3. 梯度 (gradient)
- 8.4. 梯度裁剪 (gradient clipping)
- 8.5. 梯度下降法 (gradient descent)
- 8.6. 图 (graph)
- 9. H
- 9.1. 启发法 (heuristic)
- 9.2. 隐藏层 (hidden layer)
- 9.3. 合页损失函数 (hinge loss)
- 9.4. 维持数据 (holdout data)
- 9.5. 超参数 (hyperparameter)
- 9.6. 超平面 (hyperplane)
- 10. I
- 10.1. 独立同等分布 (i.i.d, independently and identically distributed)
- 10.2. 推断 (inference)
- 10.3. 输入函数 (input function)
- 10.4. 输入层 (input layer)
- 10.5. 实例 (instance)
- 10.6. 可解释性 (interpretability)
- 10.7. 评分者间一致性信度 (inter-rater agreement)
- 10.8. 迭代 (iteration)
- 11. K
- 11.1. k-means
- 11.2. k-median
- 11.3. Keras
- 11.4. 核支持向量机 (KSVM, Kernel Support Vector Machines)
1. 背景
Google出了一份机器学习术语表,列出了一般的机器学习术语和 TensorFlow 专用术语的定义,并且翻译成了中文,对理解机器学习中的术语很有帮助,于是我把它转载过来,方便学习和记录,这一篇是首字母D-K的内容。
原文链接:https://developers.google.cn/machine-learning/glossary/?hl=zh-CN
5. D
5.1. 数据分析 (data analysis)
根据样本、测量结果和可视化内容来理解数据。数据分析在首次收到数据集、构建第一个模型之前特别有用。此外,数据分析在理解实验和调试系统问题方面也至关重要。
5.2. DataFrame
一种热门的数据类型,用于表示 Pandas 中的数据集。DataFrame 类似于表格。DataFrame 的每一列都有一个名称(标题),每一行都由一个数字标识。
5.3. 数据集 (data set)
一组样本的集合。
5.4. Dataset API (tf.data)
一种高级别的 TensorFlow API,用于读取数据并将其转换为机器学习算法所需的格式。tf.data.Dataset 对象表示一系列元素,其中每个元素都包含一个或多个张量。tf.data.Iterator 对象可获取 Dataset 中的元素。
如需详细了解 Dataset API,请参阅《TensorFlow 编程人员指南》中的导入数据。
5.5. 决策边界 (decision boundary)
在二元分类或多类别分类问题中,模型学到的类别之间的分界线。例如,在以下表示某个二元分类问题的图片中,决策边界是橙色类别和蓝色类别之间的分界线:

5.6. 密集层 (dense layer)
与全连接层的含义相同。
5.7. 深度模型 (deep model)
一种神经网络,其中包含多个隐藏层。深度模型依赖于可训练的非线性关系。
与宽度模型相对。
5.8. 密集特征 (dense feature)
一种大部分值是非零值的特征,通常是浮点值张量。与稀疏特征相对。
5.9. 设备 (device)
一类可运行 TensorFlow 会话的硬件,包括 CPU、GPU 和 TPU。
5.10. 离散特征 (discrete feature)
一种特征,包含有限个可能值。例如,某个值只能是"动物"、"蔬菜"或"矿物"的特征便是一个离散特征(或分类特征)。与连续特征相对。
