爬虫 - requests + xpath 爬取猫眼电影排行榜 TOP100
requests + xpath 爬取猫眼电影排行榜 TOP100
- 确定要爬取的页面
- 分析页面结构
- 信息提取
- 上码
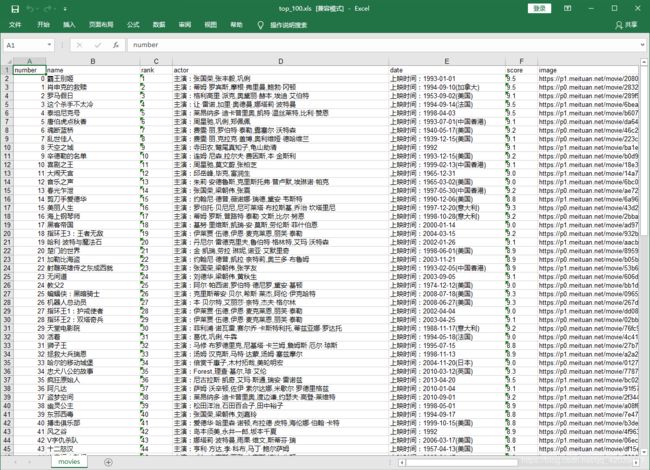
这次使用 requests + xpath 提取猫眼电影 TOP100 排行榜上的电影名称、排名、主演、上映日期、评分、图片地址等信息,同时将提取的结果以 excel 的文件形式存储到本地
猫眼电影 TOP 100 榜:https://maoyan.com/board/4
确定要爬取的页面
使用浏览器打开页面
可以发现,100 部电影是分页显示的
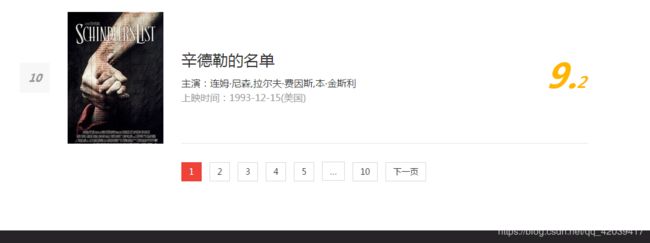
试着打开几个页面,很容易就发现了决定分页显示内容的参数
![]()
这个是第 10 页的 url,参数 offset 为 90
改变参数 offset ,可以确定所有要爬取页面的 url

分析页面结构
再使用开发者工具查看页面结构
如图所示,就是我们准备要爬取的信息所在
每一个 dd 标签存储着一部电影的信息
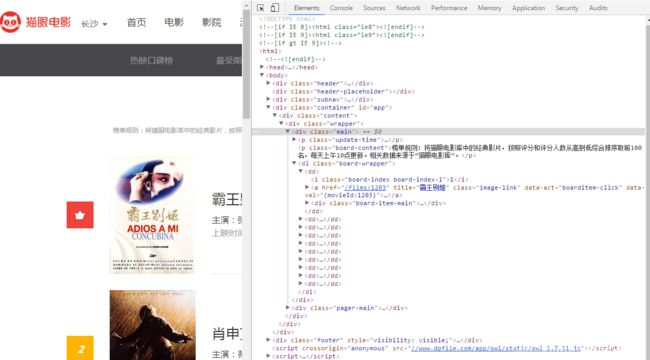
查看页面源文件,查找发现类名为 main的标签在页面文件中是唯一的
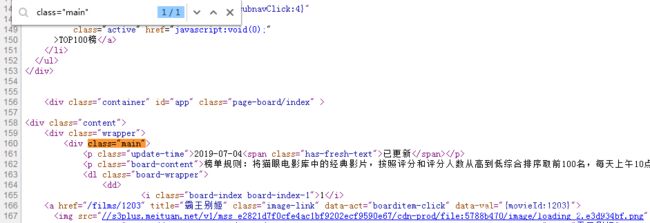
可以使用 xpath 做初步选择
![]()
单个页面有 10 部电影的信息,有 10 个 dd,所以 con 是一个大小为 10 的列表
信息提取
打开 dd 标签的所有子孙标签,圈出我们要爬取的几个关键的信息

i 标签中的文本为电影的排名
a 标签中有该电影在猫眼网站中的 url
a 标签中一个 img 子标签记录了电影图片的链接
需要注意的是,在调试工具中,这个 img 标签显示的记录链接信息的是 src 属性,但在源文件中为 data-src 属性,我们以源文件为准
中间 div 标签的几个 p 子标签分别为影片名,主演信息,上映时间
最后一个 div 标签的 p 标签包含了影片分数信息,整数部分和小数部分
上码
Python 版本: 3.7
# 爬猫眼 top 100 -- requests + xpath
import xlwt
import requests
from lxml import etree
def get_maoyan(url, sheet, i):
page_info = requests.get(url).text
sel = etree.HTML(page_info)
con = sel.xpath('//div[@class="main"]/dl/dd')
d_url = 'https://maoyan.com/'
i = i * 10 + 1
for it in con:
sheet.write(i, 0, i-1) # number
index = it.find('./i') # 查找子标签
sheet.write(i, 2, index.text) # rank
a = it.find('./a')
sheet.write(i, 7, d_url + a.get('href')) # url,加上网站的 url
img = a[1] # 下标索引子标签
sheet.write(i, 6, img.get('data-src')) # image
item = it.find('./div/div')
info = item[0]
sheet.write(i, 1, info[0][0].text) # name
sheet.write(i, 3, info[1].text.strip(' \n')) # actor,去除空格或换行
sheet.write(i, 4, info[2].text) # date
score = item[1][0]
sheet.write(i, 5, score[0].text + score[1].text) # score
i += 1
if __name__ == '__main__':
filename = 'top_100.xls'
f = xlwt.Workbook()
style = xlwt.XFStyle() # 设置字体
style.font.height = 220
sheet = f.add_sheet('movies', cell_overwrite_ok=True)
sheet.col(1).width = 6800 # 设置行宽
sheet.col(3).width = 15600
sheet.col(4).width = 8400
sheet.col(6).width = 23000
sheet.col(7).width = 8400
sheet.write(0, 0, 'number')
sheet.write(0, 1, 'name')
sheet.write(0, 2, 'rank')
sheet.write(0, 3, 'actor')
sheet.write(0, 4, 'date')
sheet.write(0, 5, 'score')
sheet.write(0, 6, 'image')
sheet.write(0, 7, 'url')
for i in range(10):
url = f'http://maoyan.com/board/4?offset={i}0'
get_maoyan(url, sheet, i)
f.save(filename)
结果如下: