把以前写的爬虫代码整理成教程,方便以后查阅,可以爬点感兴趣的东西玩一玩。
1.运行环境及安装:
1.运行环境
默认读者已经掌握了python2/3的基本操作。
操作系统:win7
IDE:Anaconda3 (32-bit)中的jupyter notebook(Anaconda3中对应的是python3,用python2也无妨,推荐用python3)
用到的python库:BeautifulSoup(一个可以从HTML或XML中提取数据的python库),requests(rllib的升级版,打包了全部功能并简化了使用方法)
浏览器:Google Chrome
2.Anaconda3 安装
Anaconda是一个用于科学计算的Python发行版,支持 Linux, Mac, Windows系统,提供了包管理与环境管理的功能,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题。
登陆Anaconda官网下载相应版本并安装:https://www.continuum.io/downloads/
常用的库numpy,pandas等都集成在了Anaconda里,本教程用的BeautifulSoup也包含在内。
安装完成后,点击开始菜单,找到Anaconda文件夹中的jupyter notebook,打开。
jupyter notebook是一个在浏览器中运行的IDE,访问本地文件。当然,用其他的IDE也可以,这里推荐用notebook。
5分钟可快速入门notebook,简明教程请移步http://codingpy.com/article/getting-started-with-jupyter-notebook-part-1/。
开搞!
2.爬取网页中链接对应的网址
我们要爬取的内容为赶集网二手手机交易页面中每个商品的详细信息,网址为:http://bj.ganji.com/shouji/a2/。
我们的思路是这样的:首先获得每个商品对应的链接,然后进入这个链接,爬取商品信息。
1.解析网页元素
因为我们要获得图1中每个商品的链接,需要解析网页元素。因为是入门教程,所以不会涉猎太多HTML的知识。
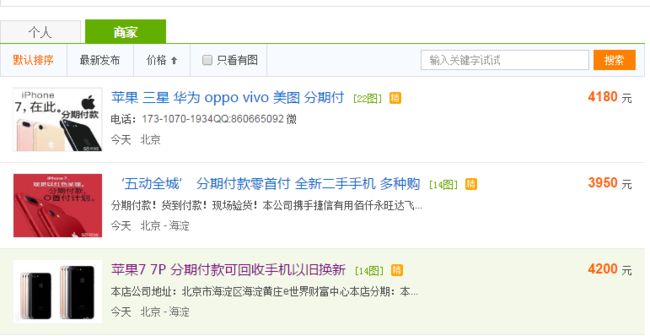
对着图1中第1个商品“苹果三星华为……”右击,选择“检查”,在浏览器右侧会弹出图2所示的窗口:

红色箭头指向的那一行表示层级关系,从开始的html字段开始,一直定位到a.ft-tit字段,最终定位到商品所在的网页源码的位置,即我们想要找的元素。参考这个层级关系,我们可以自己定位任意想要的元素(编程时会用到)。
例如,现在要手动定位第1个商品:
1. 点击图2任意空白部分(保证该窗口为当前活动窗口),按下键盘上的Ctrl+F,会在图2中的侧边栏的中间部分弹出一个搜索框,如蓝色箭头所指。
2. 在搜索框中输入红色箭头所指的层级字段,中间以“>”相连,即:html>body>#wrapper>div>div>dl>dd.feature>div.ft-db>ul>li.js-item>a.ft-tit
。第1个商品所在字段自动加上了底纹。
3. 搜索框右侧的“1 of 70”表示与此定位同级的位置一共有70个,现在是第1个,也就我们要定位的第1个商品。可以通过搜索框右侧的上/下箭头选择同级的定位,比如下一个商品为“五动全城……”,可见我们定位的字段正是我们想要的。
显然,在底纹字段中,我们想要爬取的正是下面这个链接:
“http://bj.ganji.com/shouji/29130462136655x.htm
2.提取网页元素
首先,引入我们要用到的python库:
from bs4 import BeautifulSoup
import requests
爬取链接:
#目标网址
url = 'http://bj.ganji.com/shouji/a2/'
#请求访问目标网址
wb_data = requests.get(url)
#用lxml解析目标网址
soup = BeautifulSoup(wb_data.text,'lxml')
#定位到我们要爬取的信息,返回一个列表(注意每个“>”前后都有空格)
links = soup.select('html > body > #wrapper > div > div > dl > dd.feature > div.ft-db > ul > li.js-item > a.ft-tit')
#在每个商品的源码中,筛选出我们想要的链接,存放到列表link_list 中
link_list = []
for each_link in links:
link_list.append(each_link.get('href'))
在上面的代码中,我们用requests的get方法去访问目标网址,返回数据到wb_data中,然后用BeautifulSoup方法用lxml来解析wb_data,以便可以提取我们想要的信息。select方法返回所有满足定位要求的源码段到一个列表中,一共是70个,对应70个商品。最后对列表中的每个元素应用get方法,获取我们要想的字段。对于如下一般结构:
华为 三星……
- 如果要获得href,target和class等属性字段的值,可以用get方法。如each_link.get('href'),each_link.get('target')和each_link.get('class')分别以字符串的形式返回href,target和class的值。
- 如果要获得< a >和< /a >之间的文本,可用get_text方法即each_link.get_text(),返回字符串“华为 三星……”。
这里我们想要href的值,即链接,故应用get方法,存放到列表link_list中。查看一下link_list中的元素,如图3。

