机器学习笔记(机器学习很难么???那必然难啊!!!)
机器学习
- 第一章数据挖掘
- 数据挖掘概念
- 数据挖掘的模式类型
- 第二章机器学习
- 1 机器学习分类
- 2 机器学习中的一些概念
- 训练样本
- 训练
- 分类模型
- 验证
- 第三章无监督学习
- 聚类
- K-means聚类算法
- K-means应用
- DBSCAN聚类算法
- DBSACN应用
- 降维
- 主成分分析(PCA)
- 方差
- 协方差和协方差矩阵
- 特征向量和特征值
- 算法过程
- 基于聚类的“图像分割”实例 编写
- 第四章监督学习
- 1、 数据集的划分
- sklearn数据集介绍
- API
- 分类和回归数据集
- 返回类型
- 2、sklearn转换器和估计器
- 1.1 转换器
- 1.2 估计器(sklearn机器学习算法的实现)
- 1.3 估计器工作流程
- 3、K-近邻算法(KNN)
- 1.1 定义
- 1.2 距离公式
- 2、电影类型分析
- 2.1 问题
- 2.2 K-近邻算法数据的特征工程处理
- 3、K-近邻算法API
- 4、案例:预测签到位置
- 4.1 分析
- 4.2 代码
- 4.3 结果分析
- 准确率: 分类算法的评估之一
- 5、K-近邻总结
- 4、模型选择与调优
- 1、为什么需要交叉验证
- 2、什么是交叉验证(cross validation)
- 2.1 分析
- 问题:那么这个只是对于参数得出更好的结果,那么怎么选择或者调优参数呢?
- 3、超参数搜索-网格搜索(Grid Search)
- 3.1 模型选择与调优
- 4、Facebook签到位置预测K值调优
- 5、朴素贝叶斯分类方法
- 1、什么是朴素贝叶斯
- 2、 概率基础
- 2.1 概率(Probability)定义
- 2.2 女神是否喜欢计算案例
- 2.3 条件概率与联合概率
- 3、 贝叶斯公式
- 3.1 公式
- 3.2 文章分类计算
- 思考:我们计算出来某个概率为0,合适吗?
- 3.3 拉普拉斯平滑系数
- 3.4 API
- 4、案例:20类新闻分类
- 4.1 分析
- 4.2 代码
- 5、总结
- 6、决策树
- 1、决策树认识
- 2、决策树分类原理详解
- 2.1 原理
- 2.2 信息熵
- 2.2.1 信息熵的定义
- 2.2.2 总结(重要)
- 2.3 决策树的划分依据之一(信息增益)
- 2.3.1 定义与公式
- 2.3.2 贷款特征重要计算
- 2.4 决策树的三种算法实现
- 2.5 决策树API
- 3、案例:泰坦尼克号乘客生存预测
- 3.1 分析
- 3.2 代码
- 3.3 保存树的结构到dot文件
- 4、 决策树总结
- 第五章关联规则
- 1、关联规则的概念
- 2、关联规则的挖掘过程
- 3、Apriori 算法
- 4、实验实现Apriori 算法
- 5、协同过滤算法的概念
- 6、协同过滤案例(基于用户)
- 第六章图像分析
- 1.图像数据概论
- 2.人脸识别
- 3.人脸识别与PCA
- 4.OpenCV入门
- 1.图像基本操作
- 数据读取-图像
- 数据读取-视频
- 颜色通道提取
- 边界填充
- 数值计算
- 图像融合
- 2.图像处理
- 灰度图
- HSV
- **图像阈值**
- 图像平滑
- 形态学-腐蚀操作
- 形态学-膨胀操作
- 开运算与闭运算
- 梯度运算
- 礼帽与黑帽
- 3.图像梯度与轮廓
- Sobel算子
- Scharr算子
- laplacian算子
- Canny边缘检测
- 图像金字塔
- 图像轮廓
- 傅里叶变换
- 滤波
- 4.直方图与模板匹配
- 直方图
- mask操作
- 直方图均衡化
- 自适应直方图均衡化
- 模板匹配
- 匹配多个对象
- 5.银行卡识别案例
- 1.前期准备
- 2.对模板图像进行预处理操作
- 3.对信用卡进行处理
第一章数据挖掘
数据挖掘概念
数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息,从数据中发现有用的信息,从而帮助我们做出决策
数据挖掘做什么:1预测和描述数据,预测的计算机和事件过程被称为监督学习:从标记的训练数据来推断一个功能的机器学习任务
描述则被通常称为无监督学习:根据位置样本决绝模式识别中的各种问题
知识发现KDD:1)定义知识发现的目标
2)数据采集
3)数据探索
4)特征工程与数据预处理
数据挖掘的模式类型
类/概念描述:特征和区分:类/概念描述就是通过对某类对象的关联数据进行处理、汇总和分析,概括这类对象的属性特征,再用精简的的方式对此类对象的内涵进行描述
回归(regression):回归分析是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,这是统计学中对回归分析的定义,不大容易理解
分类(classification):分类算法是将我们思考的过程进行了自动化或半自动化。数据挖掘中的分类典型的应用是根据事物在数据层面表现的特征,对事物进行科学的分类。分类与回归的区别在于:回归可用于预测连续的目标变量,分类可用于预测离散的目标变量。
预测(forecasting):预测是在基于历史数据采用某种数学模型来预测未来的一种算法,即以现有数据为基础,对未来的数据进行预测。预测可以发现客观事物运行规律,预见到未来可能出现的情况,提出各种可以互相替代的发展方案,这样就为人们的决策制定提供了科学依
关联分析(association):关联分析用来发现描述数据中强关联特征的模式
聚类分析(cluster):聚类分析是一种理想的多变量统计技术。聚类分析的思想可用“物以类聚”来表述,讨论的对象是大量无标签值的样本,要求能按样本的各自特征在无标签的情况下对样本进行分类,是在没有先验知识的情况下进行的
异常检测(anomalydetection):异常检测的目的是识别出数据特征显著区别于其它数据的异常对象(离群点或是异常点)
第二章机器学习
1 机器学习分类
传统机器学习
机器学习可以理解成是生产算法的算法。需要人来先做特征提取,然后在把特征向量化后交给机器去训练。
传统机器学习分为 监督学习 和 无监督学习。
深度学习
深度学习是基于深度神经网络的学习(DNN)。深度学习可以自动提取特征。深度学习可以采用 End-to-End 的学习方式,只需要进行很少的归一化和白化,就可以将数据交给模型去训练。
2 机器学习中的一些概念
首先我们需要了解几个机器学习中的起码要知道是怎么回事的概念,了解了后面看代码才不会一脸懵逼。
训练样本
就是用于训练的数据。包括了现实中的一些信息数据,以及对应的结果,也就是标签。
训练
对训练样本的特征进行统计和归纳的过程。
分类模型
总结出的特征,判断标准。
验证
用测试数据集验证模型是否正确的过程。这个过程是在模型训练完后进行的,就是再用另外一些样本数据,代入到模型中去,看它的准确率如何。
第三章无监督学习
聚类
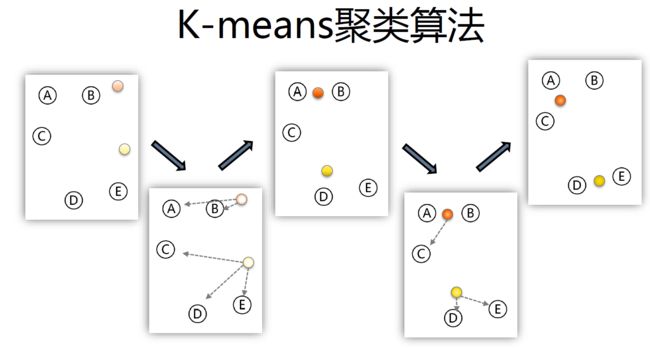
K-means聚类算法
kmeans 算法以 k 为参数,把 n 个对象分成 k 个簇,使簇内具有较高的相似度,而簇间的相似度较低。其处理过程如下:
1.随机选择 k 个点作为初始的聚类中心;
2.对于剩下的点,根据其与聚类中心的距离,将其归入最近的簇
3.对每个簇,计算所有点的均值作为新的聚类中心
4.重复 2 、 3 直到聚类中心不再发生改变
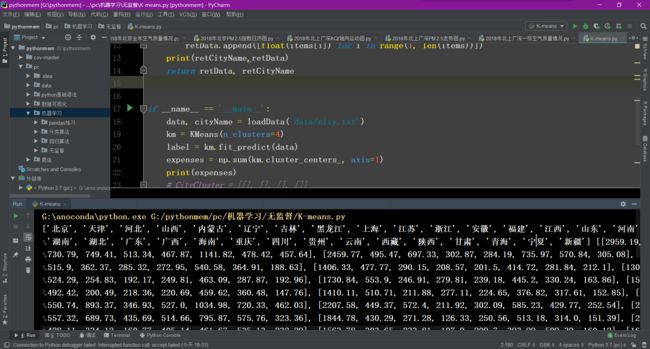
K-means应用









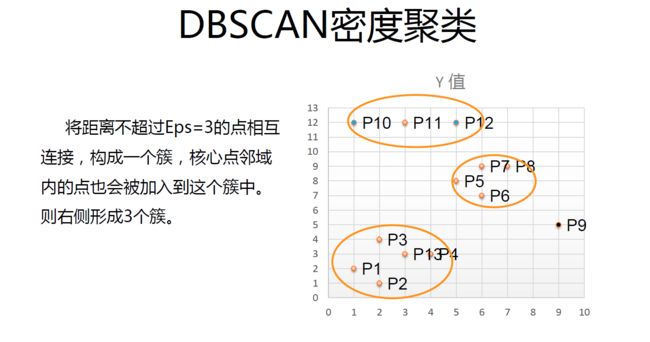
DBSCAN聚类算法
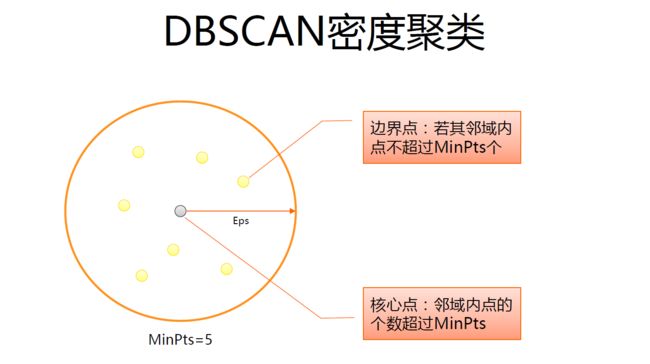
DBSCAN算法是一种基于密度的聚类算法:聚类的时候不需要预先指定簇的个数最终的簇的个数不定
DBSCAN
算法将数据点分为三类:
核心 点:在半径 Eps 内含有超过 MinPts 数目的 点
边界点:在半径 Eps 内点的数量小于 MinPts ,但是落在核心点的邻域 内
噪音点:既不是核心点也不是边界点的点
DBSCAN算法流程:
1.将所有点标记为核心点、边界点或噪声点;
2.删除噪声点;
3.为距离在 Eps 之内的所有核心点之间赋予一条边;
4.每组连通的核心点形成一个簇;
5.将每个边界点指派到一个与之关联的核心点的簇中(哪一个核心点的半径范围之内)。
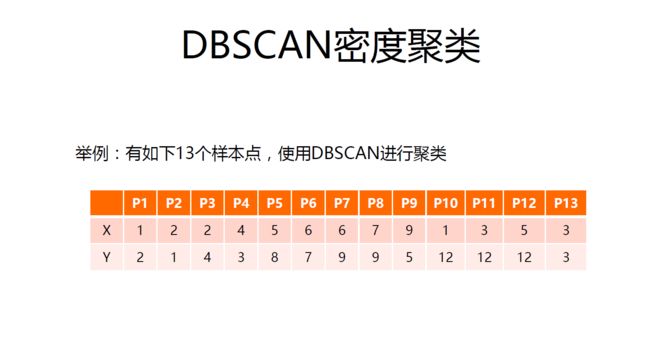
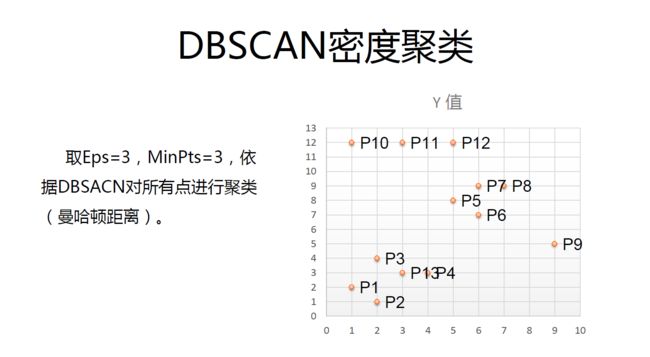

DBSACN应用


降维
主成分分析(PCA)
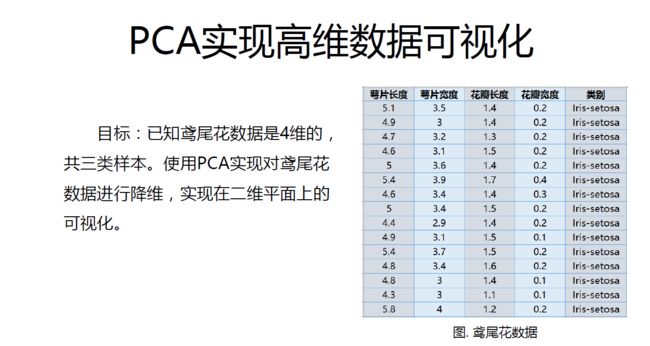
主成分分析( Principal Component Analysis PCA )是最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等。
PCA 可以把具有相关性的高维变量合成为线性无关的低维变量,称为主成分。主成分能够尽可能保留原始数据的信息。
原理:矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,以此类推。
在介绍PCA 的原理之前需要回顾涉及到的相关术语:
方差

协方差和协方差矩阵

特征向量和特征值

算法过程



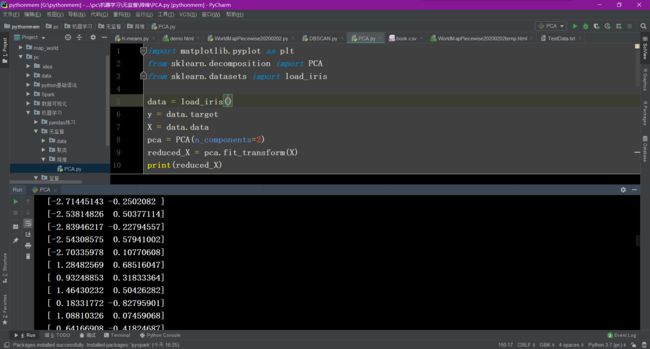
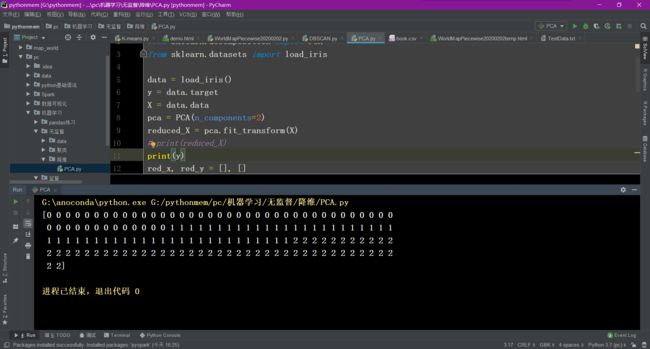



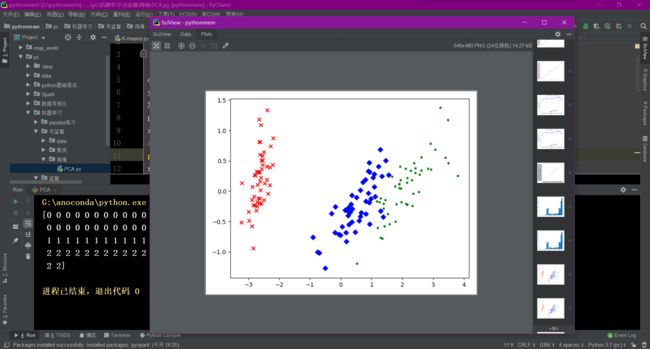
可以看出,降维后的数据仍能够清晰地分成三类。这样不仅能削减数据的维度,降低分类任务的工作量,还能保证分类的质量。
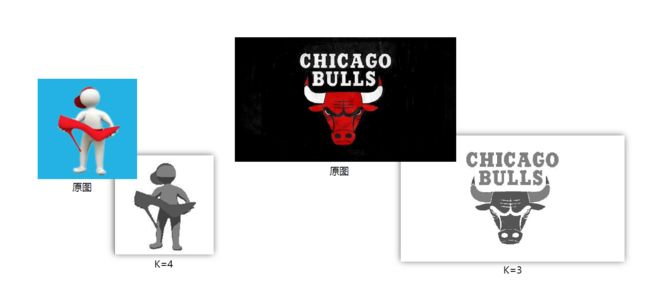
基于聚类的“图像分割”实例 编写
图像分割:利用图像的灰度、颜色、纹理、形状等特征,把 图像 分成 若干 个 互不重叠 的 区域,并使这些特征在同一区域内呈现相似性,在不同的区
域之间存在明显的差异性 。 然后就可以将分割的图像中 具有 独特性质的 区域提取 出来用于不同的研究。图像分割技术已在实际生活中得到广泛的应用。例如:在机车检验领域,可以应用到轮毂裂纹图像的分割,及时发现裂纹,保证行车安全;在生物医学工程方面,对肝脏 CT 图像进行分割,为临床治疗和病理学研究提供帮助。
图像分割常用方法:
1.阈值分割:对图像灰度值进行度量,设置不同类别的阈值,达到分割的目的。
2.边缘分割:对图像边缘进行检测,即检测图像中灰度值发生跳变的地方,则为一片区域的边缘。
3.直方图法:对图像的颜色建立直方图,而直方图的波峰波谷能够表示一块区域的颜色值的范围,来达到分割的目的。
4.特定理论:基于 聚类分析 、小波变换等理论完成图像分割。

