Python——支持向量机(SVM)
SVM的目的是寻找区分两类的超平面(hyper plane),使边际(margin)最大。该超平面到一侧最近点的距离等于到另一侧最近点的距离,两侧的两个超平面平行。
线性可区分(linear separable):映射到直角平面坐标系就是可以直接用直线将其区分
线性不可区分(linear inseparable):映射到直角平面坐标系就是不可以直接用直线将其区分
定义与公式建立:
![]()
W:weight vectot
n是特征值的个数
反应在二维平面,其方程可写为:
则平面上方的样本满足:
![]()
则平面下方的样本满足:
![]()
调整weight,使超平面定义边际的两边:
![]() for
for ![]()
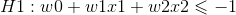 for
for ![]()
即对二分类,定义超平面上方的样本标签都为+1,超平面下方的样本标签都为-1。
由两式可得:
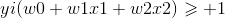 ,对所有i都成立 (1)
,对所有i都成立 (1)
所有的坐落在两边的边际超平面上的点被称为支持向量(support vectors)
两边任意超平面上的点到中间超平面的距离为:
 其中:
其中: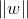 是向量的范数
是向量的范数
if ![]() than
than 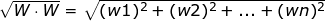
所以最大边际距离为:
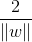
如何求超平面(MMH)?
1、公式(1)可以变为有限制的凸规划问题
2、利用KKT条件和拉格朗日公式,可以推出MMK可以被表示为以下决定边界:
![]()
其中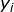 是支持向量点
是支持向量点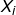 (support vector)的类别标记(class label),取+1或-1,
(support vector)的类别标记(class label),取+1或-1,![]() 是要测试的实例,
是要测试的实例,![]() 和都是单一数值型参数,
和都是单一数值型参数,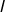 是支持向量的个数。
是支持向量的个数。
3、对于任何测试实例,带入以上公式,得出的符号是正负来决定其类别
代码实现1:
from sklearn import svm
x = [[2,0], [1,1], [2,3]] #数据
y = [0, 0, 1]
clf = svm.SVC(kernel= 'linear') #核函数
clf.fit(x,y) #用训练数据拟合分类器模型
print(clf) #打印超平面的参数
print(clf.support_vectors_) #打印分类器的支持向量点
print(clf.support_) #打印分类器的支持向量点的索引
print(clf.n_support_) #打印出有多少个点属于支持向量的
print(clf.predict([[2,0]])) #预测[2,0]的类别代码实现2:
import numpy as np
import pylab as pl #画图
from sklearn import svm
np.random.seed(0)
#随机产生点,20行2列,均值和方差都是2
X = np.r_[np.random.randn(20,2)-[2,2], np.random.randn(20,2)+[2,2]]
Y = [0]*20 + [1]*20 #共有40列,1行
# print(Y)
clf = svm.SVC(kernel='linear')
clf.fit(X,Y)
w = clf.coef_[0] #截距
a = -w[0]/w[1] #斜率
xx=np.linspace(-5,5) #范围
yy = a * xx - (clf.intercept_[0]/w[1]) #直线
b = clf.support_vectors_[0]
yy_down = a * xx + (b[1] - a * b[0]) #下边界
b = clf.support_vectors_[-1]
yy_up = a * xx + (b[1] - a * b[0]) #下边界
print('w:',w)
print('a:',a)
print('support_vectors_:',clf.support_vectors_)
print('clf.coef_:',clf.coef_)
pl.plot(xx,yy,'k-')
pl.plot(xx,yy_down,'k--')
pl.plot(xx,yy_up,'k-')
pl.scatter(clf.support_vectors_[:,0], clf.support_vectors_[:,1],
s = 50, facecolors = 'none')
pl.scatter(X[:,0], X[:,1],c = Y,cmap= pl.cm.Paired)
pl.axis('tight')
pl.show()SVM的优点:
1、算法的复杂度是由支持向量的个数决定的,所以SVM不太容易产生overfiting
2、SVM模型完全依赖于支持向量,即使训练集里面所有非支持向量的点都被去除,重复训练过程,结果依然会得到完全一样的模型
3、若SVM的支持向量个数比较少,则该模型的泛化能力比较好
线性不可分:数据在空间中对应的向量不可以被一个超平面分开
解决步骤:
1、利用一个非线性映射,把原数据集中的向量点转化到一个更高维度的空间中
2、在该高维度的空间中找一个线性的超平面,来根据线性可分的情况处理
如何讲一个低维空间映射到一个高维空间:
例如: ![]() ,将其转化到6维空间:
,将其转化到6维空间:
可以定义:![]()
![]()
![]()
![]()
![]()
则新的超平面:![]() 其中W和Z是向量,这个超平面是线性的,解出W和b之后带入原方程:
其中W和Z是向量,这个超平面是线性的,解出W和b之后带入原方程:
![]()
![]()
问题1:如何选取合理的非线性转化将数据转到高维
问题2:如何解决转化维度过程中内积时算法复杂度高的问题 答案:核方法
常用的核函数:h度多项式核函数,高斯径向基核函数(图像分类)、S型核函数
下面结合PCA降维方法用SVM进行人脸识别:
from __future__ import print_function
from time import time
import logging
import matplotlib.pyplot as plt
# from sklearn.cross_validation import train_test_split
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_lfw_people
# from sklearn.grid_search import GridSearchCV
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
# from sklearn.decomposition import RandomizedPCA
from sklearn.decomposition import PCA as RandomizedPCA
from sklearn.svm import SVC
print(__doc__)
# 打印程序进展信息
logging.basicConfig(level=logging.INFO, format='%(asctime)s %(message)s')
###############################################################################
# Download the data, if not already on disk and load it as numpy arrays
#下载人脸数据集
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
# introspect the images arrays to find the shapes (for plotting)
n_samples, h, w = lfw_people.images.shape #n_samples样本数量
# for machine learning we use the 2 data directly (as relative pixel
# positions info is ignored by this model)
X = lfw_people.data
n_features = X.shape[1] #返回特征维度
# the label to predict is the id of the person
y = lfw_people.target #返回class_label
# print('y', y)
target_names = lfw_people.target_names #返回类别的名字
n_classes = target_names.shape[0] #数据集一共多少个人
print("Total dataset size:")
print("n_samples: %d" % n_samples)
print("n_features: %d" % n_features)
print("n_classes: %d" % n_classes)
###############################################################################
# Split into a training set and a test set using a stratified k fold
# split into a training and testing set
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25)
###############################################################################
# Compute a PCA (eigenfaces) on the face dataset (treated as unlabeled
# dataset): unsupervised feature extraction / dimensionality reduction
n_components = 150 #PCA中组成元素的多少
print("Extracting the top %d eigenfaces from %d faces"
% (n_components, X_train.shape[0]))
t0 = time()
pca = RandomizedPCA(n_components=n_components, whiten=True).fit(X_train)
print("done in %0.3fs" % (time() - t0))
eigenfaces = pca.components_.reshape((n_components, h, w)) #返回人脸照片的特征值
print("Projecting the input data on the eigenfaces orthonormal basis")
t0 = time()
#通过PCA将高维降为低维
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
print("done in %0.3fs" % (time() - t0))
###############################################################################
# Train a SVM classification model
print("Fitting the classifier to the training set")
t0 = time()
param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }
#C为错误惩罚
#遍历param_grid中所有参数组合,找出分类效果最好的一组参数
# clf = GridSearchCV(SVC(kernel='rbf', class_weight='auto'), param_grid)
clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)
clf = GridSearchCV(SVC(kernel='rbf', class_weight=None), param_grid)
clf = clf.fit(X_train_pca, y_train) #建模
print("done in %0.3fs" % (time() - t0))
print("Best estimator found by grid search:")
print(clf.best_estimator_)
###############################################################################
# Quantitative evaluation of the model quality on the test set
print("Predicting people's names on the test set")
t0 = time()
y_pred = clf.predict(X_test_pca) #模型预测
print("done in %0.3fs" % (time() - t0))
print(classification_report(y_test, y_pred, target_names=target_names))
print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
###############################################################################
# Qualitative evaluation of the predictions using matplotlib
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
"""Helper function to plot a gallery of portraits"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
# plot the result of the prediction on a portion of the test set
def title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]
true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]
return r'predicted: %s''\n''true:%s' % (pred_name, true_name)
prediction_titles = [title(y_pred, y_test, target_names, i)
for i in range(y_pred.shape[0])]
plot_gallery(X_test, prediction_titles, h, w)
# plot the gallery of the most significative eigenfaces
eigenface_titles = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w)
plt.show()
代码可以直接运行,第一遍运行会自动下载数据集,下载数据存放在:

结果如下图所示


因为布什的样本比较多,所以测试集也比较多,相对来说,精度还可以!