我们成功了获取了每个商品的链接,接下来就要依次访问这些链接来爬取商品信息。
3.爬取商品详细信息
1.爬取单个商品信息
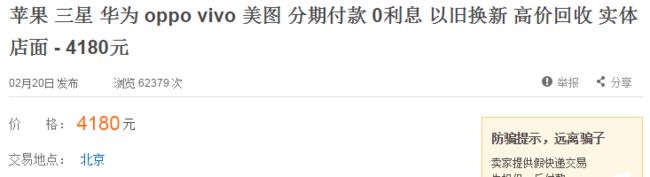
以第1个商品为例,我们要爬取的内容为标题、发布日期、价格和地点,见图4。
和上面的过程一样,对标题右击,检查,得到标题的定位(见图5)。然后重复同样的过程,得到其他信息的定位。

爬取这些信息:
url = 'http://bj.ganji.com/shouji/29130462136655x.htm'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
title = soup.select('h1.title-name')[0].get_text()
price = soup.select('i.f22.fc-orange.f-type')[0].get_text()
date = soup.select('i.pr-5')[0].get_text()
areas = soup.select('ul.det-infor > li > a')
area = ''
for i in areas:
area += i.get_text()+'-'
area = area[:-1]
data = {
'标题':title,
'日期':date.strip().split('\xa0')[0],
'价格':price,
'地点':area
}
在上面的代码中,我们访问第1个商品的链接,解析网页,爬取了我们想要的4个信息,然后把这些信息放到一个字典里,这样每个商品的信息都可以用一个字典来表示。
注意到,在前3个select方法中,我们只写了1个字段;在第4个select方法中,我们只写了3个字段。这是因为,在这个网页中,只写这几个字段就足以唯一定位出我们想要的信息的位置,无需写完整。(读者可自行验证)当然,你想写全了也无妨。
打印上面代码中的data:
{'标题': '苹果7 7P 分期付款可回收手机以旧换新 - 4200元', '价格': '4200', '地点': ' 北京-海淀'}
这样,单个商品的信息就存放在了一个字典中。
2.爬取所有商品详细信息
好了,现在你已经会爬取单个商品了,那爬取所有商品也不在话下了。在上面的代码中加个循环就能爬取所有商品信息了:
#爬取列表中的每个链接对应的商品信息
for each_link in link_list:
wb_data = requests.get(each_link)
soup = BeautifulSoup(wb_data.text,'lxml')
#筛选标题、价格、日期、位置
title = soup.select('h1.title-name')[0].get_text()
price = soup.select('i.f22.fc-orange.f-type')[0].get_text()
date = soup.select('i.pr-5')[0].get_text()
areas = soup.select('ul.det-infor > li > a')
area = ''
for i in areas:
area += i.get_text()+'-'
area = area[:-1]
data = {
'标题':title,
'日期':date.strip().split('\xa0')[0],
'价格':price,
'地点':area
}
print (data)
对于代码中细节的处理,读者可自行尝试。
输出如下(只显示前6条商品信息):
{'标题': '‘五动全城’ 分期付款零首付 全新二手手机 多种购机方式!!! - 3950元', '日期': '04月26日', '价格': '3950', '地点': ' 北京-海淀'}
{'标题': '北京实体店买手机《就分期》分期付款最低0首付 - 4488元', '日期': '03月25日', '价格': '4488', '地点': ' 北京'}
{'标题': '苹果iphoe7 7plus 0利息三星手机分期付款 审核快 通过率高【平价二手】【以旧换新】 - 4188元', '日期': '02月16日', '价格': '4188', '地点': ' 北京'}
{'标题': '苹果7 7P 分期付款可回收手机以旧换新 - 4200元', '日期': '04月25日', '价格': '4200', '地点': ' 北京-海淀'}
{'标题': '有用分期 0首付起( 全系列手机) 当场拿机 优惠288礼包 - 4599元', '日期': '03月07日', '价格': '4599', '地点': ' 北京-朝阳'}
{'标题': '《有分期》大型手机专卖店手机分期支持0首付 - 4288元', '日期': '04月26日', '价格': '4288', '地点': ' 北京-朝阳'}
至此为止,我们基本掌握了理想条件下爬取网页的操作。但以上我们只是爬取了二手手机交易页面这一页的所有商品,注意到下面其实还有很多页,如图6。

下面我们就来爬取赶集网上所有二手手机的信息。
3.爬取赶集网所有二手手机信息
往下面翻页,会发现不同页的网址是遵循一定规律的。第1页到第3页的网址如下:
http://bj.ganji.com/shouji/a2/
http://bj.ganji.com/shouji/a2o2/
http://bj.ganji.com/shouji/a2o3/
第1页的网址也可以写成
http://bj.ganji.com/shouji/a2o1/
也就是说,第N页的网址就是
http://bj.ganji.com/shouji/a2oN/
根据这个规律,我们就能通过编程来爬取所有商品了。只需要把爬取商品链接的代码稍作修改即可:
url_base = 'http://bj.ganji.com/shouji/a2o'
N = 2 #要爬取的页数
link_list = []
for i in range(N):
url = url_base + str(i+1)
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
links = soup.select('a.ft-tit')
for each_link in links:
link_list.append(each_link.get('href'))
4.最后的话
一般来说,网站都有反爬虫技术,在如此短的时间内爬取那么多信息,网站会认为你是爬虫。关于“反反爬虫”也有很多方法,最简单也是最笨的一个办法就是延时,即每爬取几条信息就延时几秒,让自己的爬虫看起来是一个正常上网的人。可用python自带的time模块来完成,读者可自行尝试。
像赶集网、58同城、豆瓣还是比较好爬的,数据比较规整。读者可以去一些小网站试试,可能需要你对数据作更多细节上的处理。
好了,现在你已经学会爬虫的基本操作了,可以去其他网站爬取一些感兴趣的东西下载下来,比如说煎蛋网