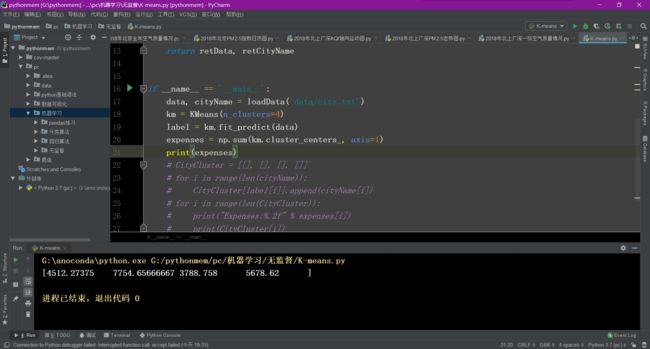
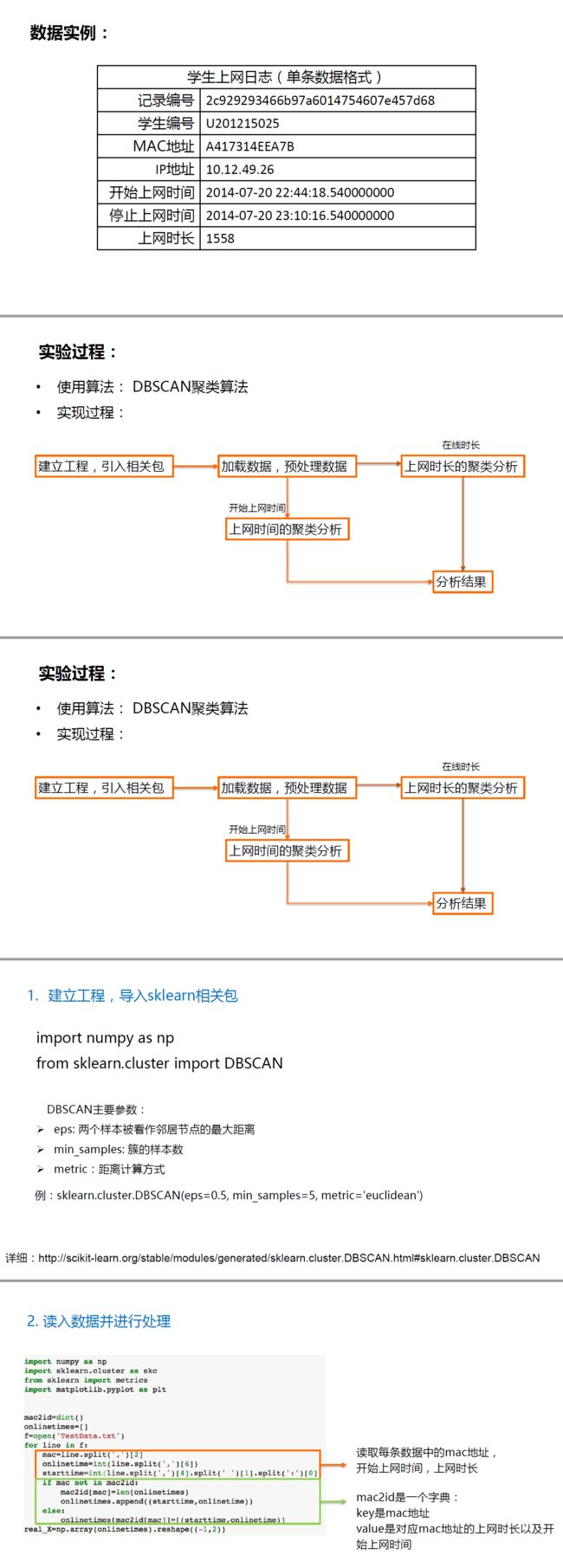
import numpy as np
import PIL.Image as image 加载 PIL 包,用于加载创建图片
from sklearn.cluster import KMeans 加载 Kmeans 算法
#加载训练数据
def loadData(filePath):
f = open(filePath,'rb')#以二进制形式代开文件
data = [] #一列表形式返回像素值
img = image.open(f)
m,n = img.size #图片大小
for i in range(m):
for j in range(n):
x,y,z = img.getpixel((i,j))
data.append([x/256.0,y/256.0,z/256.0])
f.close()
return np.mat(data),m,n #以矩阵形式返回data和图片大小
imgData,row,col = loadData('kmeans/bull.jpg')
label = KMeans(n_clusters=4).fit_predict(imgData) #其中n_clusters属性指定了聚类中心的个数为3
#聚类获取每个像素所属类别
label = label.reshape([row,col])
#创建灰色图片保存聚类后的效果
pic_new = image.new("L", (row, col))
for i in range(row):
for j in range(col):
pic_new.putpixel((i,j), int(256/(label[i][j]+1)))
pic_new.save("result-bull-4.jpg", "JPEG")
第四章监督学习
1、 数据集的划分
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
-
训练集:70% 80% 75%
-
测试集:30% 20% 30%
-
sklearn.model_selection.train_test_split(arrays, *options)
- x 数据集的特征值
- y 数据集的标签值
- test_size 测试集的大小,一般为float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
- return ,测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
结合后面的数据集作介绍
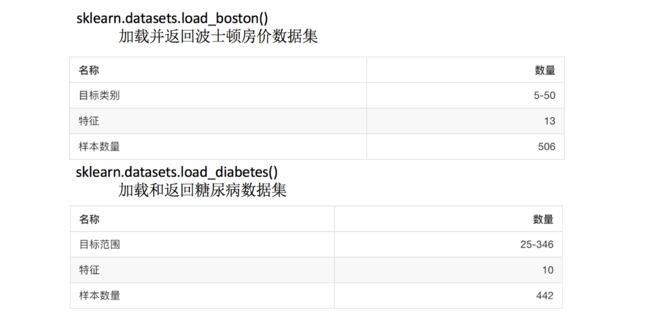
sklearn数据集介绍
API
- sklearn.datasets
- 加载获取流行数据集
- datasets.load_*()
- 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None)
- 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
分类和回归数据集
- 分类数据集

- sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
- subset: ‘train’或者’test’,‘all’,可选,选择要加载的数据集.训练集的“训练”,测试集的“测试”,两者的“全部”
- 回归数据集
返回类型
load和 fetch返回的数据类型datasets.base.Bunch(字典格式)
- data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名,新闻数据,手写数字、回归数据集没有
- target_names:标签名
2、sklearn转换器和估计器
1.1 转换器
想一下之前做的特征工程的步骤?
- 1、实例化 (实例化的是一个转换器类(Transformer))
- 2、调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
我们把特征工程的接口称之为转换器,其中转换器调用有这么几种形式
- fit_transform
- fit
- transform
这几个方法之间的区别是什么呢?我们看以下代码就清楚了
In [1]: from sklearn.preprocessing import StandardScaler
In [2]: std1 = StandardScaler()
In [3]: a = [[1,2,3], [4,5,6]]
In [4]: std1.fit_transform(a)
Out[4]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])
In [5]: std2 = StandardScaler()
In [6]: std2.fit(a)
Out[6]: StandardScaler(copy=True, with_mean=True, with_std=True)
In [7]: std2.transform(a)
Out[7]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])
从中可以看出,fit_transform的作用相当于transform加上fit。但是为什么还要提供单独的fit呢, 我们还是使用原来的std2来进行标准化看看
In [8]: b = [[7,8,9], [10, 11, 12]]
In [9]: std2.transform(b)
Out[9]:
array([[3., 3., 3.],
[5., 5., 5.]])
In [10]: std2.fit_transform(b)
Out[10]:
array([[-1., -1., -1.],
[ 1., 1., 1.]])
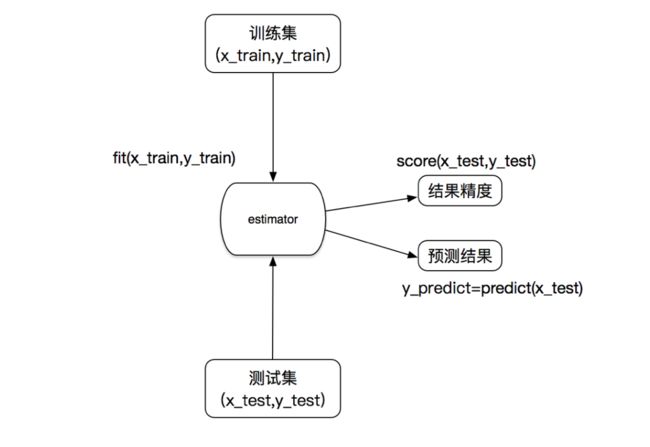
1.2 估计器(sklearn机器学习算法的实现)
在sklearn中,估计器(estimator)是一个重要的角色,是一类实现了算法的API
- 1、用于分类的估计器:
- sklearn.neighbors k-近邻算法
- sklearn.naive_bayes 贝叶斯
- sklearn.linear_model.LogisticRegression 逻辑回归
- sklearn.tree 决策树与随机森林
- 2、用于回归的估计器:
- sklearn.linear_model.LinearRegression 线性回归
- sklearn.linear_model.Ridge 岭回归
- 3、用于无监督学习的估计器
- sklearn.cluster.KMeans 聚类
1.3 估计器工作流程
3、K-近邻算法(KNN)
1.1 定义
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
1.2 距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离
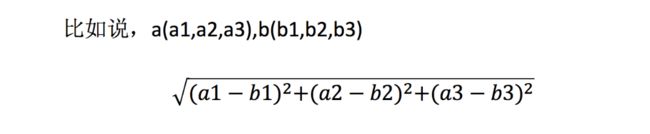
2、电影类型分析
假设我们有现在几部电影
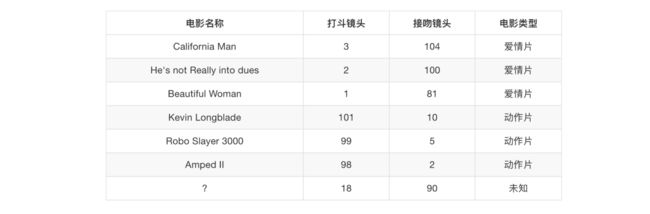
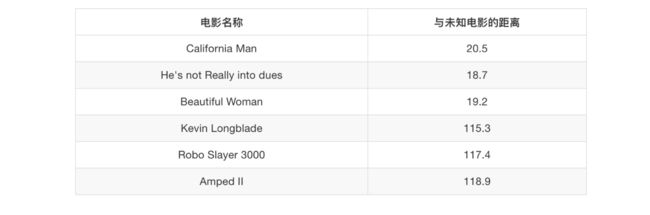
其中? 号电影不知道类别,如何去预测?我们可以利用K近邻算法的思想
2.1 问题
- 如果取的最近的电影数量不一样?会是什么结果?
2.2 K-近邻算法数据的特征工程处理
- 结合前面的约会对象数据,分析K-近邻算法需要做什么样的处理
3、K-近邻算法API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm=‘auto’)
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
4、案例:预测签到位置

数据介绍:将根据用户的位置,准确性和时间戳预测用户正在查看的业务。
train.csv,test.csv
row_id:登记事件的ID
xy:坐标
准确性:定位准确性
时间:时间戳
place_id:业务的ID,这是您预测的目标
官网:https://www.kaggle.com/navoshta/grid-knn/data
https://pan.baidu.com/s/1q3PV0Z1PRH-G9eKrVus7Kw 提取码:n1nb
4.1 分析
-
对于数据做一些基本处理(这里所做的一些处理不一定达到很好的效果,我们只是简单尝试,有些特征我们可以根据一些特征选择的方式去做处理)
-
1、缩小数据集范围 DataFrame.query()
-
4、删除没用的日期数据 DataFrame.drop(可以选择保留)
-
5、将签到位置少于n个用户的删除
place_count = data.groupby(‘place_id’).count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data[‘place_id’].isin(tf.place_id)]
-
-
分割数据集
-
标准化处理
-
k-近邻预测
4.2 代码
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.neighbors import KNeighborsClassifier
def knncls():
"""
K近邻算法预测入住位置类别
:return:
"""
# 一、处理数据以及特征工程
# 1、读取收,缩小数据的范围
data = pd.read_csv("./data/FBlocation/train.csv")
# 数据逻辑筛选操作 df.query()
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 删除time这一列特征
data = data.drop(['time'], axis=1)
print(data)
# 删除入住次数少于三次位置
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 3、取出特征值和目标值
y = data['place_id']
# y = data[['place_id']]
x = data.drop(['place_id', 'row_id'], axis=1)
# 4、数据分割与特征工程?
# (1)、数据分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# (2)、标准化
std = StandardScaler()
# 队训练集进行标准化操作
x_train = std.fit_transform(x_train)
print(x_train)
# 进行测试集的标准化操作
x_test = std.fit_transform(x_test)
# 二、算法的输入训练预测
# K值:算法传入参数不定的值 理论上:k = 根号(样本数)
# K值:后面会使用参数调优方法,去轮流试出最好的参数[1,3,5,10,20,100,200]
knn = KNeighborsClassifier(n_neighbors=1)
# 调用fit()
knn.fit(x_train, y_train)
# 预测测试数据集,得出准确率
y_predict = knn.predict(x_test)
print("预测测试集类别:", y_predict)
print("准确率为:", knn.score(x_test, y_test))
return None
knncls()
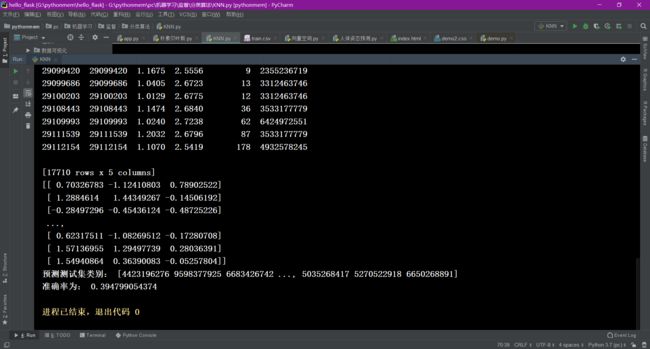
3千万条数据准确率比较低
4.3 结果分析
准确率: 分类算法的评估之一
- 1、k值取多大?有什么影响?
k值取很小:容易受到异常点的影响
k值取很大:受到样本均衡的问题
- 2、性能问题?
距离计算上面,时间复杂度高
5、K-近邻总结
- 优点:
- 简单,易于理解,易于实现,无需训练
- 缺点:
- 懒惰算法,对测试样本分类时的计算量大,内存开销大
- 必须指定K值,K值选择不当则分类精度不能保证
- 使用场景:小数据场景,几千~几万样本,具体场景具体业务去测试
4、模型选择与调优
1、为什么需要交叉验证
交叉验证目的:为了让被评估的模型更加准确可信
2、什么是交叉验证(cross validation)
它的基本思想就是将原始数据(dataset)进行分组,一部分做为训练集来训练模型,另一部分做为测试集来评价模型。
2.1 分析
我们之前知道数据分为训练集和测试集,但是**为了让从训练得到模型结果更加准确。**做以下处理
- 训练集:训练集+验证集
- 测试集:测试集
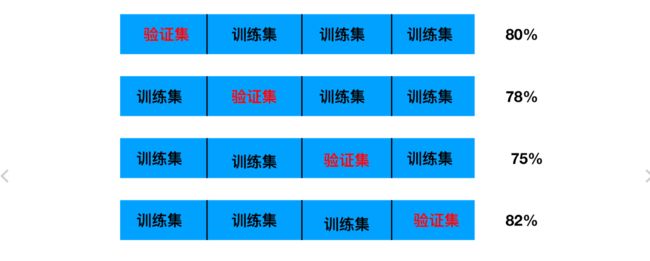
问题:那么这个只是对于参数得出更好的结果,那么怎么选择或者调优参数呢?
3、超参数搜索-网格搜索(Grid Search)
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