5.11. 丢弃正则化 (dropout regularization)
正则化的一种形式,在训练神经网络方面非常有用。丢弃正则化的运作机制是,在一个梯度步长中移除从神经网络层中随机选择的固定数量的单元。丢弃的单元越多,正则化效果就越强。这类似于训练神经网络以模拟较小网络的指数级规模集成学习。如需完整的详细信息,请参阅 Dropout: A Simple Way to Prevent Neural Networks from Overfitting(《丢弃:一种防止神经网络过拟合的简单方法》)。
5.12. 动态模型 (dynamic model)
一种模型,以持续更新的方式在线接受训练。也就是说,数据会源源不断地进入这种模型。
6. E
6.1. 早停法 (early stopping)
一种正则化方法,是指在训练损失仍可以继续降低之前结束模型训练。使用早停法时,您会在验证数据集的损失开始增大(也就是泛化效果变差)时结束模型训练。
6.2. 嵌套 (embeddings)
一种分类特征,以连续值特征表示。通常,嵌套是指将高维度向量映射到低维度的空间。例如,您可以采用以下两种方式之一来表示英文句子中的单词:
- 表示成包含百万个元素(高维度)的稀疏向量,其中所有元素都是整数。向量中的每个单元格都表示一个单独的英文单词,单元格中的值表示相应单词在句子中出现的次数。由于单个英文句子包含的单词不太可能超过 50 个,因此向量中几乎每个单元格都包含 0。少数非 0 的单元格中将包含一个非常小的整数(通常为 1),该整数表示相应单词在句子中出现的次数。
- 表示成包含数百个元素(低维度)的密集向量,其中每个元素都存储一个介于 0 到 1 之间的浮点值。这就是一种嵌套。
在 TensorFlow 中,会按反向传播损失训练嵌套,和训练神经网络中的任何其他参数一样。
6.3. 经验风险最小化 (ERM, empirical risk minimization)
用于选择可以将基于训练集的损失降至最低的函数。与结构风险最小化相对。
6.4. 集成学习 (ensemble)
多个模型的预测结果的并集。您可以通过以下一项或多项来创建集成学习:
- 不同的初始化
- 不同的超参数
- 不同的整体结构
深度模型和宽度模型属于一种集成学习。
6.5. 周期 (epoch)
在训练时,整个数据集的一次完整遍历,以便不漏掉任何一个样本。因此,一个周期表示(N/批次大小)次训练迭代,其中 N 是样本总数。
6.6. Estimator
tf.Estimator 类的一个实例,用于封装负责构建 TensorFlow 图并运行 TensorFlow 会话的逻辑。您可以创建自定义 Estimator(如需相关介绍,请点击此处),也可以实例化其他人预创建的 Estimator。
6.7. 样本 (example)
数据集的一行。一个样本包含一个或多个特征,此外还可能包含一个标签。另请参阅有标签样本和无标签样本。
7. F
7.1. 假负例 (FN, false negative)
被模型错误地预测为负类别的样本。例如,模型推断出某封电子邮件不是垃圾邮件(负类别),但该电子邮件其实是垃圾邮件。
7.2. 假正例 (FP, false positive)
被模型错误地预测为正类别的样本。例如,模型推断出某封电子邮件是垃圾邮件(正类别),但该电子邮件其实不是垃圾邮件。
7.3. 假正例率(false positive rate, 简称 FP 率)
ROC 曲线中的 x 轴。FP 率的定义如下:
假正例率 = 假正例数 假正例数 + 负例数 \text{假正例率} = \frac{\text{假正例数}}{\text{假正例数 + 负例数}} 假正例率=假正例数 + 负例数假正例数
7.4. 特征 (feature)
在进行预测时使用的输入变量。
