结巴分词简要理解
Python中分分词工具很多,包括盘古分词、Yaha分词、Jieba分词、清华THULAC等。它们的基本用法都大同小异,这里先了解一下结巴分词。
一、安装
pip install jieba
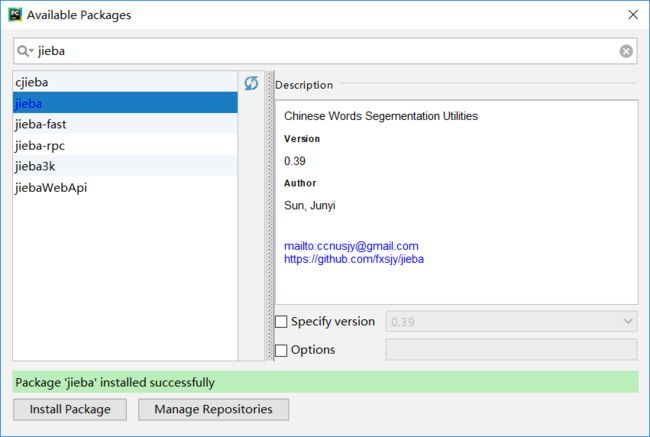
若使用PyCharm,从左上角的File–>Setting–>Project:工程名–>Project Interpreter,点击右侧的“+”,在弹出界面的搜索栏中输入“jieba”,Install Package
二、算法介绍 结巴中文分词涉及到的算法包括:
(1) 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);
(2) 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
(3) 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
三、分词模式 结巴中文分词支持的三种分词模式包括:
(1) 精确模式:试图将句子最精确地切开,适合文本分析;
(2) 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义问题;
(3) 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
import jieba
# 全模式
text = "我来到北京清华大学"
seg_list = jieba.cut(text, cut_all=True)
print(u"[全模式]: ", "/ ".join(seg_list))
# 精确模式
seg_list = jieba.cut(text, cut_all=False)
print(u"[精确模式]: ", "/ ".join(seg_list))
# 默认是精确模式
seg_list = jieba.cut(text)
print(u"[默认模式]: ", "/ ".join(seg_list))
# 搜索引擎模式
seg_list = jieba.cut_for_search(text)
print(u"[搜索引擎模式]: ", "/ ".join(seg_list))
运行结果:
[全模式]: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
[精确模式]: 我/ 来到/ 北京/ 清华大学
[默认模式]: 我/ 来到/ 北京/ 清华大学
[搜索引擎模式]: 我/ 来到/ 北京/ 清华/ 华大/ 大学/ 清华大学
四、新词识别
import jieba
#新词识别 “杭研”并没有在词典中,但是也被Viterbi算法识别出来了
seg_list = jieba.cut("他来到了网易杭研大厦")
print (u"[新词识别]: ", "/ ".join(seg_list))
运行结果:
[新词识别]: 他/ 来到/ 了/ 网易/ 杭研/ 大厦
五、自定义词典
先看一个例子:
import jieba
text = "故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等"
# 全模式
seg_list = jieba.cut(text, cut_all=True)
print(u"[全模式]: ", "/ ".join(seg_list))
# 精确模式
seg_list = jieba.cut(text, cut_all=False)
print(u"[精确模式]: ", "/ ".join(seg_list))
# 搜索引擎模式
seg_list = jieba.cut_for_search(text)
print(u"[搜索引擎模式]: ", "/ ".join(seg_list))
运行结果:
[全模式]: 故宫/ 的/ 著名/ 著名景点/ 景点/ 包括/ 乾/ 清宫/ / / 太和/ 太和殿/ 和/ 黄/ 琉璃/ 琉璃瓦/ 等
[精确模式]: 故宫/ 的/ 著名景点/ 包括/ 乾/ 清宫/ 、/ 太和殿/ 和/ 黄/ 琉璃瓦/ 等
[搜索引擎模式]: 故宫/ 的/ 著名/ 景点/ 著名景点/ 包括/ 乾/ 清宫/ 、/ 太和/ 太和殿/ 和/ 黄/ 琉璃/ 琉璃瓦/ 等
可以看到,结巴分词工具认出了专有名词”太和殿”,但没有认出”乾清宫”和”黄琉璃瓦”。 也就是说,专有名词”乾清宫”和”黄琉璃瓦”可能因分词而分开,这也是很多分词工具的一个缺陷。 为此,Jieba分词支持开发者使用自定定义的词典,以便包含jieba词库里没有的词语。虽然结巴有新词识别能力,但自行添加新词可以保证更高的正确率,尤其是专有名词。
基本用法:
jieba.load_userdict(file_name) #file_name为自定义词典的路径词典格式和dict.txt一样,一个词占一行; 每一行分三部分,第一部分为词语,中间部分为词频,最后部分为词性(可省略,ns为地点名词),用空格隔开。 咱们在jieba的安装目录下添加mydict.txt,内容为
乾清宫 1 n
黄琉璃瓦 1 n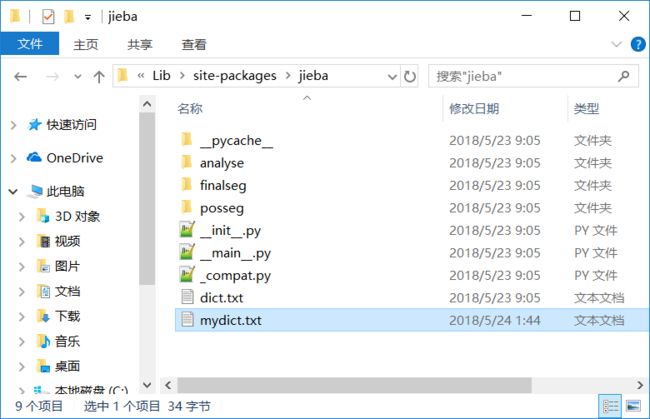
更新代码,主要是添加加载mydict.txt的代码:
import jieba
jieba.load_userdict("D:\Program Files\Python36\Lib\site-packages\jieba\mydict.txt")
text = "故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等"
# 全模式
seg_list = jieba.cut(text, cut_all=True)
print(u"[全模式]: ", "/ ".join(seg_list))
# 精确模式
seg_list = jieba.cut(text, cut_all=False)
print(u"[精确模式]: ", "/ ".join(seg_list))
# 搜索引擎模式
seg_list = jieba.cut_for_search(text)
print(u"[搜索引擎模式]: ", "/ ".join(seg_list))运行结果:
[全模式]: 故宫/ 的/ 著名/ 著名景点/ 景点/ 包括/ 乾清宫/ 清宫/ / / 太和/ 太和殿/ 和/ 黄琉璃瓦/ 琉璃/ 琉璃瓦/ 等
[精确模式]: 故宫/ 的/ 著名景点/ 包括/ 乾清宫/ 、/ 太和殿/ 和/ 黄琉璃瓦/ 等
[搜索引擎模式]: 故宫/ 的/ 著名/ 景点/ 著名景点/ 包括/ 清宫/ 乾清宫/ 、/ 太和/ 太和殿/ 和/ 琉璃/ 琉璃瓦/ 黄琉璃瓦/ 等
可以看到,新添加的两个专有名词已经被结巴分词工具辨别出来了。
六、关键词提取 在构建VSM向量空间模型过程或者把文本转换成数学形式计算中,你需要运用到关键词提取的技术。
基本方法:
jieba.analyse.extract_tags(sentence, topK) 其中sentence为待提取的文本,topK为返回几个TF/IDF权重最大的关键词,默认值为20。
程序:
import jieba
import jieba.analyse
#导入自定义词典
jieba.load_userdict("D:\Program Files\Python36\Lib\site-packages\jieba\mydict.txt")
#精确模式
text = "故宫的著名景点包括乾清宫、太和殿和午门等。其中乾清宫非常精美,午门是紫禁城的正门,午门居中向阳。"
seg_list = jieba.cut(text, cut_all=False)
print (u"分词结果:")
print ("/".join(seg_list))
#获取关键词
tags = jieba.analyse.extract_tags(text, topK=5)
print (u"关键词:")
print (" ".join(tags))运行结果:
故宫/的/著名景点/包括/乾清宫/、/太和殿/和/午门/等/。/其中/乾清宫/非常/精美/,/午门/是/紫禁城/的/正门/,/午门/居中/向阳/。
关键词:
午门 乾清宫 著名景点 太和殿 向阳
这里“午门”出现了3次,所以先输出。“乾清宫”出现了2次,第二个输出。
其他词都出现1次,那么为什么接下来输出的是“著名景点”、“太和殿”和“向阳”呢? 这是因为,在词频一样的前题下,根据TF/IDF的顺序来输出,因为其他词的TF一样(都是1),所以IDF小的会先输出来。
不知道结巴分词是根据什么来判断IDF的,假如是根据dict.txt中的第二列词频来判断,那么确实是“著名景点” < “太阳殿” < “向阳” < 其他词语。这样第三个输出的就是“著名景点”,最后两个依次为“太阳殿”和“向阳”。
七、去除停用词
import jieba
# 去除停用词
stopwords = {}.fromkeys(['的', '包括', '等', '是'])
text = "故宫的著名景点包括乾清宫、太和殿和午门等。其中乾清宫非常精美,午门是紫禁城的正门。"
# 精确模式
segs = jieba.cut(text, cut_all=False)
final = ''
for seg in segs:
if seg not in stopwords:
final += seg
print (final)
seg_list = jieba.cut(final, cut_all=False)
print ("/ ".join(seg_list))
在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,比如“的”、“是”、“而且”、“但是”、”非常“等。这些字或词即被称为Stop Words(停用词)。
故宫著名景点乾清宫、太和殿和午门。其中乾清宫非常精美,午门紫禁城正门。
故宫/ 著名景点/ 乾/ 清宫/ 、/ 太和殿/ 和/ 午门/ 。/ 其中/ 乾/ 清宫/ 非常/ 精美/ ,/ 午门/ 紫禁城/ 正门/ 。