3.1 模型选择与调优
- sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- 对估计器的指定参数值进行详尽搜索
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
- fit:输入训练数据
- score:准确率
- 结果分析:
- bestscore:在交叉验证中验证的最好结果_
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
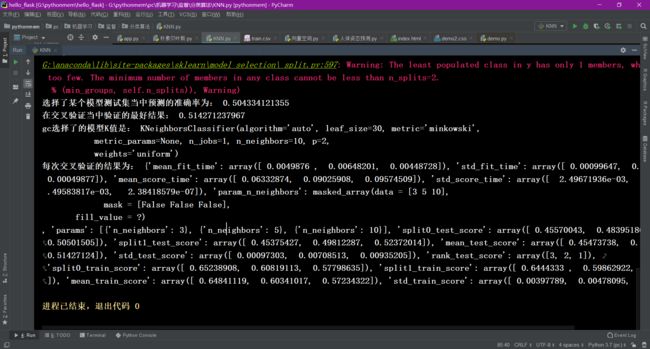
4、Facebook签到位置预测K值调优
- 使用网格搜索估计器
# 使用网格搜索和交叉验证找到合适的参数
knn = KNeighborsClassifier()
param = {"n_neighbors": [3, 5, 10]}
gc = GridSearchCV(knn, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("选择了某个模型测试集当中预测的准确率为:", gc.score(x_test, y_test))
# 训练验证集的结果
print("在交叉验证当中验证的最好结果:", gc.best_score_)
print("gc选择了的模型K值是:", gc.best_estimator_)
print("每次交叉验证的结果为:", gc.cv_results_)
5、朴素贝叶斯分类方法
1、什么是朴素贝叶斯
2、 概率基础
2.1 概率(Probability)定义
- 概率定义为一件事情发生的可能性
- 扔出一个硬币,结果头像朝上
- 某天是晴天
- P(X) : 取值在[0, 1]
2.2 女神是否喜欢计算案例
在讲这两个概率之前我们通过一个例子,来计算一些结果:
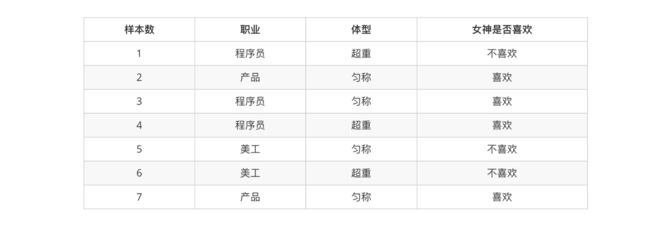
- 问题如下:

那么其中有些问题我们计算的结果不正确,或者不知道计算,我们有固定的公式去计算
2.3 条件概率与联合概率
- 联合概率:包含多个条件,且所有条件同时成立的概率
- 记作:P(A,B)
- 特性:P(A, B) = P(A)P(B)
- 条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
- 记作:P(A|B)
- 特性:P(A1,A2|B) = P(A1|B)P(A2|B)
注意:此条件概率的成立,是由于A1,A2相互独立的结果(记忆)
这样我们计算结果为:
p(程序员, 匀称) = P(程序员)P(匀称) =3/7*(4/7) = 12/49
P(产品, 超重|喜欢) = P(产品|喜欢)P(超重|喜欢)=1/2 * 1/4 = 1/8
那么,我们知道了这些知识之后,继续回到我们的主题中。朴素贝叶斯如何分类,这个算法经常会用在文本分类,那就来看文章分类是一个什么样的问题?

这个了类似一个条件概率,那么仔细一想,给定文章其实相当于给定什么?结合前面我们将文本特征抽取的时候讲的?所以我们可以理解为

但是这个公式怎么求?前面并没有参考例子,其实是相似的,我们可以使用贝叶斯公式去计算
3、 贝叶斯公式
3.1 公式
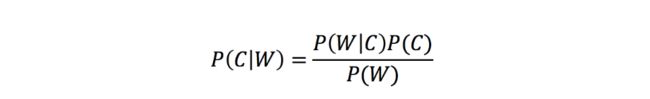
那么这个公式如果应用在文章分类的场景当中,我们可以这样看:
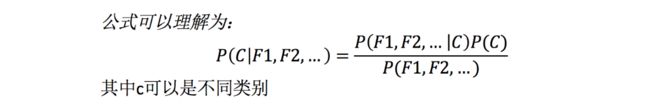
公式分为三个部分:
- P©:每个文档类别的概率(某文档类别数/总文档数量)
- P(W│C):给定类别下特征(被预测文档中出现的词)的概率
- 计算方法:P(F1│C)=Ni/N (训练文档中去计算)
- Ni为该F1词在C类别所有文档中出现的次数
- N为所属类别C下的文档所有词出现的次数和
- 计算方法:P(F1│C)=Ni/N (训练文档中去计算)
- P(F1,F2,…) 预测文档中每个词的概率
如果计算两个类别概率比较:

所以我们只要比较前面的大小就可以,得出谁的概率大
3.2 文章分类计算
- 假设我们从训练数据集得到如下信息
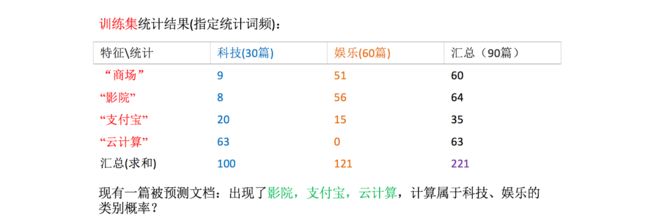
- 计算结果
科技:P(科技|影院,支付宝,云计算) = (影院,支付宝,云计算|科技)∗P(科技)=(8/100)∗(20/100)∗(63/100)∗(30/90) = 0.00456109
娱乐:P(娱乐|影院,支付宝,云计算) = (影院,支付宝,云计算|娱乐)∗P(娱乐)=(56/121)∗(15/121)∗(0/121)∗(60/90) = 0
思考:我们计算出来某个概率为0,合适吗?
3.3 拉普拉斯平滑系数
目的:防止计算出的分类概率为0

P(娱乐|影院,支付宝,云计算) =P(影院,支付宝,云计算|娱乐)P(娱乐) =P(影院|娱乐)*P(支付宝|娱乐)*P(云计算|娱乐)P(娱乐)=(56+1/121+4)(15+1/121+4)(0+1/121+1*4)(60/90) = 0.00002
3.4 API
- sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
- 朴素贝叶斯分类
- alpha:拉普拉斯平滑系数
4、案例:20类新闻分类
4.1 分析
- 分割数据集
- tfidf进行的特征抽取
- 朴素贝叶斯预测
4.2 代码
from sklearn.naive_bayes import MultinomialNB
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
def nbcls():
"""
朴素贝叶斯对新闻数据集进行预测
:return:
"""
# 获取新闻的数据,20个类别
news = fetch_20newsgroups(subset='all')
# 进行数据集分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.3)
# 对于文本数据,进行特征抽取
tf = TfidfVectorizer()
x_train = tf.fit_transform(x_train)
x_test = tf.transform(x_test)
# estimator估计器流程
mlb = MultinomialNB(alpha=1.0)
mlb.fit(x_train, y_train)
# 进行预测
y_predict = mlb.predict(x_test)
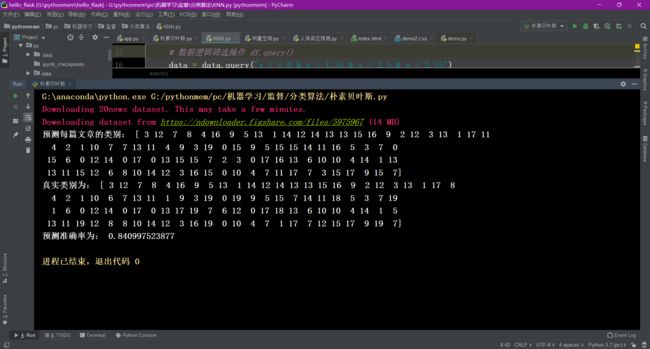
print("预测每篇文章的类别:", y_predict[:100])
print("真实类别为:", y_test[:100])
print("预测准确率为:", mlb.score(x_test, y_test))
return None
nbcls()
5、总结
- 优点:
- 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
- 分类准确度高,速度快
- 缺点:
- 由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好
6、决策树
1、决策树认识
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法
怎么理解这句话?通过一个对话例子

想一想这个女生为什么把年龄放在最上面判断!!!!!!!!!
2、决策树分类原理详解
为了更好理解决策树具体怎么分类的,我们通过一个问题例子?
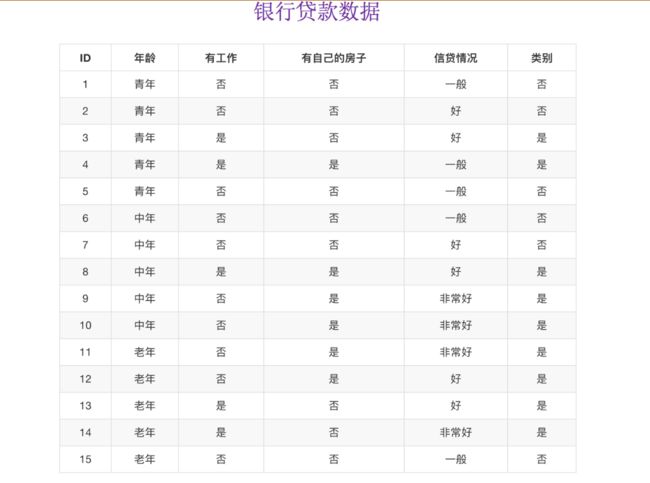
问题:如何对这些客户进行分类预测?你是如何去划分?
有可能你的划分是这样的
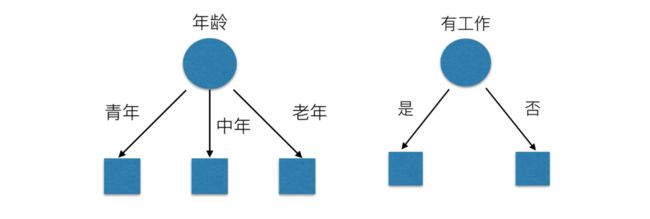
那么我们怎么知道这些特征哪个更好放在最上面,那么决策树的真是划分是这样的
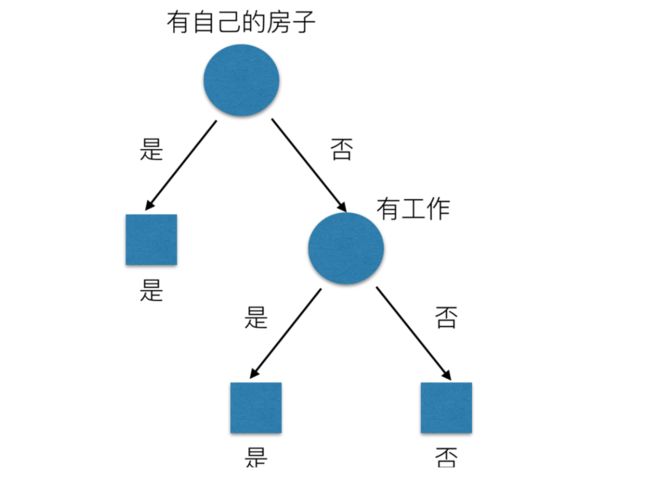
2.1 原理
- 信息熵、信息增益等
需要用到信息论的知识!!!问题:通过例子引入信息熵
2.2 信息熵
那来玩个猜测游戏,猜猜这32支球队那个是冠军。并且猜测错误付出代价。每猜错一次给一块钱,告诉我是否猜对了,那么我需要掏多少钱才能知道谁是冠军? (前提是:不知道任意球队的信息、历史比赛记录、实力等)
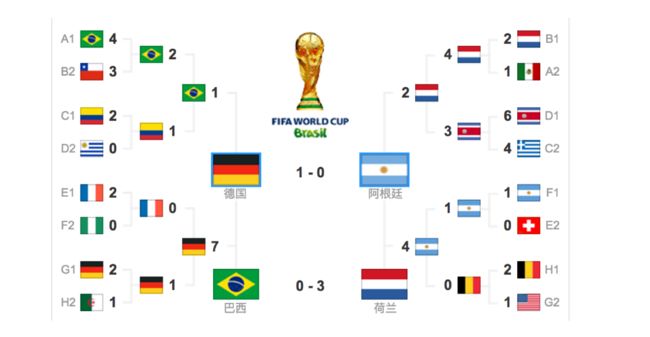
为了使代价最小,可以使用二分法猜测:
我可以把球编上号,从1到32,然后提问:冠 军在1-16号吗?依次询问,只需要五次,就可以知道结果。

我们来看这个式子:
- 32支球队,log32=5比特
- 64支球队,log64=6比特

香农指出,它的准确信息量应该是,p为每个球队获胜的概率(假设概率相等,都为1/32),我们不用钱去衡量这个代价了,香浓指出用比特:
H = -(p1logp1 + p2logp2 + ... + p32log32) = - log32
2.2.1 信息熵的定义
- H的专业术语称之为信息熵,单位为比特。
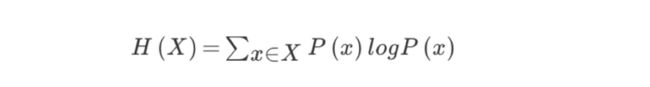
“谁是世界杯冠军”的信息量应该比5比特少,特点(重要):
- 当这32支球队夺冠的几率相同时,对应的信息熵等于5比特
- 只要概率发生任意变化,信息熵都比5比特大
2.2.2 总结(重要)
- 信息和消除不确定性是相联系的
当我们得到的额外信息(球队历史比赛情况等等)越多的话,那么我们猜测的代价越小(猜测的不确定性减小)
问题: 回到我们前面的贷款案例,怎么去划分?可以利用当得知某个特征(比如是否有房子)之后,我们能够减少的不确定性大小。越大我们可以认为这个特征很重要。那怎么去衡量减少的不确定性大小呢?
2.3 决策树的划分依据之一(信息增益)
2.3.1 定义与公式
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:
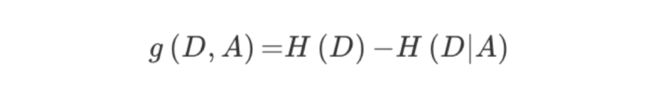
公式的详细解释:

