注:一篇去年的旧文,发现没在知乎发过,过来补个档。有个小问题是项目中淘票票的网页反爬提升且变动较多,目前暂不可用了。
时常有同学会问我类似的问题:我已经学完了 Python 基础,也照着例子写过一点爬虫代码 / 了解过 django 的入门项目 / 看过数据分析的教程……然后就不知道要做什么了。接下来应该 如何继续提升编程能力呢 ?
我的答案很简单:
做项目
不要把“项目”想象得太复杂,觉得一定是那种收钱开发的才能称作项目(如果有这种项目当然会更好)。对于刚刚跨入编程世界的你来说,任何一个小项目都是好的开始。你所需要的,就是 一双发现问题的眼睛 。生活中工作中的一些小事情小麻烦,多想一步,是不是可以写一小段代码来解决。
一开始,或许你的解决方案很笨拙,很复杂,本来5分钟就能搞定的事情,你写代码却花了一个小时。但对你来说,此时的目的并不只是解决问题,而是这个过程本身。 在折腾的过程中,你的经验才会增长 。这是你单纯看教程所无法达到的,再好的教程也替代不了动手。(有时候会有人评论说,这功能直接用xxx就可以了,干嘛还要自己写代码。对此我不做评价,因为我知道他不是来学编程的。)
我们编程教室也陆续提供了一些项目案例。你可以参考我们的示例代码,或者更好的是,自己去思考一个解决方案并实现。我们的案例不少都放在了网站 http:// lab.crossincode.com 上演示,欢迎大家去浏览。内容会持续更新,可留意我们微信公众号和知乎专栏里的文章。
今天介绍的这个项目就源自生活中的一个场景: 买电影票 。
当你打算周末出门看场电影的时候,就必然面临三个终极问题:
- 看什么?
- 什么时候看?
- 去哪儿看?
通常你只需要打开常用的购票App,选一部最近口碑不错的片子,去熟悉的影院看看有哪些场次就可以了。但有时你也会发现,同样一部电影,不远的两家影院,价格就差很多,不同的购票App也会因为促销活动之类有不同的优惠力度,一张票可能会相差几十元。但如果每次都去几个App把最近的排片和价格都浏览一遍,那也太麻烦了。于是就有了我们这个小项目:
电影票比价网
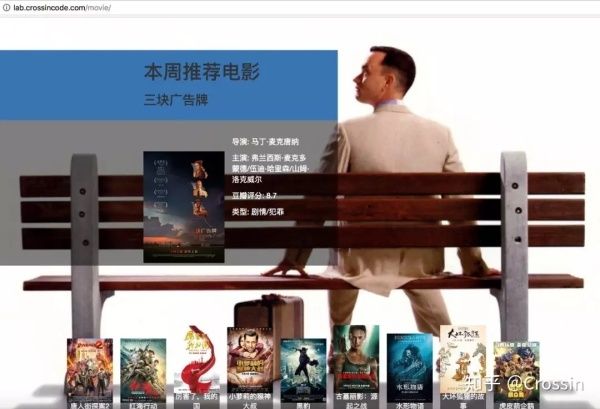
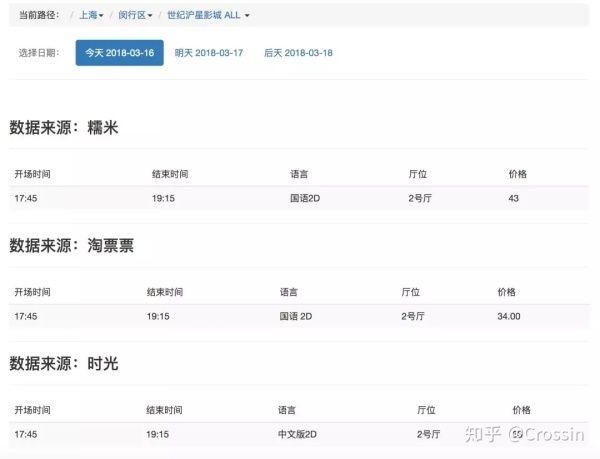
在我们这个网页上,会展示出当前热映的电影。进入每部电影,选择 城市 、 区域 、 影院 和 日期 ,就可以看到最近的 排片时间 和不同渠道的 价格 。目前,我们是从 糯米 、 淘票票 和 时光网 三个渠道获取价格来做演示。(注:项目中淘票票现已失效)
实现技术
本项目是对爬虫和Web网站的综合运用,适合已经有掌握python基础,并且对此有一些了解的同学作为练手项目。涉及到模块主要是:
- Django(1.10)
- requests
- bs4
- python-Levenshtein(用来匹配不同渠道的影院信息)
代码结构
项目主要有三块:
- douban_movie
使用豆瓣 api 每日更新上映的影片列表。
- movie_tickets
项目的核心部分,用来处理影院信息和排名信息的抓取。
- django
项目本身是一个网站,整体是在 django 的框架之中。
开发思路
- 使用爬虫爬取各电影票网站所有的电影院链接,作为基本的数据保存下来
- 使用豆瓣 API 获取当日上映的电影信息,并每天更新
- django 显示电影信息,提供给用户选择电影院的接口
- 将影片和影院信息发送到 django 后台进行查询,爬取对应的排片信息显示给用户
代码片段
# 获取淘票票某地区某电影院某影片价格#
1. 根据查询条件获取影院 id#
2. 根据影院 id 获取该影院正在上映电影#
3. 获取 查询电影的排片时间表链接#
4. 拿到价格
def get_movie_tickets(self, *args):
assert len(args) == 4, 'not enough parameters \n type in -h for help'
movie_name = args[3]
mt = TaoppDt()
cinema_url = mt.search(*args[:3])
assert cinema_url, '未查询到该电影院'
pattern = re.compile(r'cinemaId=(\d+)')
cinemaid = re.findall(pattern, cinema_url)[0]
film_url = 'https://dianying.taobao.com/cinemaDetailSchedule.htm?cinemaId=' + str(cinemaid)
content = self.rq.req_url(film_url)
assert content, '请求失败,请检查 /utils/req.py 中 req_url 函数是否工作正常'
soup = bs4.BeautifulSoup(content, 'lxml')
soup_film = soup.find('a', text=re.compile(movie_name))
assert soup_film, '未查询到该电影'
film_param = soup_film['data-param']
return self._get_ticket_info(film_param)
其他说明
- 项目为了有一个较好的交互效果,在页面上用到了不少 Ajax 请求。这需要有一定的前端 js 基础。对网页前端不熟悉的同学可暂且略过,重点关注后端实现。
- 不同渠道对于同一家影院的名称很可能有出入,因此这里使用了 python-Levenshtein 来对文本进行匹配。
- 代码里在抓取时有用到我们的另一个项目: IP代理池 (参见 Crossin:听说你好不容易写了个爬虫,结果没抓几个就被封了?)。但因为服务器资源有限,有时拿不到可用的代理。各位自己电脑上运行代码时,可尝试把 requests 的 proxies 参数去除。
- 作为一个演示项目,必然存在一些bug(当然商业项目也不可能没有bug),加上爬虫的程序极有可能因为对方网站更新而失效。所以如果遇到问题,欢迎大家给我们报错。
代码下载
完整的代码 和 详细代码说明 已上传 Github,获取下载地址请在 公众号(Crossin的编程教室) 里回复 电影票 。
════
其他文章及回答:
学编程:如何自学Python | 新手引导 | 一图学Python
欢迎搜索及关注: Crossin的编程教室