7.5. 特征列 (tf.feature_column)
指定模型应该如何解读特定特征的一种函数。此类函数的输出结果是所有 Estimators 构造函数的必需参数。
借助 tf.feature_column 函数,模型可对输入特征的不同表示法轻松进行实验。有关详情,请参阅《TensorFlow 编程人员指南》中的特征列一章。
“特征列"是 Google 专用的术语。特征列在 Yahoo/Microsoft 使用的 VW 系统中称为"命名空间”,也称为场。
7.6. 特征组合 (feature cross)
通过将单独的特征进行组合(求笛卡尔积)而形成的合成特征。特征组合有助于表达非线性关系。
7.7. 特征工程 (feature engineering)
指以下过程:确定哪些特征可能在训练模型方面非常有用,然后将日志文件及其他来源的原始数据转换为所需的特征。在 TensorFlow 中,特征工程通常是指将原始日志文件条目转换为 tf.Example 协议缓冲区。另请参阅 tf.Transform。
特征工程有时称为特征提取。
7.8. 特征集 (feature set)
训练机器学习模型时采用的一组特征。例如,对于某个用于预测房价的模型,邮政编码、房屋面积以及房屋状况可以组成一个简单的特征集。
7.9. 特征规范 (feature spec)
用于描述如何从 tf.Example 协议缓冲区提取特征数据。由于 tf.Example 协议缓冲区只是一个数据容器,因此您必须指定以下内容:
- 要提取的数据(即特征的键)
- 数据类型(例如 float 或 int)
- 长度(固定或可变)
Estimator API 提供了一些可用来根据给定 FeatureColumns 列表生成特征规范的工具。
7.10. 少量样本学习 (few-shot learning)
一种机器学习方法(通常用于对象分类),旨在仅通过少量训练样本学习有效的分类器。
另请参阅单样本学习。
7.11. 完整 softmax (full softmax)
请参阅 softmax。与候选采样相对。
7.12. 全连接层 (fully connected layer)
一种隐藏层,其中的每个节点均与下一个隐藏层中的每个节点相连。
全连接层又称为密集层。
8. G
8.1. 泛化 (generalization)
指的是模型依据训练时采用的数据,针对以前未见过的新数据做出正确预测的能力。
8.2. 广义线性模型 (generalized linear model)
最小二乘回归模型(基于高斯噪声)向其他类型的模型(基于其他类型的噪声,例如泊松噪声或分类噪声)进行的一种泛化。广义线性模型的示例包括:
- 逻辑回归
- 多类别回归
- 最小二乘回归
可以通过凸优化找到广义线性模型的参数。
广义线性模型具有以下特性:
- 最优的最小二乘回归模型的平均预测结果等于训练数据的平均标签。
- 最优的逻辑回归模型预测的平均概率等于训练数据的平均标签。
广义线性模型的功能受其特征的限制。与深度模型不同,广义线性模型无法"学习新特征"。
8.3. 梯度 (gradient)
偏导数相对于所有自变量的向量。在机器学习中,梯度是模型函数偏导数的向量。梯度指向最高速上升的方向。
8.4. 梯度裁剪 (gradient clipping)
在应用梯度值之前先设置其上限。梯度裁剪有助于确保数值稳定性以及防止梯度爆炸。
8.5. 梯度下降法 (gradient descent)
一种通过计算并且减小梯度将损失降至最低的技术,它以训练数据为条件,来计算损失相对于模型参数的梯度。通俗来说,梯度下降法以迭代方式调整参数,逐渐找到权重和偏差的最佳组合,从而将损失降至最低。
8.6. 图 (graph)
TensorFlow 中的一种计算规范。图中的节点表示操作。边缘具有方向,表示将某项操作的结果(一个张量)作为一个操作数传递给另一项操作。可以使用 TensorBoard 直观呈现图。