注:信息增益表示得知特征X的信息而息的不确定性减少的程度使得类Y的信息熵减少的程度
2.3.2 贷款特征重要计算
- 我们以年龄特征来计算:
1、g(D, 年龄) = H(D) -H(D|年龄) = 0.971-[5/15H(青年)+5/15H(中年)+5/15H(老年)]
2、H(D) = -(6/15log(6/15)+9/15log(9/15))=0.971
3、H(青年) = -(3/5log(3/5) +2/5log(2/5))
H(中年)=-(3/5log(3/5) +2/5log(2/5))
H(老年)=-(4/5og(4/5)+1/5log(1/5))
我们以A1、A2、A3、A4代表年龄、有工作、有自己的房子和贷款情况。最终计算的结果g(D, A1) = 0.313, g(D, A2) = 0.324, g(D, A3) = 0.420,g(D, A4) = 0.363。所以我们选择A3 作为划分的第一个特征。这样我们就可以一棵树慢慢建立
2.4 决策树的三种算法实现
当然决策树的原理不止信息增益这一种,还有其他方法。但是原理都类似,我们就不去举例计算。
- ID3
- 信息增益 最大的准则
- C4.5
- 信息增益比 最大的准则
- CART
- 分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的默认原则
- 优势:划分更加细致(从后面例子的树显示来理解)
2.5 决策树API
- class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
- 决策树分类器
- criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
- max_depth:树的深度大小
- random_state:随机数种子
- 其中会有些超参数:max_depth:树的深度大小
- 其它超参数我们会结合随机森林讲解
3、案例:泰坦尼克号乘客生存预测
- 泰坦尼克号数据
在泰坦尼克号和titanic2数据帧描述泰坦尼克号上的个别乘客的生存状态。这里使用的数据集是由各种研究人员开始的。其中包括许多研究人员创建的旅客名单,由Michael A. Findlay编辑。我们提取的数据集中的特征是票的类别,存活,乘坐班,年龄,登陆,home.dest,房间,票,船和性别。
1、乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
2、其中age数据存在缺失。
数据:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt
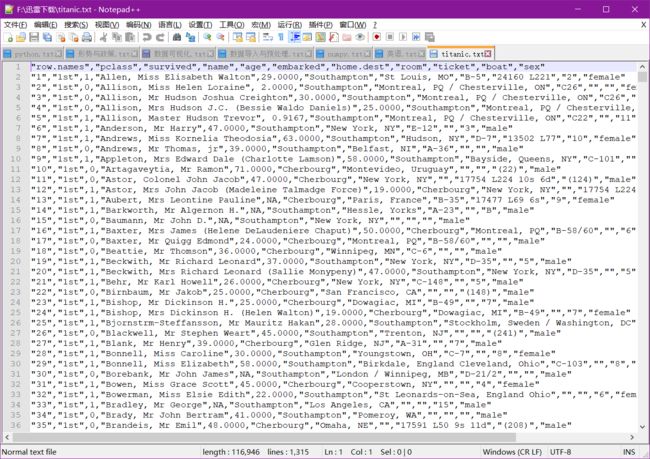
3.1 分析
- 选择我们认为重要的几个特征 [‘pclass’, ‘age’, ‘sex’]
- 填充缺失值
- 特征中出现类别符号,需要进行one-hot编码处理(DictVectorizer)
- x.to_dict(orient=“records”) 需要将数组特征转换成字典数据
- 数据集划分
- 决策树分类预测
3.2 代码
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.feature_extraction import DictVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import pandas as pd
def decisioncls():
"""
决策树进行乘客生存预测
:return:
"""
# 1、获取数据
titan = pd.read_csv("dataset/titanic.txt")
# 2、数据的处理
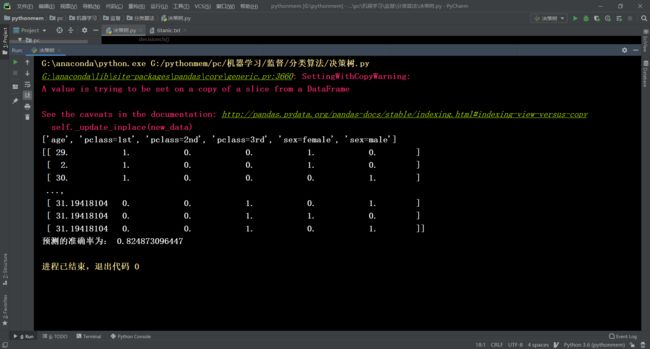
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
# print(x , y)
# 缺失值需要处理,将特征当中有类别的这些特征进行字典特征抽取
x['age'].fillna(x['age'].mean(), inplace=True)
# 对于x转换成字典数据x.to_dict(orient="records")
# [{"pclass": "1st", "age": 29.00, "sex": "female"}, {}]
dict = DictVectorizer(sparse=False)
x = dict.fit_transform(x.to_dict(orient="records"))
print(dict.get_feature_names())
print(x)
# 分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# 进行决策树的建立和预测
dc = DecisionTreeClassifier(max_depth=5)
dc.fit(x_train, y_train)
print("预测的准确率为:", dc.score(x_test, y_test))
return None
if __name__ == "__main__":
decisioncls()
3.3 保存树的结构到dot文件
- 1、sklearn.tree.export_graphviz() 该函数能够导出DOT格式
- tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
- 2、工具:(能够将dot文件转换为pdf、png)
- 安装graphviz
- ubuntu:sudo apt-get install graphviz Mac:brew install graphviz
- 3、运行命令
- 然后我们运行这个命令
- dot -Tpng tree.dot -o tree.png
export_graphviz(dc, out_file="./tree.dot", feature_names=['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])
4、 决策树总结
- 优点:
- 简单的理解和解释,树木可视化。
- 缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
- 改进:
- 减枝cart算法(决策树API当中已经实现,随机森林参数调优有相关介绍)
- 随机森林
注:企业重要决策,由于决策树很好的分析能力,在决策过程应用较多, 可以选择特征
第五章关联规则
1、关联规则的概念
关联规则(Association Rules,又称Basket Analysis) 是形如X→Y 的蕴涵式,其中, X 和Y分别称为关联规则的先导(antecedent 或left-hand-side, LHS)和后继(consequent 或right-hand-side,RHS) 。在这当中,关联规则XY,利用其支持度和置信度从大量数据中挖掘出有价值的数据项之120间的相关关系。关联规则解决的常见问题如:“如果一个消费者购买了产品A,那么他有多大机会购买产品B?”以及“如果他购买了产品C 和D,那么他还将购买什么产品?”
关联规则定义:
假设I = {I1,I2,。。。Im}是项的集合,包含k 个项的项集称为k 项集(k-itemset)。给定一个交易数据库D,其中每个事务(Transaction)T 是I 的非空子集,即每一个交易都与一个唯一的标识符TID(Transaction ID)对应。关联规则在D 中的支持度(support)是D 中事务同时包含X、Y 的百分比,即概率;置信度(confidence)是D 中事务已经包含X 的情况下,包含Y 的百分比,即条件概率。如果满足最小支持度阈值和最小置信度阈值,则认为关联规则是有趣的。这些阈值是根据挖掘需要人为设定。
关联规则的简单例子。
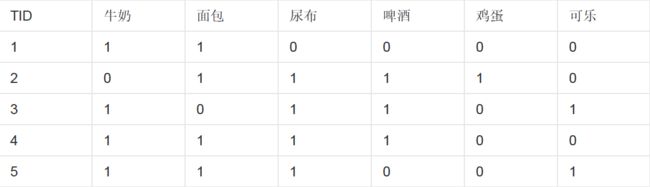
表7-1 顾客购买数据记录表用一个简单的例子说明。上表格7-1 是顾客购买记录的数据库D,包含6 个事务, 即D=6。项集I={牛奶,面包,尿布,啤酒,鸡蛋}。考虑关联规则(频繁二项集):牛奶与面包,事务1,3,4,5 包含牛奶,事务1,4,5 同时包含牛奶和面包,那么说明牛奶和面包包含3个事务,即X∩Y=3,支持度(X∩Y)/D=0.5;在数据库D 中四个事务是包含牛奶的,既X=5,因而置信度(X∩Y)/X=0.6。若给定最小支持度α = 0.5,最小置信度β = 0.6,认为购买牛奶和购买面包之间存在关联。
2、关联规则的挖掘过程
两个阶段:
关联规则挖掘过程主要包含两个阶段:第一阶段必须先从资料集合中找出所有的高频项目组(Frequent Itemsets),第二阶段再由这些高频项目组中产生关联规则(Association Rules)。
关联规则挖掘的第一阶段必须从原始资料集合中,找出所有高频项目组(Large Itemsets)。高频的意思是指某一项目组出现的频率相对于所有记录而言,必须达到某一水平。一项目组出现的频率称为支持度(Support),以一个包含A 与B 两个项目的2-itemset 为例,我们可以经由公式求得包含{A,B}项目组的支持度,若支持度大于等于所设定的最小支持度(Minimum Support)门槛值时,则{A,B}称为高频项目组。一个满足最小支持度的k-itemset,则称为高频k-项目组(Frequentk-itemset),一般表示为Large k 或Frequent k。算法并从Large k 的项目组中再产生Large k+1,直到无法再找到更长的高频项目组为止。
关联规则挖掘的第二阶段是要产生关联规则(Association Rules)。从高频项目组产生关联规则,是利用前一步骤的高频k-项目组来产生规则,在最小置信度(Minimum Confidence)的条件门槛下,数据挖掘技术与应用121若一规则所求得的置信度满足最小置信度,称此规则为关联规则。例如:经由高频k-项目组{A,B}所产生的规则AB,其置信度可经由公式求得,若置信度大于等于最小置信度,则称AB 为关联规则。
3、Apriori 算法
Apriori 算法概念
Apriori 算法是经典的挖掘频繁项集和关联规则的数据挖掘算法。Apriori 在拉丁语中指"来自以前"。当定义问题时,通常会使用先验知识或者假设,这被称作"一个先验"(a priori)。Apriori算法的名字正是基于这样的事实:算法使用频繁项集性质的先验性质,即频繁项集的所有非空子集也一定是频繁的。Apriori 算法使用一种称为逐层搜索的迭代方法,其中k 项集用于探索(k+1)项集。首先,通过扫描数据库,累计每个项的计数,并收集满足最小支持度的项,找出频繁1项集的集合。该集合记为1 L 。然后,使用1 L 找出频繁2 项集的集合2 L ,使用2 L 找出3 L ,如此下去,直到不能再找到频繁k 项集。每找出一个k L 需要一次数据库的完整扫描。Apriori 算法使用频繁项集的先验性质来压缩搜索空间。
虽然Apriori 算法看似很完美,但其有一些难以克服的缺点:
(1)对数据库的扫描次数过多。
(2)Apriori 算法会产生大量的中间项集。
(3)采用唯一支持度。
(4)算法的适应面窄。

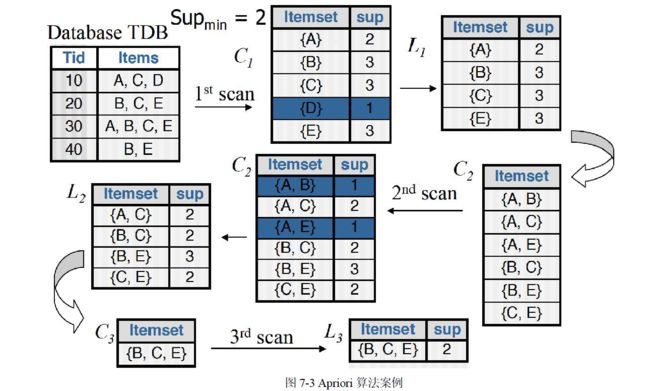
这里没有说是根据什么条件来找出C2和C3

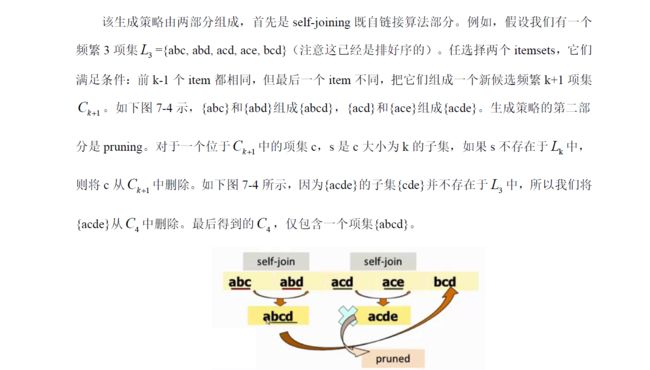
4、实验实现Apriori 算法
5、协同过滤算法的概念
什么是协同过滤?协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤(Collaborative Filtering, 简称CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。
协同过滤一般是在海量的用户中发掘出一小部分和你品位比较类似的,在协同过滤中,这些用户成为邻居,然后根据他们喜欢的其他东西组织成一个排序的目录作为推荐给你。当然其中有一个核的问题:
如何确定一个用户是不是和你有相似的品位?
如何将邻居们的喜好组织成一个排序的目录?
协同过滤相对于集体智慧而言,它从一定程度上保留了个体的特征,就是你的品位偏好,所以它更多可以作为个性化推荐的算法思想。可以想象,这种推荐策略在Web 2.0 的长尾中是很重要的,将大众流行的东西推荐给长尾中的人怎么可能得到好的效果,这也回到推荐系统的一个核心问题:了解你的用户,然后才能给出更好的推荐。
协同过滤推荐算法是诞生最早,并且较为著名的推荐算法。主要的功能是预测和推荐。算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。
协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法(user-basedcollaboratIve filtering),和基于物品的协同过滤算法(item-based collaborative filtering)。简单的说就是:人以类聚,物以群分。
协同过滤的基本流程:
首先,要实现协同过滤,需要以下几个步骤
(1)收集用户偏好
(2)找到相似的用户或物品
(3)计算推荐
6、协同过滤案例(基于用户)
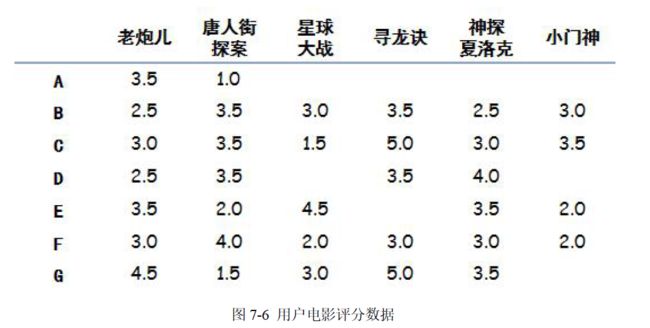
案例:基于用户的协同过滤。
假设有几个人分别看了如图7-6 电影并且给电影有如下评分(5 分最高,没看过的不评分),我们目的是要向A 用户推荐一部电影:
协同过滤的整体思路只有两步,非常简单:寻找相似用户,推荐电影。
(1)寻找相似用户:所谓相似,其实是对于电影品味的相似,也就是说需要将A 与其他几位用户做比较,判断是不是品味相似。有很多种方法可以用来判断相似性,在本章中我们使用“欧几里德距离”来做相似性判定。当把每一部电影看成N 维空间中的一个维度,这样每个用户对于电影的评分相当于维度的坐标,那么每一个用户的所有评分,相当于就把用户固定在这个N 维空间的一个点上,然后利用欧几里德距离计算N 维空间两点的距离。距离越短说明品味越接近。本例中A 只看过两部电影(《老炮儿》和《唐人街探案》),因此只能通过这两部电影来判断品味了,那么计算A 和其他几位用户的距离,如图7-7 所示:
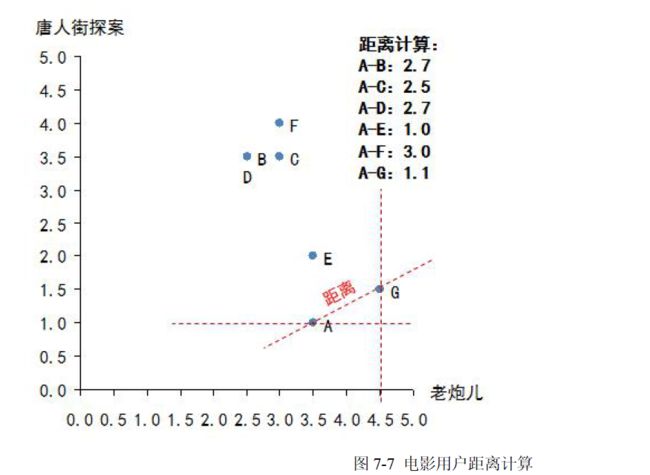
算法结果需要做一个变换,变换方法为:相似性= 1/(1+欧几里德距离),这个相似性会落在(0,1)区间内,1 表示完全品味一样,0 表示完全品味不一样。这时就可以找到哪些人的品味和A 最为接近了,计算后如下:
得到全部相似性:B-0.27,C-0.28,D-0.27,E-0.50,F-0.25,G-0.47,可见,E 的口味与A 最为接近,其次是G。
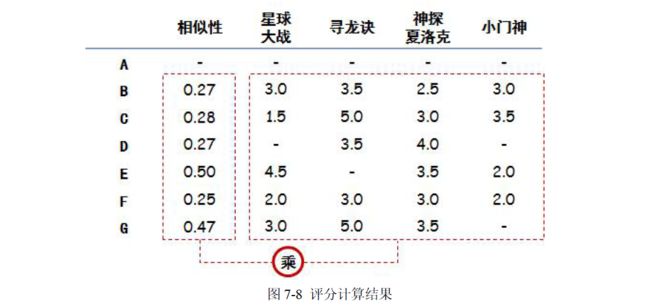
(2)推荐电影:
要做电影加权评分推荐。意思是说,品味相近的人对于电影的评价对A 选择电影来说更加重
要,具体做法可以列一个表,计算加权分,如图7-8 所示:
第六章图像分析
1.图像数据概论





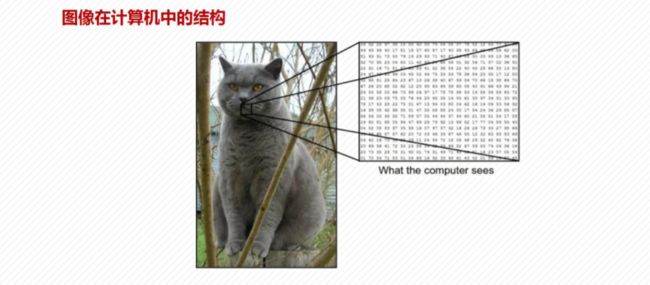


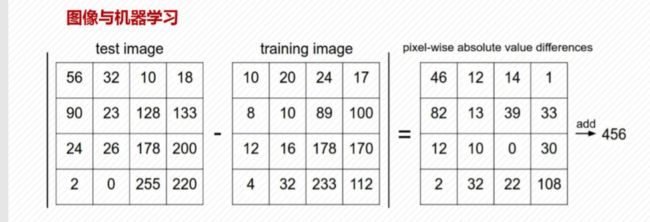






2.人脸识别













3.人脸识别与PCA




4.OpenCV入门
1.图像基本操作
数据读取-图像
- cv2.IMREAD_COLOR:彩色图像
- cv2.IMREAD_GRAYSCALE:灰度图像
import cv2 #opencv读取的格式是BGR
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
img=cv2.imread('data/cat.jpg')
img

#图像的显示,也可以创建多个窗口
cv2.imshow('image',img)
#等待时间,毫秒级,0表示任意键终止
cv2.waitKey(0)
cv2.destroyAllWindows()
def cv_show(name,img):
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
#灰度
img=cv2.imread('data/cat.jpg',cv2.IMREAD_GRAYSCALE)
img
#图像的显示,也可以创建多个窗口
cv2.imshow('image',img)
# 等待时间,毫秒级,0表示任意键终止
cv2.waitKey(10000)
cv2.destroyAllWindows()
数据读取-视频
- cv2.VideoCapture可以捕获摄像头,用数字来控制不同的设备,例如0,1。
- 如果是视频文件,直接指定好路径即可。
#vc = cv2.VideoCapture('data/test.mp4')
vc = cv2.VideoCapture(0)
检查是否打开正确
if vc.isOpened():
oepn, frame = vc.read() # open表示是否打开图片 frame表示读取到的每一帧图片
else:
open = False
while open:
ret, frame = vc.read()
print(ret,":",frame)
if frame is None:
break
if ret == True:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('result', gray)
# 0xFF == 27参考 https://blog.csdn.net/hao5119266/article/details/104173400
if cv2.waitKey(10) & 0xFF == 27:
break
vc.release()
cv2.destroyAllWindows()
截取部分图像数据
img=cv2.imread('data/cat.jpg')
cat=img[0:400,0:200]
cv_show('cat',cat)
#cv2.imshow('image',cat)
##等待时间,毫秒级,0表示任意键终止
#cv2.waitKey(0)
#cv2.destroyAllWindows()

颜色通道提取
img=cv2.merge((b,g,r))
img.shape
cv_show('cat',img)
#只保留R
cur_img = img.copy()
cur_img[:,:,0] = 0
cur_img[:,:,1] = 0
cv_show('R',cur_img)

#只保留G
cur_img = img.copy()
cur_img[:,:,0] = 0
cur_img[:,:,2] = 0
cv_show('G',cur_img)

#只保留B
cur_img = img.copy()
cur_img[:,:,1] = 0
cur_img[:,:,2] = 0
cv_show('B',cur_img)
边界填充
参数
- BORDER_REPLICATE:复制法,也就是复制最边缘像素。
- BORDER_REFLECT:反射法,对感兴趣的图像中的像素在两边进行复制例如:fedcba|abcdefgh|hgfedcb
- BORDER_REFLECT_101:反射法,也就是以最边缘像素为轴,对称,gfedcb|abcdefgh|gfedcba
- BORDER_WRAP:外包装法cdefgh|abcdefgh|abcdefg
- BORDER_CONSTANT:常量法,常数值填充。
top_size,bottom_size,left_size,right_size = (150,150,150,150)
replicate = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REPLICATE)
reflect = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_REFLECT)
reflect101 = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_REFLECT_101)
wrap = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_WRAP)
constant = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_CONSTANT, value=0)
import matplotlib.pyplot as plt
plt.subplot(231), plt.imshow(img, 'gray'), plt.title('ORIGINAL')
plt.subplot(232), plt.imshow(replicate, 'gray'), plt.title('REPLICATE')
plt.subplot(233), plt.imshow(reflect, 'gray'), plt.title('REFLECT')
plt.subplot(234), plt.imshow(reflect101, 'gray'), plt.title('REFLECT_101')
plt.subplot(235), plt.imshow(wrap, 'gray'), plt.title('WRAP')
plt.subplot(236), plt.imshow(constant, 'gray'), plt.title('CONSTANT')
plt.show()

数值计算
img_cat=cv2.imread('data/cat.jpg')
img_dog=cv2.imread('data/dog.jpg')
img_cat2= img_cat +10
img_cat[:5,:,0]
cv_show('img',img_cat)

img_cat2[:5,:,0]
cv_show('img',img_cat2)

#相当于% 256
(img_cat + img_cat2)[:5,:,0]
cv2.add(img_cat,img_cat2)[:5,:,0]

图像融合
img_dog = cv2.resize(img_dog, (500, 414))
img_dog.shape
res = cv2.addWeighted(img_cat, 0.5, img_dog, 0.5, 0)
plt.imshow(res)

res = cv2.resize(img, (0, 0), fx=4, fy=4)
plt.imshow(res)

res = cv2.resize(img, (0, 0), fx=1, fy=3)
plt.imshow(res)

2.图像处理
灰度图
import cv2 #opencv读取的格式是BGR
import numpy as np
import matplotlib.pyplot as plt#Matplotlib是RGB
%matplotlib inline
img=cv2.imread('data/cat.jpg')
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
img_gray.shape
![]()
cv2.imshow("img_gray", img_gray)
cv2.waitKey(0)
cv2.destroyAllWindows()
HSV
- H - 色调(主波长)。
- S - 饱和度(纯度/颜色的阴影)。
- V值(强度)
hsv=cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
cv2.imshow("hsv", hsv)
cv2.waitKey(0)
cv2.destroyAllWindows()
图像阈值
ret, dst = cv2.threshold(src, thresh, maxval, type)
- src: 输入图,只能输入单通道图像,通常来说为灰度图
- dst: 输出图
- thresh: 阈值
- maxval: 当像素值超过了阈值(或者小于阈值,根据type来决定),所赋予的值
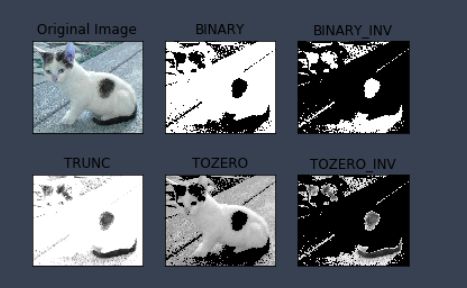
- type:二值化操作的类型,包含以下5种类型: cv2.THRESH_BINARY; cv2.THRESH_BINARY_INV; cv2.THRESH_TRUNC; cv2.THRESH_TOZERO;cv2.THRESH_TOZERO_INV
- cv2.THRESH_BINARY 超过阈值部分取maxval(最大值),否则取0
- cv2.THRESH_BINARY_INV THRESH_BINARY的反转
- cv2.THRESH_TRUNC 大于阈值部分设为阈值,否则不变
- cv2.THRESH_TOZERO 大于阈值部分不改变,否则设为0
- cv2.THRESH_TOZERO_INV THRESH_TOZERO的反转
ret, thresh1 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY)
ret, thresh2 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY_INV)
ret, thresh3 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TRUNC)
ret, thresh4 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TOZERO)
ret, thresh5 = cv2.threshold(img_gray, 127, 255, cv2.THRESH_TOZERO_INV)
titles = ['Original Image', 'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2, 3, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
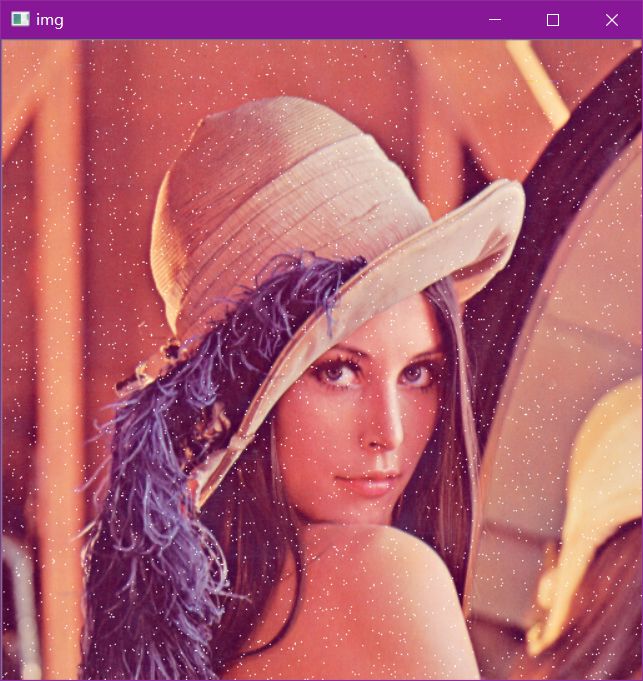
图像平滑
img = cv2.imread('data/lenaNoise.png')
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 均值滤波
# 简单的平均卷积操作
blur = cv2.blur(img, (3, 3))
cv2.imshow('blur', blur)
cv2.waitKey(0)
cv2.destroyAllWindows()

# 方框滤波
# 基本和均值一样,可以选择归一化
box = cv2.boxFilter(img,-1,(3,3), normalize=True)
cv2.imshow('box', box)
cv2.waitKey(0)
cv2.destroyAllWindows()

# 高斯滤波
# 高斯模糊的卷积核里的数值是满足高斯分布,相当于更重视中间的
aussian = cv2.GaussianBlur(img, (5, 5), 1)
cv2.imshow('aussian', aussian)
cv2.waitKey(0)
cv2.destroyAllWindows()

# 中值滤波
# 相当于用中值代替
median = cv2.medianBlur(img, 5) # 中值滤波
cv2.imshow('median', median)
cv2.waitKey(0)
cv2.destroyAllWindows()

# 展示所有的
res = np.hstack((blur,aussian,median))
#print (res)
cv2.imshow('median vs average', res)
cv2.waitKey(0)
cv2.destroyAllWindows()

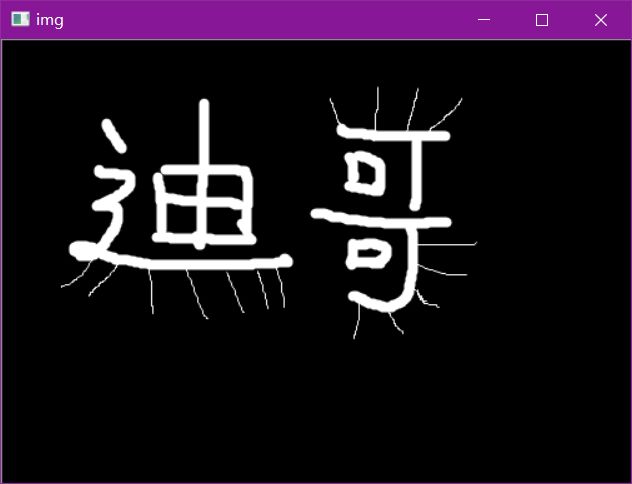
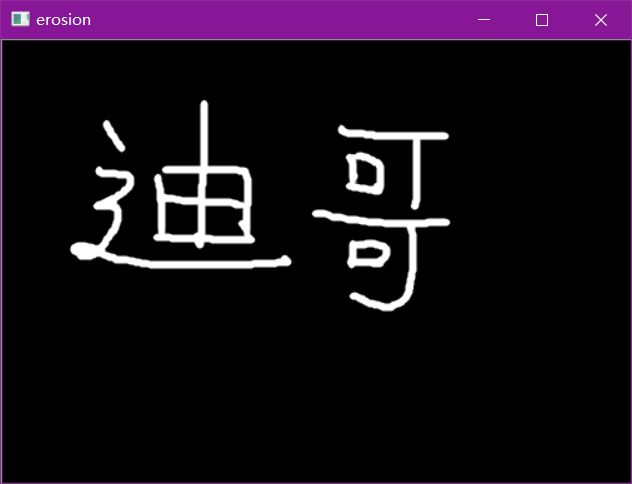
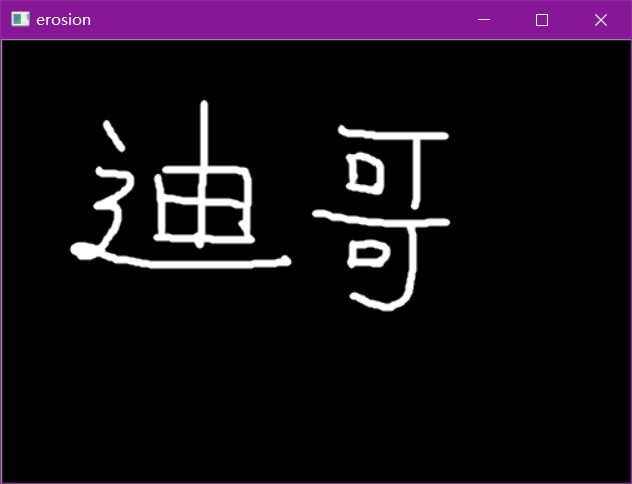
形态学-腐蚀操作
img = cv2.imread('data/dige.png')
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
kernel = np.ones((3,3),np.uint8)
erosion = cv2.erode(img,kernel,iterations = 1)
cv2.imshow('erosion', erosion)
cv2.waitKey(0)
cv2.destroyAllWindows()
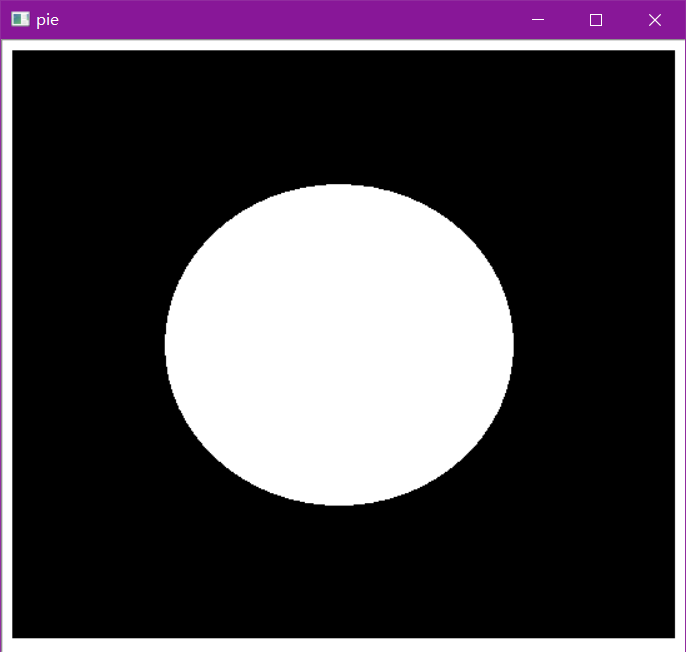
pie = cv2.imread('data/pie.png')
cv2.imshow('pie', pie)
cv2.waitKey(0)
cv2.destroyAllWindows()
kernel = np.ones((30,30),np.uint8)
erosion_1 = cv2.erode(pie,kernel,iterations = 1)
erosion_2 = cv2.erode(pie,kernel,iterations = 2)
erosion_3 = cv2.erode(pie,kernel,iterations = 3)
res = np.hstack((erosion_1,erosion_2,erosion_3))
cv2.imshow('res', res)
cv2.waitKey(0)
cv2.destroyAllWindows()

形态学-膨胀操作
img = cv2.imread('data/dige.png')
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
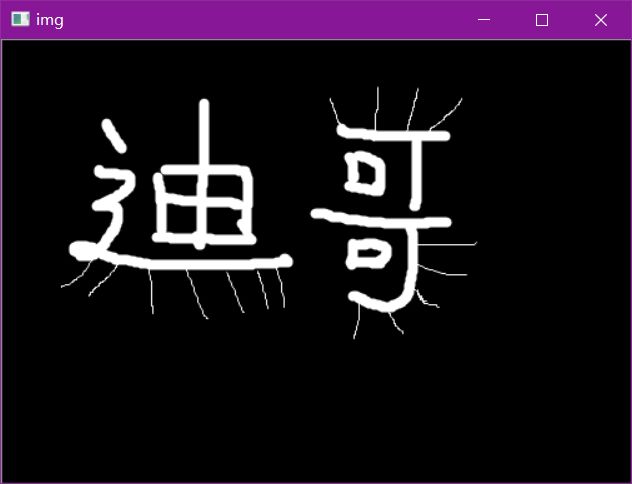
kernel = np.ones((3,3),np.uint8)
dige_dilate = cv2.dilate(dige_erosion,kernel,iterations = 1)
cv2.imshow('dilate', dige_dilate)
cv2.waitKey(0)
cv2.destroyAllWindows()
pie = cv2.imread('data/pie.png')
kernel = np.ones((30,30),np.uint8)
dilate_1 = cv2.dilate(pie,kernel,iterations = 1)
dilate_2 = cv2.dilate(pie,kernel,iterations = 2)
dilate_3 = cv2.dilate(pie,kernel,iterations = 3)
res = np.hstack((dilate_1,dilate_2,dilate_3))
cv2.imshow('res', res)
cv2.waitKey(0)
cv2.destroyAllWindows()

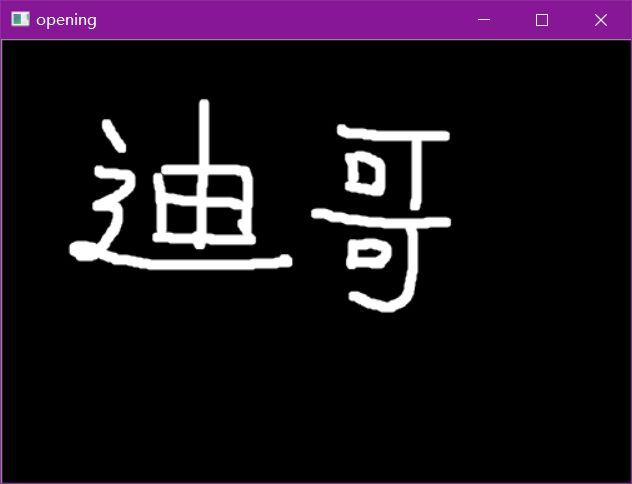
开运算与闭运算
# 开:先腐蚀,再膨胀
img = cv2.imread('data/dige.png')
kernel = np.ones((5,5),np.uint8)
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
cv2.imshow('opening', opening)
cv2.waitKey(0)
cv2.destroyAllWindows()
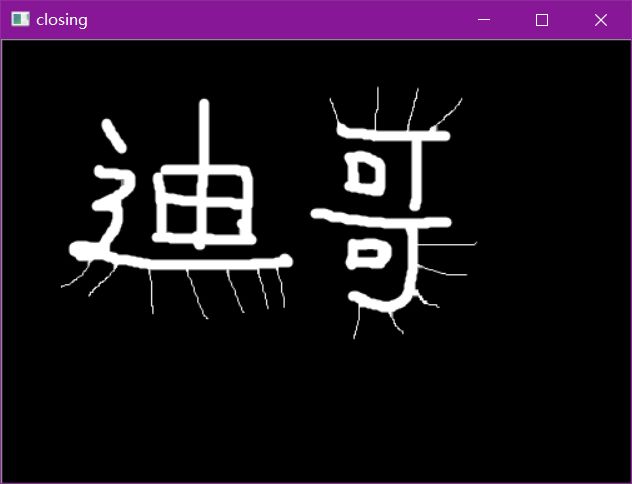
# 闭:先膨胀,再腐蚀
img = cv2.imread('data/dige.png')
kernel = np.ones((5,5),np.uint8)
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
cv2.imshow('closing', closing)
cv2.waitKey(0)
cv2.destroyAllWindows()
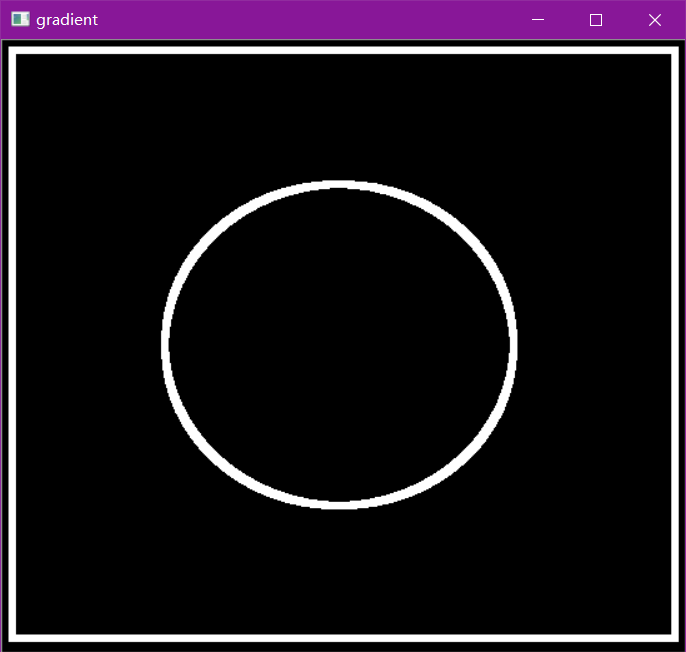
梯度运算
# 梯度=膨胀-腐蚀
pie = cv2.imread('data/pie.png')
kernel = np.ones((7,7),np.uint8)
dilate = cv2.dilate(pie,kernel,iterations = 5)
erosion = cv2.erode(pie,kernel,iterations = 5)
res = np.hstack((dilate,erosion))
cv2.imshow('res', res)
cv2.waitKey(0)
cv2.destroyAllWindows()