9. H
9.1. 启发法 (heuristic)
一种非最优但实用的问题解决方案,足以用于进行改进或从中学习。
9.2. 隐藏层 (hidden layer)
神经网络中的合成层,介于输入层(即特征)和输出层(即预测)之间。神经网络包含一个或多个隐藏层。
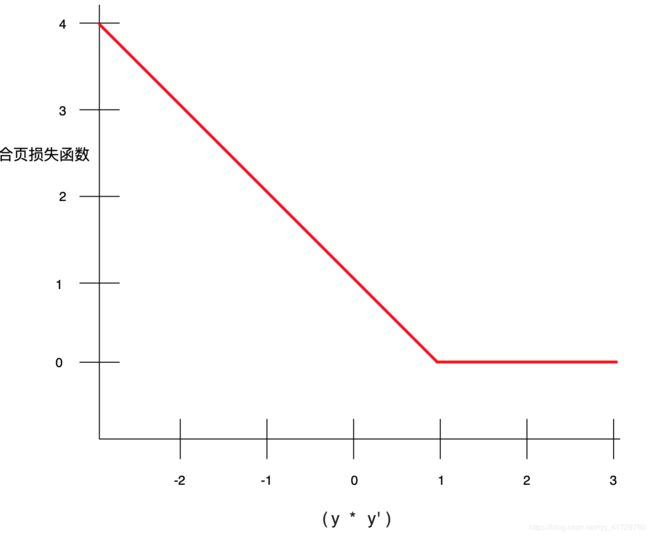
9.3. 合页损失函数 (hinge loss)
一系列用于分类的损失函数,旨在找到距离每个训练样本都尽可能远的决策边界,从而使样本和边界之间的裕度最大化。KSVM 使用合页损失函数(或相关函数,例如平方合页损失函数)。对于二元分类,合页损失函数的定义如下:
l o s s = max ( 0 , 1 − ( y ′ ∗ y ) ) loss = \max{(0, 1 - (y' * y))} loss=max(0,1−(y′∗y))
其中"y’"表示分类器模型的原始输出:
y ′ = b + w 1 x 1 + w 2 x 2 + ⋯ + w n x n y' = b + w_1 x_1 + w_2 x_2 + \dots + w_n x_n y′=b+w1x1+w2x2+⋯+wnxn
"y"表示真标签,值为 -1 或 +1。
因此,合页损失与 (y * y’) 的关系图如下所示:
9.4. 维持数据 (holdout data)
训练期间故意不使用(“维持”)的样本。验证数据集和测试数据集都属于维持数据。维持数据有助于评估模型向训练时所用数据之外的数据进行泛化的能力。与基于训练数据集的损失相比,基于维持数据集的损失有助于更好地估算基于未见过的数据集的损失。
9.5. 超参数 (hyperparameter)
在模型训练的连续过程中,您调节的"旋钮"。例如,学习速率就是一种超参数。
与参数相对。
9.6. 超平面 (hyperplane)
将一个空间划分为两个子空间的边界。例如,在二维空间中,直线就是一个超平面,在三维空间中,平面则是一个超平面。在机器学习中更典型的是:超平面是分隔高维度空间的边界。核支持向量机利用超平面将正类别和负类别区分开来(通常是在极高维度空间中)。
10. I
10.1. 独立同等分布 (i.i.d, independently and identically distributed)
从不会改变的分布中提取的数据,其中提取的每个值都不依赖于之前提取的值。i.i.d. 是机器学习的理想气体 - 一种实用的数学结构,但在现实世界中几乎从未发现过。例如,某个网页的访问者在短时间内的分布可能为 i.i.d.,即分布在该短时间内没有变化,且一位用户的访问行为通常与另一位用户的访问行为无关。不过,如果将时间窗口扩大,网页访问者的分布可能呈现出季节性变化。
10.2. 推断 (inference)
在机器学习中,推断通常指以下过程:通过将训练过的模型应用于无标签样本来做出预测。在统计学中,推断是指在某些观测数据条件下拟合分布参数的过程。(请参阅维基百科中有关统计学推断的文章。)
10.3. 输入函数 (input function)
在 TensorFlow 中,用于将输入数据返回到 Estimator 的训练、评估或预测方法的函数。例如,训练输入函数会返回训练集中的一批特征和标签。
10.4. 输入层 (input layer)
神经网络中的第一层(接收输入数据的层)。
10.5. 实例 (instance)
与样本的含义相同。
10.6. 可解释性 (interpretability)
模型的预测可解释的难易程度。深度模型通常不可解释,也就是说,很难对深度模型的不同层进行解释。相比之下,线性回归模型和宽度模型的可解释性通常要好得多。
10.7. 评分者间一致性信度 (inter-rater agreement)