gradient = cv2.morphologyEx(pie, cv2.MORPH_GRADIENT, kernel)
cv2.imshow('gradient', gradient)
cv2.waitKey(0)
cv2.destroyAllWindows()
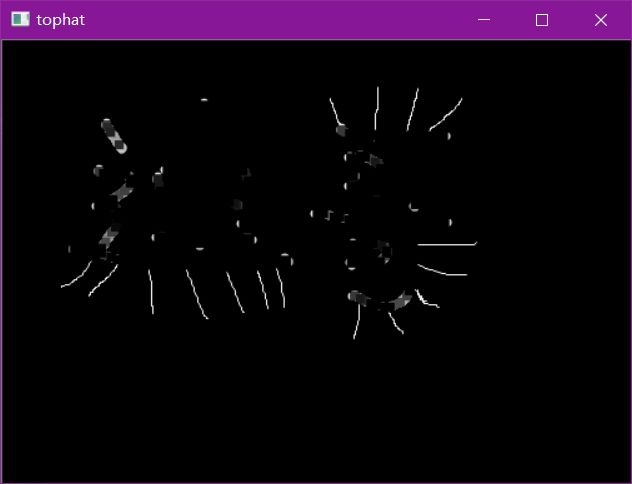
礼帽与黑帽
- 礼帽 = 原始输入-开运算结果
- 黑帽 = 闭运算-原始输入
#礼帽
img = cv2.imread('data/dige.png')
tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
cv2.imshow('tophat', tophat)
cv2.waitKey(0)
cv2.destroyAllWindows()
#黑帽
img = cv2.imread('data/dige.png')
blackhat = cv2.morphologyEx(img,cv2.MORPH_BLACKHAT, kernel)
cv2.imshow('blackhat ', blackhat )
cv2.waitKey(0)
cv2.destroyAllWindows()
3.图像梯度与轮廓
Sobel算子
如果出现负数则默认为0

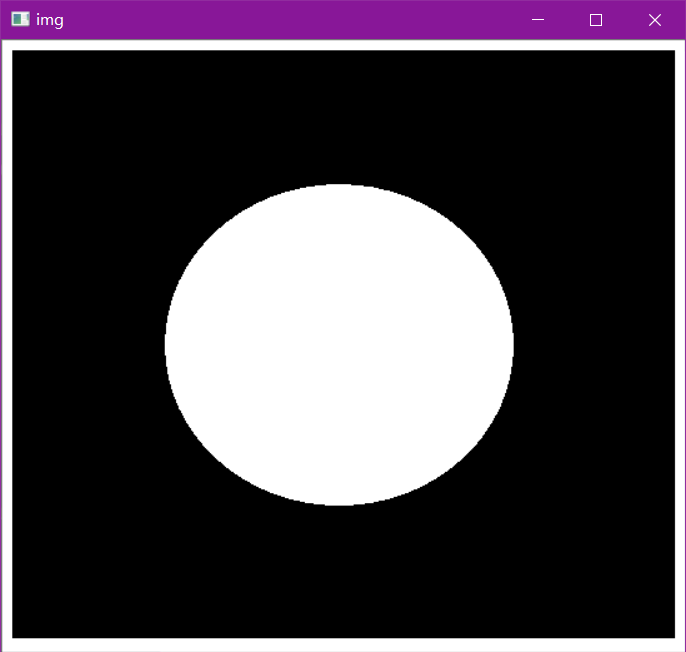
img = cv2.imread('data/pie.png',cv2.IMREAD_GRAYSCALE)
cv2.imshow("img",img)
cv2.waitKey()
cv2.destroyAllWindows()
dst = cv2.Sobel(src, ddepth, dx, dy, ksize)
- ddepth:图像的深度
- dx和dy分别表示水平和竖直方向
- ksize是Sobel算子的大小
#定义显示函数
def cv_show(img,name):
cv2.imshow(name,img)
cv2.waitKey()
cv2.destroyAllWindows()
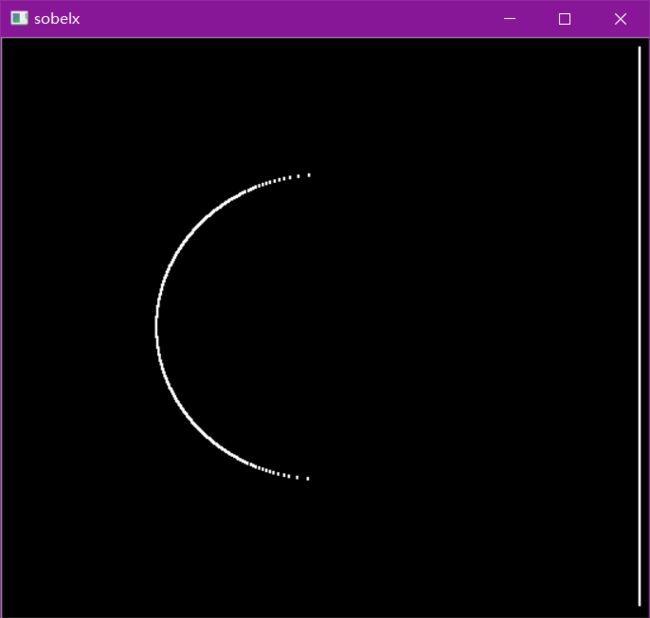
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3)
cv_show(sobelx,'sobelx')
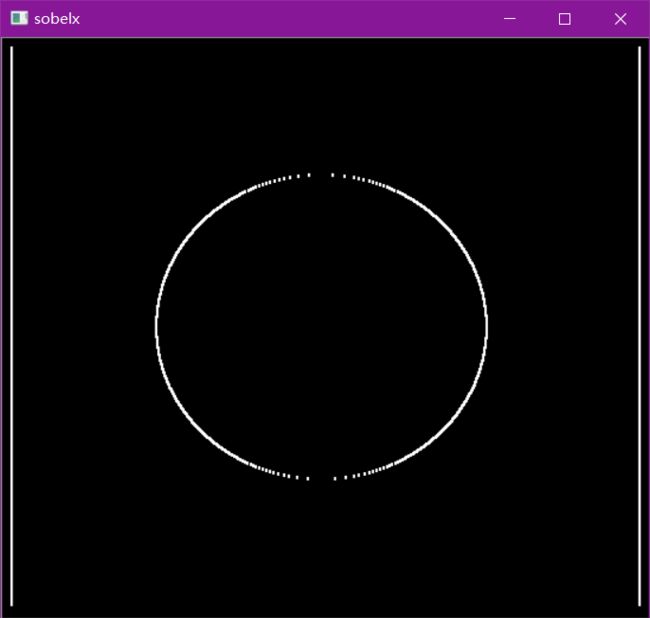
白到黑是正数,黑到白就是负数了,所有的负数会被截断成0,所以要取绝对值
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3)
sobelx = cv2.convertScaleAbs(sobelx)
cv_show(sobelx,'sobelx')
#倒过来
sobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=3)
sobely = cv2.convertScaleAbs(sobely)
cv_show(sobely,'sobely')
#分别计算x和y,再求和
sobelxy = cv2.addWeighted(sobelx,0.5,sobely,0.5,0)
cv_show(sobelxy,'sobelxy')
不建议直接计算
sobelxy=cv2.Sobel(img,cv2.CV_64F,1,1,ksize=3)
sobelxy = cv2.convertScaleAbs(sobelxy)
cv_show(sobelxy,'sobelxy')
根据梯度求边缘
img = cv2.imread('data/lena.jpg',cv2.IMREAD_GRAYSCALE)
cv_show(img,'img')
img = cv2.imread('lena.jpg',cv2.IMREAD_GRAYSCALE)
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3)
sobelx = cv2.convertScaleAbs(sobelx)
sobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=3)
sobely = cv2.convertScaleAbs(sobely)
sobelxy = cv2.addWeighted(sobelx,0.5,sobely,0.5,0)
cv_show(sobelxy,'sobelxy')

Scharr算子
对边界更敏感

laplacian算子
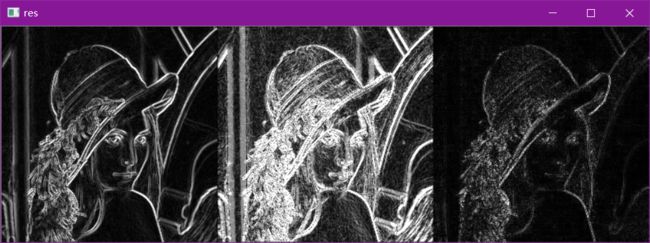
特别敏感,对噪声点也很敏感
#不同算子的差异
img = cv2.imread('data/lena.jpg',cv2.IMREAD_GRAYSCALE)
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3)
sobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=3)
sobelx = cv2.convertScaleAbs(sobelx)
sobely = cv2.convertScaleAbs(sobely)
sobelxy = cv2.addWeighted(sobelx,0.5,sobely,0.5,0)
scharrx = cv2.Scharr(img,cv2.CV_64F,1,0)
scharry = cv2.Scharr(img,cv2.CV_64F,0,1)
scharrx = cv2.convertScaleAbs(scharrx)
scharry = cv2.convertScaleAbs(scharry)
scharrxy = cv2.addWeighted(scharrx,0.5,scharry,0.5,0)
laplacian = cv2.Laplacian(img,cv2.CV_64F)
laplacian = cv2.convertScaleAbs(laplacian)
res = np.hstack((sobelxy,scharrxy,laplacian))
cv_show(res,'res')
Canny边缘检测
-
- 使用高斯滤波器,以平滑图像,滤除噪声。
-
- 计算图像中每个像素点的梯度强度和方向。
-
- 应用非极大值(Non-Maximum Suppression)抑制,以消除边缘检测带来的杂散响应。
-
- 应用双阈值(Double-Threshold)检测来确定真实的和潜在的边缘。
-
- 通过抑制孤立的弱边缘最终完成边缘检测。
1:高斯滤波器

2:梯度和方向
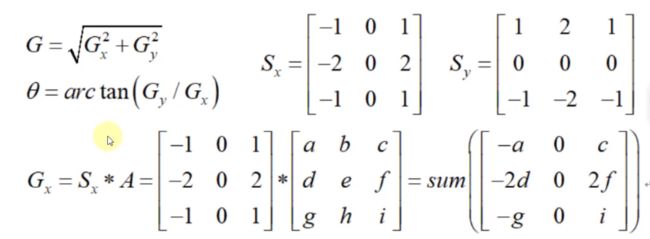
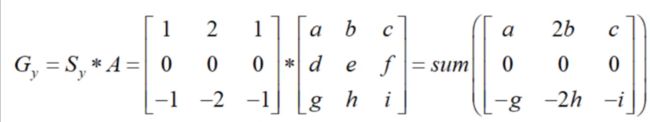
3:非极大值抑制

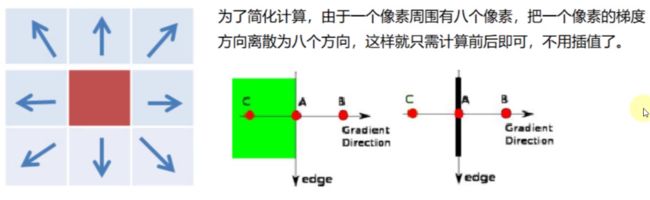
4:双阈值检测

img=cv2.imread("data/lena.jpg",cv2.IMREAD_GRAYSCALE)
v1=cv2.Canny(img,80,150)
v2=cv2.Canny(img,50,100)
res = np.hstack((v1,v2))
cv_show(res,'res')

img=cv2.imread("data/car.png",cv2.IMREAD_GRAYSCALE)
v1=cv2.Canny(img,120,250)
v2=cv2.Canny(img,50,100)
res = np.hstack((v1,v2))
cv_show(res,'res')

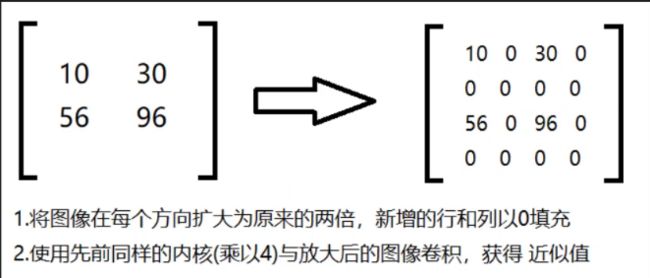
图像金字塔
- 高斯金字塔
- 拉普拉斯金字塔
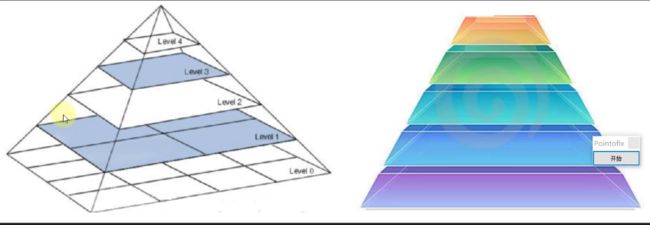
高斯金字塔:向下采样方法(缩小)
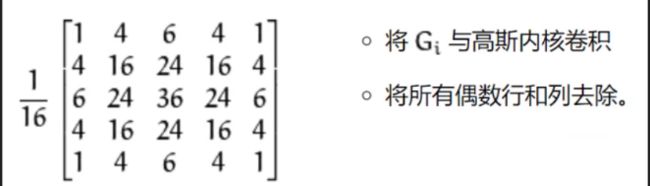
高斯金字塔:向上采样方法(放大)
img=cv2.imread("data/AM.png")
cv_show(img,'img')
print (img.shape)
#打印结果(442, 340, 3)

up=cv2.pyrUp(img)
cv_show(up,'up')
print (up.shape)
#打印结果(884, 680, 3)

down=cv2.pyrDown(img)
cv_show(down,'down')
print (down.shape)
#打印结果(221, 170, 3)

up2=cv2.pyrUp(up)
cv_show(up2,'up2')
print (up2.shape)
#打印结果(1768, 1360, 3)
图片太大不展示了
up=cv2.pyrUp(img)
up_down=cv2.pyrDown(up)
cv_show(up_down,'up_down')

cv_show(np.hstack((img,up_down)),'up_down')

up=cv2.pyrUp(img)
up_down=cv2.pyrDown(up)
cv_show(img-up_down,'img-up_down')

拉普拉斯金字塔
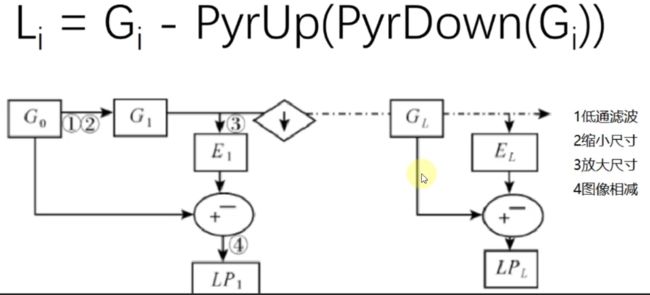
down=cv2.pyrDown(img)
down_up=cv2.pyrUp(down)
l_1=img-down_up
cv_show(l_1,'l_1')

图像轮廓
cv2.findContours(img,mode,method)
mode:轮廓检索模式
- RETR_EXTERNAL :只检索最外面的轮廓;
- RETR_LIST:检索所有的轮廓,并将其保存到一条链表当中;
- RETR_CCOMP:检索所有的轮廓,并将他们组织为两层:顶层是各部分的外部边界,第二层是空洞的边界;
- RETR_TREE:检索所有的轮廓,并重构嵌套轮廓的整个层次;
method:轮廓逼近方法
- CHAIN_APPROX_NONE:以Freeman链码的方式输出轮廓,所有其他方法输出多边形(顶点的序列)。
- CHAIN_APPROX_SIMPLE:压缩水平的、垂直的和斜的部分,也就是,函数只保留他们的终点部分。
为了更高的准确率,使用二值图像。

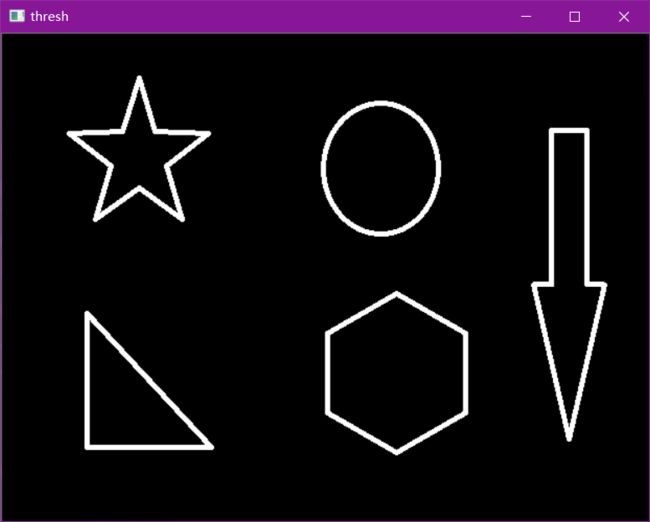
img = cv2.imread('data/contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
cv_show(thresh,'thresh')
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cv_show(img,'img')
#传入绘制图像,轮廓,轮廓索引,颜色模式,线条厚度
# 注意需要copy,要不原图会变。。。
draw_img = img.copy()
res = cv2.drawContours(draw_img, contours, -1, (0, 0, 255), 2)
cv_show(res,'res')

draw_img = img.copy()
res = cv2.drawContours(draw_img, contours, 0, (0, 0, 255), 2)
cv_show(res,'res')

轮廓特征
cnt = contours[0]
#面积
print(cv2.contourArea(cnt))
#周长,True表示闭合的
print(cv2.arcLength(cnt,True))
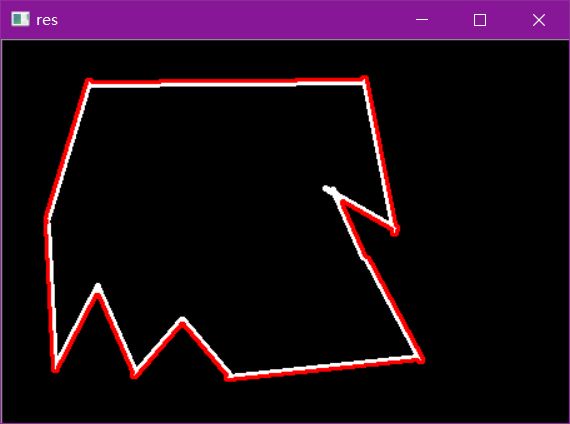
轮廓近似
img = cv2.imread('data/contours2.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]
draw_img = img.copy()
res = cv2.drawContours(draw_img, [cnt], -1, (0, 0, 255), 2)
cv_show(res,'res')
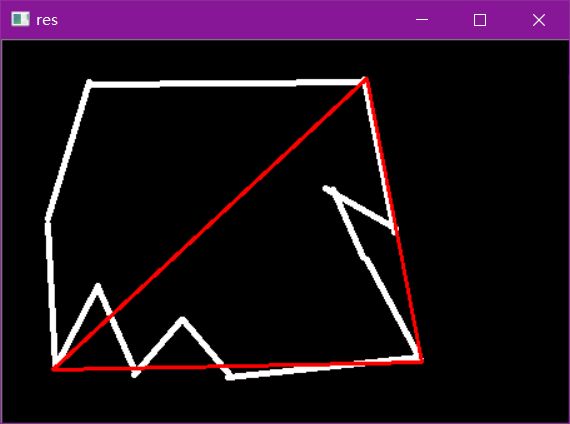
epsilon = 0.15*cv2.arcLength(cnt,True)
approx = cv2.approxPolyDP(cnt,epsilon,True)
draw_img = img.copy()
res = cv2.drawContours(draw_img, [approx], -1, (0, 0, 255), 2)
cv_show(res,'res')
边界矩形
img = cv2.imread('data/contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]
x,y,w,h = cv2.boundingRect(cnt)
img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
cv_show(img,'img')
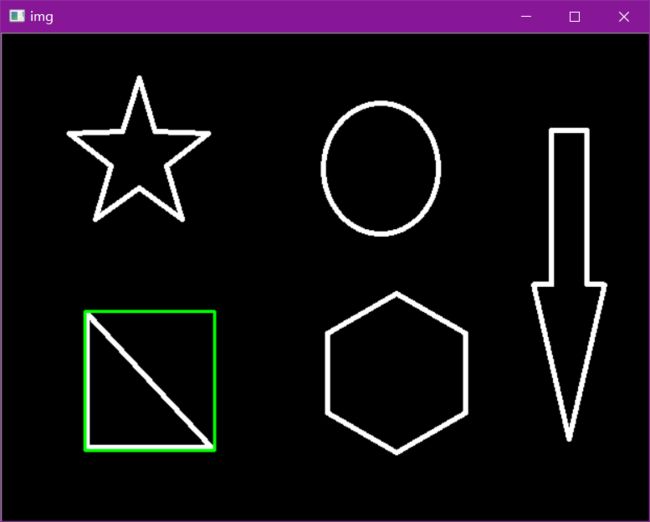
area = cv2.contourArea(cnt)
x, y, w, h = cv2.boundingRect(cnt)
rect_area = w * h
extent = float(area) / rect_area
print ('轮廓面积与边界矩形比',extent)
轮廓面积与边界矩形比 0.5154317244724715
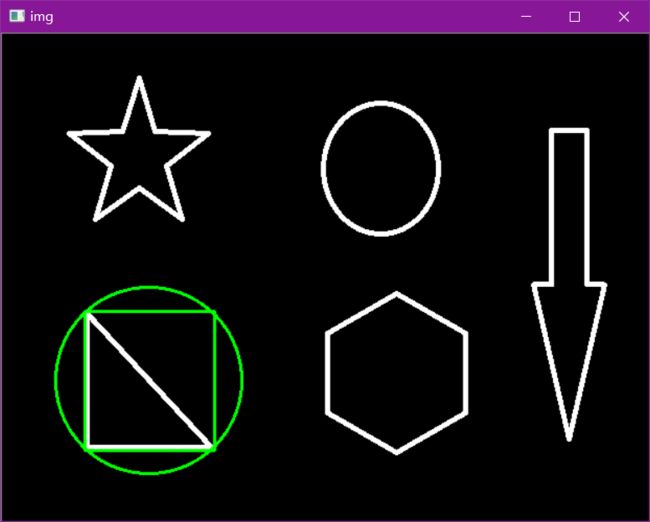
外接圆
(x,y),radius = cv2.minEnclosingCircle(cnt)
center = (int(x),int(y))
radius = int(radius)
img = cv2.circle(img,center,radius,(0,255,0),2)
cv_show(img,'img')
傅里叶变换
我们生活在时间的世界中,早上7:00起来吃早饭,8:00去挤地铁,9:00开始上班。。。以时间为参照就是时域分析。
但是在频域中一切都是静止的!
https://zhuanlan.zhihu.com/p/19763358
傅里叶变换的作用
- 高频:变化剧烈的灰度分量,例如边界
- 低频:变化缓慢的灰度分量,例如一片大海
滤波
-
低通滤波器:只保留低频,会使得图像模糊
-
高通滤波器:只保留高频,会使得图像细节增强
-
opencv中主要就是cv2.dft()和cv2.idft(),输入图像需要先转换成np.float32 格式。
-
得到的结果中频率为0的部分会在左上角,通常要转换到中心位置,可以通过shift变换来实现。
-
cv2.dft()返回的结果是双通道的(实部,虚部),通常还需要转换成图像格式才能展示(0,255)。
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('data/lena.jpg',0)
img_float32 = np.float32(img)
dft = cv2.dft(img_float32, flags = cv2.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)
# 得到灰度图能表示的形式
magnitude_spectrum = 20*np.log(cv2.magnitude(dft_shift[:,:,0],dft_shift[:,:,1]))
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()

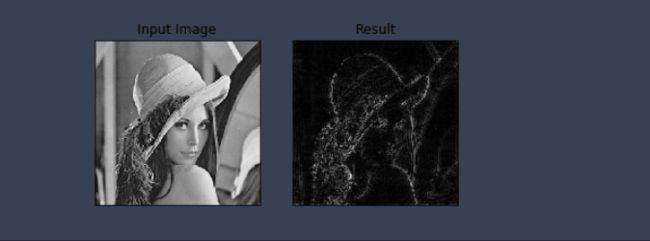
img = cv2.imread('data/lena.jpg',0)
img_float32 = np.float32(img)
dft = cv2.dft(img_float32, flags = cv2.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)
rows, cols = img.shape
crow, ccol = int(rows/2) , int(cols/2) # 中心位置
# 高通滤波
mask = np.ones((rows, cols, 2), np.uint8)
mask[crow-30:crow+30, ccol-30:ccol+30] = 0
# IDFT
fshift = dft_shift*mask
f_ishift = np.fft.ifftshift(fshift)
img_back = cv2.idft(f_ishift)
img_back = cv2.magnitude(img_back[:,:,0],img_back[:,:,1])
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img_back, cmap = 'gray')
plt.title('Result'), plt.xticks([]), plt.yticks([])
plt.show()
4.直方图与模板匹配
import cv2 #opencv读取的格式是BGR
import numpy as np
import matplotlib.pyplot as plt#Matplotlib是RGB
%matplotlib inline
def cv_show(img,name):
cv2.imshow(name,img)
cv2.waitKey()
cv2.destroyAllWindows()
直方图
cv2.calcHist(images,channels,mask,histSize,ranges)
- images: 原图像图像格式为 uint8 或 float32。当传入函数时应 用中括号 [] 括来例如[img]
- channels: 同样用中括号括来它会告函数我们统幅图 像的直方图。如果入图像是灰度图它的值就是 [0]如果是彩色图像 的传入的参数可以是 [0][1][2] 它们分别对应着 BGR。
- mask: 掩模图像。统整幅图像的直方图就把它为 None。但是如 果你想统图像某一分的直方图的你就制作一个掩模图像并 使用它。
- histSize:BIN 的数目。也应用中括号括来
- ranges: 像素值范围常为 [0-256]
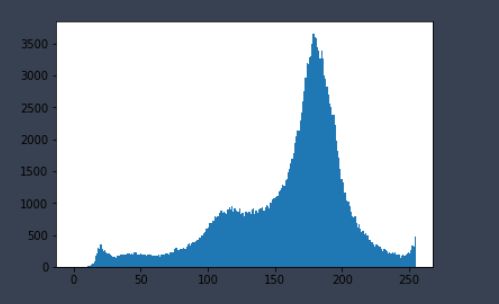
img = cv2.imread('data/cat.jpg',0) #0表示灰度图
hist = cv2.calcHist([img],[0],None,[256],[0,256])
hist.shape

plt.hist(img.ravel(),256);
plt.show()
img = cv2.imread('data/cat.jpg')
color = ('b','g','r')
for i,col in enumerate(color):
histr = cv2.calcHist([img],[i],None,[256],[0,256])
plt.plot(histr,color = col)
plt.xlim([0,256])
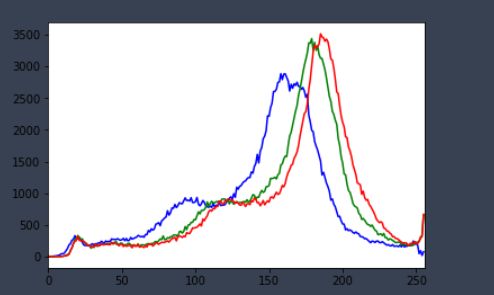
mask操作
# 创建mast
mask = np.zeros(img.shape[:2], np.uint8)
print (mask.shape)
mask[100:300, 100:400] = 255
cv_show(mask,'mask')

img = cv2.imread('data/cat.jpg', 0)
cv_show(img,'img')
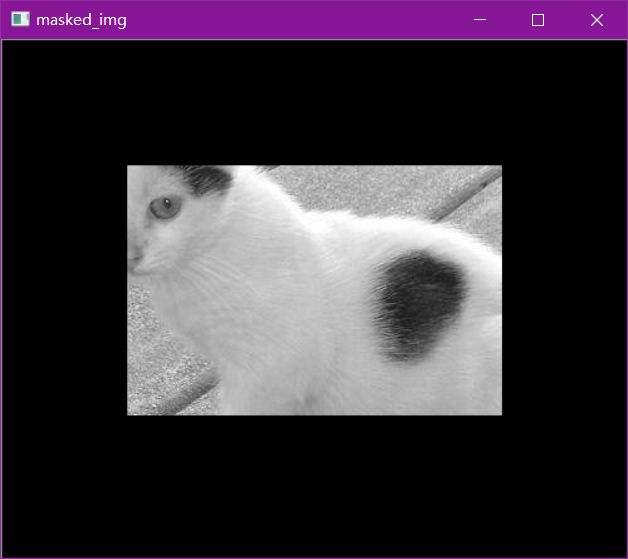
masked_img = cv2.bitwise_and(img, img, mask=mask)#与操作
cv_show(masked_img,'masked_img')
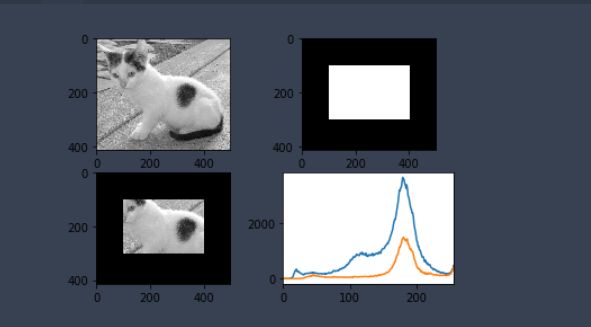
hist_full = cv2.calcHist([img], [0], None, [256], [0, 256])
hist_mask = cv2.calcHist([img], [0], mask, [256], [0, 256])
plt.subplot(221), plt.imshow(img, 'gray')
plt.subplot(222), plt.imshow(mask, 'gray')
plt.subplot(223), plt.imshow(masked_img, 'gray')
plt.subplot(224), plt.plot(hist_full), plt.plot(hist_mask)
plt.xlim([0, 256])
plt.show()
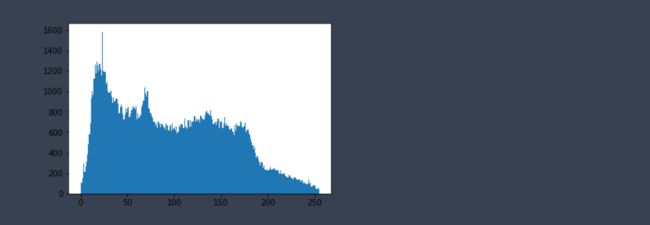
直方图均衡化
img = cv2.imread('data/clahe.jpg',0) #0表示灰度图 #clahe
plt.hist(img.ravel(),256);
plt.show()
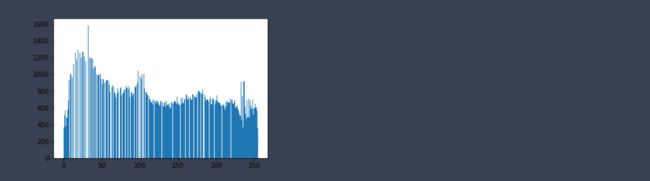
equ = cv2.equalizeHist(img)
plt.hist(equ.ravel(),256)
plt.show()
res = np.hstack((img,equ))
cv_show(res,'res')

自适应直方图均衡化
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
res_clahe = clahe.apply(img)
res = np.hstack((img,equ,res_clahe))
cv_show(res,'res')