一种衡量指标,用于衡量在执行某项任务时评分者达成一致的频率。如果评分者未达成一致,则可能需要改进任务说明。有时也称为注释者间一致性信度或评分者间可靠性信度。另请参阅 Cohen’s kappa(最热门的评分者间一致性信度衡量指标之一)。
10.8. 迭代 (iteration)
模型的权重在训练期间的一次更新。迭代包含计算参数在单批次数据上的梯度损失。
11. K
11.1. k-means
一种热门的聚类算法,用于对非监督式学习中的样本进行分组。k-means 算法基本上会执行以下操作:
- 以迭代方式确定最佳的 k 中心点(称为形心)。
- 将每个样本分配到最近的形心。与同一个形心距离最近的样本属于同一个组。
k-means 算法会挑选形心位置,以最大限度地减小每个样本与其最接近形心之间的距离的累积平方。
以下面的小狗高度与小狗宽度的关系图为例:
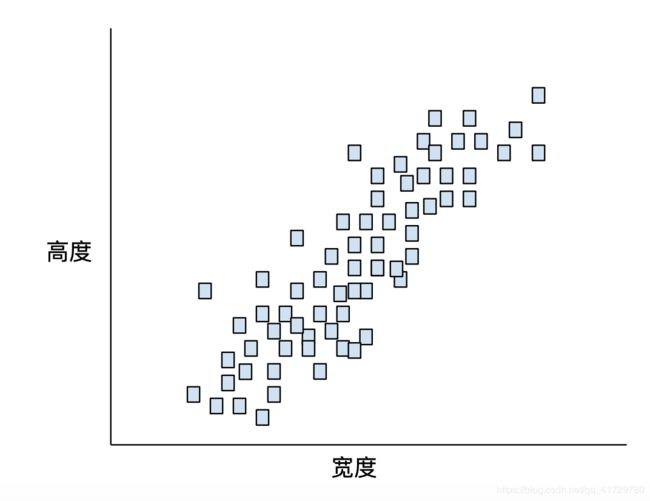
如果 k=3,则 k-means 算法会确定三个形心。每个样本都被分配到与其最接近的形心,最终产生三个组:
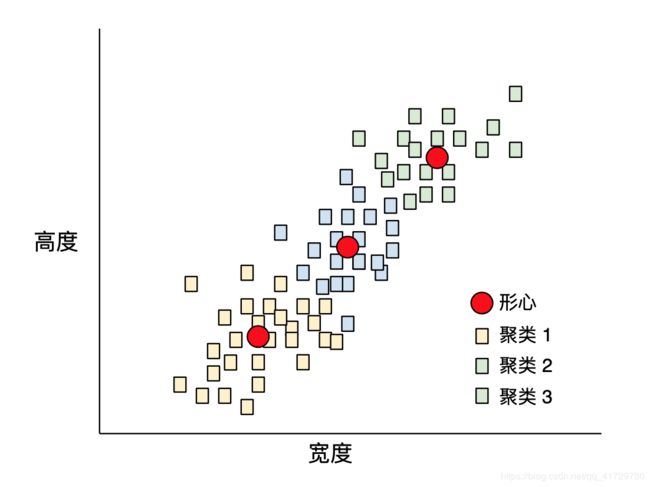
假设制造商想要确定小、中和大号狗毛衣的理想尺寸。在该聚类中,三个形心用于标识每只狗的平均高度和平均宽度。因此,制造商可能应该根据这三个形心确定毛衣尺寸。请注意,聚类的形心通常不是聚类中的样本。
上图显示了 k-means 应用于仅具有两个特征(高度和宽度)的样本。请注意,k-means 可以跨多个特征为样本分组。
11.2. k-median
与 k-means 紧密相关的聚类算法。两者的实际区别如下:
- 对于 k-means,确定形心的方法是,最大限度地减小候选形心与它的每个样本之间的距离平方和。
- 对于 k-median,确定形心的方法是,最大限度地减小候选形心与它的每个样本之间的距离总和。
请注意,距离的定义也有所不同:
- k-means 采用从形心到样本的欧几里得距离。(在二维空间中,欧几里得距离即使用勾股定理来计算斜边。)例如,(2,2) 与 (5,-2) 之间的 k-means 距离为:
欧几里德距离 = ( 2 − 5 ) 2 + ( 2 − ( − 2 ) ) 2 = 5 \text{欧几里德距离} = \sqrt[]{(2 - 5)^2 + (2 - (-2))^2} = 5 欧几里德距离=(2−5)2+(2−(−2))2=5
- k-median 采用从形心到样本的曼哈顿距离。这个距离是每个维度中绝对差异值的总和。例如,(2,2) 与 (5,-2) 之间的 k-median 距离为:
曼哈顿距离 = ∣ 2 − 5 ∣ + ∣ 2 − ( − 2 ) ∣ = 7 \text{曼哈顿距离} = |2 - 5| + |2 - (-2)| = 7 曼哈顿距离=∣2−5∣+∣2−(−2)∣=7
11.3. Keras
一种热门的 Python 机器学习 API。Keras 能够在多种深度学习框架上运行,其中包括 TensorFlow(在该框架上,Keras 作为 tf.keras 提供)。
11.4. 核支持向量机 (KSVM, Kernel Support Vector Machines)
一种分类算法,旨在通过将输入数据向量映射到更高维度的空间,来最大化正类别和负类别之间的裕度。以某个输入数据集包含一百个特征的分类问题为例。为了最大化正类别和负类别之间的裕度,KSVM 可以在内部将这些特征映射到百万维度的空间。KSVM 使用合页损失函数。
联系邮箱:[email protected]
CSDN:https://me.csdn.net/qq_41729780
知乎:https://zhuanlan.zhihu.com/c_1225417532351741952
公众号:复杂网络与机器学习
欢迎关注/转载,有问题欢迎通过邮箱交流。