模板匹配
模板匹配和卷积原理很像,模板在原图像上从原点开始滑动,计算模板与(图像被模板覆盖的地方)的差别程度,这个差别程度的计算方法在opencv里有6种,然后将每次计算的结果放入一个矩阵里,作为结果输出。假如原图形是AxB大小,而模板是axb大小,则输出结果的矩阵是(A-a+1)x(B-b+1)
import cv2
# 模板匹配
img = cv2.imread('data/lena.jpg', 0)
template = cv2.imread('data/face.jpg', 0)
h, w = template.shape[:2]
img.shapep

template.shape

-
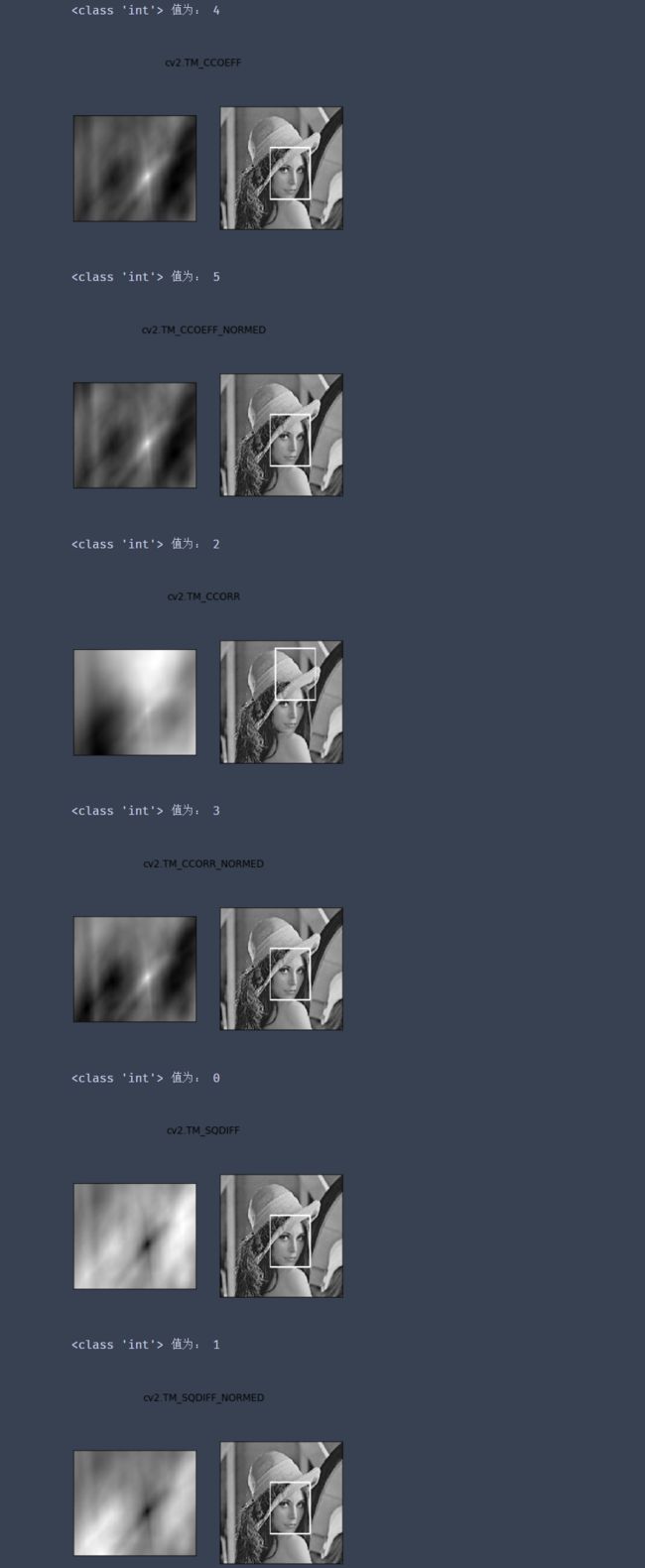
TM_SQDIFF:计算平方不同,计算出来的值越小,越相关
-
TM_CCORR:计算相关性,计算出来的值越大,越相关
-
TM_CCOEFF:计算相关系数,计算出来的值越大,越相关
-
TM_SQDIFF_NORMED:计算归一化平方不同,计算出来的值越接近0,越相关
-
TM_CCORR_NORMED:计算归一化相关性,计算出来的值越接近1,越相关
-
TM_CCOEFF_NORMED:计算归一化相关系数,计算出来的值越接近1,越相关
公式:https://docs.opencv.org/3.3.1/df/dfb/group__imgproc__object.html#ga3a7850640f1fe1f58fe91a2d7583695d
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
res = cv2.matchTemplate(img, template, cv2.TM_SQDIFF)
res.shape

min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
min_val

max_val

min_loc

max_loc

for meth in methods:
img2 = img.copy()
# 匹配方法的真值
method = eval(meth)
print(type(method),"值为:",method)
# print (method)
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# 如果是平方差匹配TM_SQDIFF或归一化平方差匹配TM_SQDIFF_NORMED,取最小值
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
# 画矩形
cv2.rectangle(img2, top_left, bottom_right, 255, 2)
plt.subplot(121), plt.imshow(res, cmap='gray')
plt.xticks([]), plt.yticks([]) # 隐藏坐标轴
plt.subplot(122), plt.imshow(img2, cmap='gray')
plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show()
匹配多个对象
img_rgb = cv2.imread('data/mario.jpg')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('data/mario_coin.jpg', 0)
h, w = template.shape[:2]
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
threshold = 0.8
# 取匹配程度大于%80的坐标
loc = np.where(res >= threshold)
print(loc)
print(loc[0].size)
for pt in zip(*loc[::-1]): # *号表示可选参数
bottom_right = (pt[0] + w, pt[1] + h)
cv2.rectangle(img_rgb, pt, bottom_right, (0, 0, 255), 2)
cv2.imshow('img_rgb', img_rgb)
cv2.waitKey(0)
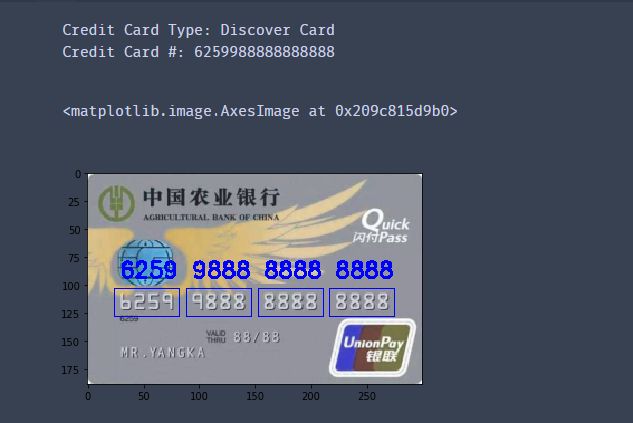
5.银行卡识别案例
# 导入工具包
# opencv读取图片的格式为b g r
# matplotlib图片的格式为 r g b
import numpy as np
import cv2
from imutils import contours
import matplotlib.pyplot as plt
%matplotlib inline
1.前期准备
# 信用卡的位置
predict_card = "data/nongye.png"
# 模板的位置
template = "data/jianshedemo.png"
# 指定信用卡类型
FIRST_NUMBER = {
"3": "American Express",
"4": "Visa",
"5": "MasterCard",
"6": "Discover Card",
"7":"中国建设银行"
}
# 定义一些功能函数
# 对框进行排序
def sort_contours(cnts, method="left-to-right"):
reverse = False
i = 0
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
if method == "top-to-bottom" or method == "bottom-to-top":
i = 1
boundingBoxes = [cv2.boundingRect(c) for c in cnts] #用一个最小的矩形,把找到的形状包起来x,y,h,w
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b: b[1][i], reverse=reverse))
return cnts, boundingBoxes
# 调整图片尺寸大小
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter)
return resized
# 定义cv2展示函数
def cv_show(name,img):
cv2.imshow(name,img)
cv2.waitKey(0)
cv2.destroyAllWindows()
2.对模板图像进行预处理操作
# 读取模板图像
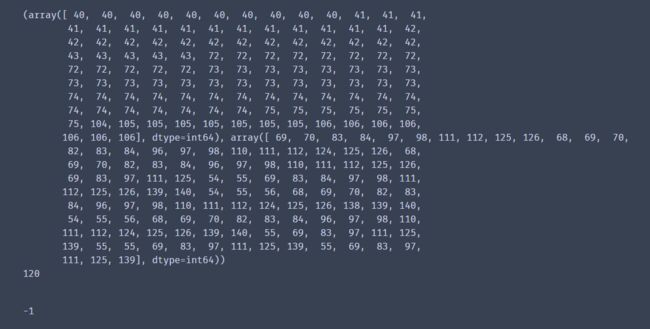
img = cv2.imread(template)
cv_show("img",img)
plt.imshow(img)
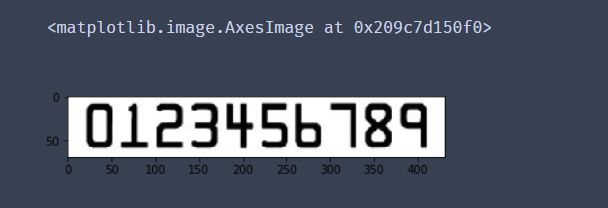
# 转灰度图
ref = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cv_show("ref",ref)
plt.imshow(ref)
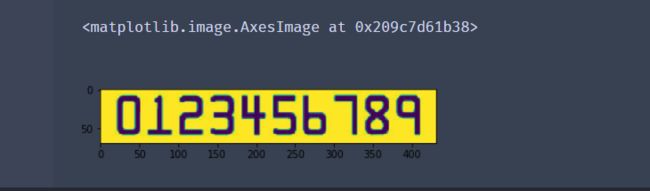
#转化为二值图
ref = cv2.threshold(ref,10,255,cv2.THRESH_BINARY_INV)[1]
cv_show("ref",ref)
plt.imshow(ref)
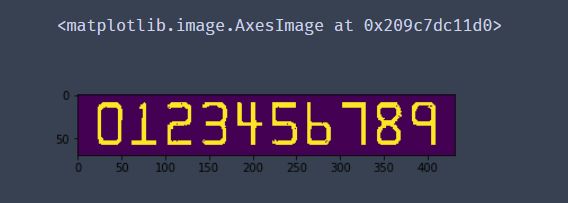
#cv2.findContours()函数接受的参数为二值图,即黑白的(不是灰度图),cv2.RETR_EXTERNAL只检测外轮廓,cv2.CHAIN_APPROX_SIMPLE只保留终点坐标
#返回的list中每个元素都是图像中的一个轮廓
# 在二值化后的图像中计算轮廓
ref,refCnts,hierarchy = cv2.findContours(ref.copy(),cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
# 在原图上画出轮廓
cv2.drawContours(img,refCnts,-1,(0,0,255),3)
cv_show("img",img)
plt.imshow(img)
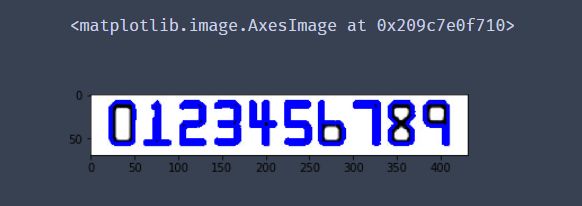
print(np.array(refCnts).shape)
# 排序,从左到右,从上到下
refCnts = sort_contours(refCnts,method="left-to-right")[0]
digits = {}
# 遍历每一个轮廓
for (i, c) in enumerate(refCnts):
# 计算外接矩形并且resize成合适大小
(x, y, w, h) = cv2.boundingRect(c)
roi = ref[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88))
# 每一个数字对应每一个模板
digits[i] = roi
3.对信用卡进行处理
# 初始化卷积核
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
# 读取信用卡
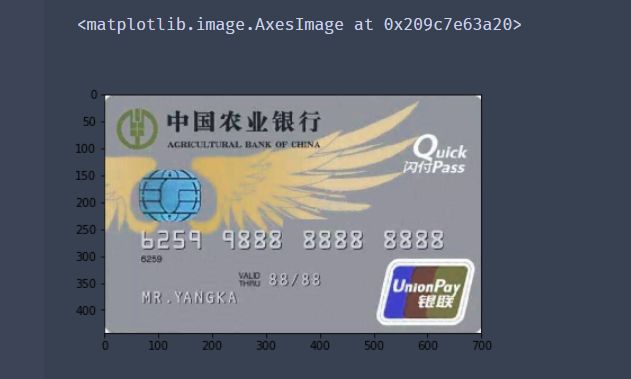
image = cv2.imread(predict_card)
cv_show("image",image)
plt.imshow(image)
# 对图像进行预处理操作
# 先对图像进行resize操作
image = resize(image,width=300)
# 灰度化处理
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
cv_show("gray",gray)
plt.imshow(gray)

# 对图像礼帽操作
# 礼帽 = 原始输入-开运算结果
# 开运算:先腐蚀,再膨胀
# 突出更明亮的区域
tophat = cv2.morphologyEx(gray,cv2.MORPH_TOPHAT,rectKernel)
cv_show("tophat",tophat)
plt.imshow(tophat)

# 用Sobel算子边缘检测
gradX = cv2.Sobel(tophat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1)
gradX = np.absolute(gradX)
(minVal, maxVal) = (np.min(gradX), np.max(gradX))
gradX = (255 * ((gradX - minVal) / (maxVal - minVal)))
gradX = gradX.astype("uint8")
print (np.array(gradX).shape)
cv_show("gradX",gradX)
plt.imshow(gradX)
# 对图像闭操作
# 闭操作:先膨胀,再腐蚀
# 可以将数字连在一起
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)
cv_show("gradX",gradX)
plt.imshow(gradX)
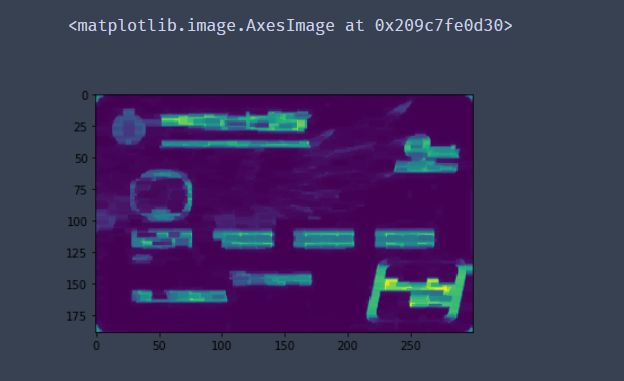
#THRESH_OTSU会自动寻找合适的阈值,适合双峰,需把阈值参数设置为0
thresh = cv2.threshold(gradX, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show("thresh",thresh)
plt.imshow(thresh)
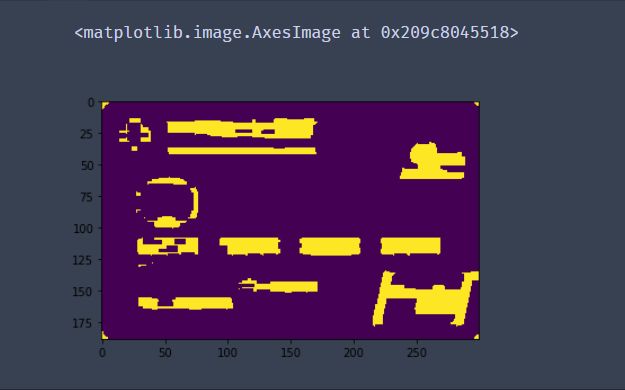
# 再进行一次闭操作
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel) #再来一个闭操作
cv_show("thresh",thresh)
plt.imshow(thresh)
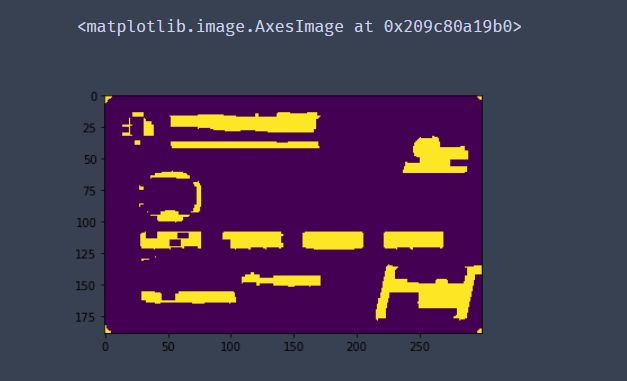
# 计算轮廓
nouse,threshCnts, hierarchy = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
cnts = threshCnts
cur_img = image.copy()
cv2.drawContours(cur_img,cnts,-1,(0,0,255),3)
cv_show("img",cur_img)
plt.imshow(cur_img)
# print(cnts)

locs = []
# 遍历轮廓
for (i, c) in enumerate(cnts):
# 计算矩形
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
# 选择合适的区域,根据实际任务来,这里的基本都是四个数字一组
if ar > 2.5 and ar < 4.0:
# print(ar,x,y,w,h)
if (w > 20 and w < 55) and (h > 10 and h < 30):
#符合的留下来
locs.append((x, y, w, h))
print(x,y,w,h)
# 将符合的轮廓从左到右排序
locs = sorted(locs, key=lambda x:x[0])
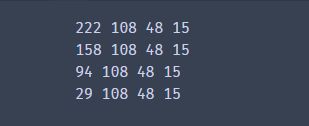
output = []
# 模板匹配
# 遍历每一个轮廓中的数字
for (i, (gX, gY, gW, gH)) in enumerate(locs):
# initialize the list of group digits
groupOutput = []
# 根据坐标提取每一个组
group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5]
cv_show("group",group)
# 预处理
group = cv2.threshold(group, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show("group",group)
# 计算每一组的轮廓
_,digitCnts,hierarchy = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
digitCnts = contours.sort_contours(digitCnts,method="left-to-right")[0]
# 计算每一组中的每一个数值
for c in digitCnts:
# 找到当前数值的轮廓,resize成合适的的大小
(x, y, w, h) = cv2.boundingRect(c)
roi = group[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88))
cv_show("roi",roi)
# 计算匹配得分
scores = []
# 在模板中计算每一个得分
for (digit, digitROI) in digits.items():
# 模板匹配
result = cv2.matchTemplate(roi, digitROI,cv2.TM_CCOEFF)
(_, score, _, _) = cv2.minMaxLoc(result)
scores.append(score)
# 得到最合适的数字
groupOutput.append(str(np.argmax(scores)))
# 画出来
cv2.rectangle(image, (gX - 5, gY - 5),(gX + gW + 5, gY + gH + 5), (0, 0, 255), 1)
cv2.putText(image, "".join(groupOutput), (gX, gY - 15),cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)
# 得到结果
output.extend(groupOutput)
# 打印结果
print("Credit Card Type: {}".format(FIRST_NUMBER[output[0]]))
print("Credit Card #: {}".format("".join(output)))
cv_show("Image",image)
plt.imshow(image)