想做AI工程师?这个案例必须掌握!(附完整代码Keras实现CNN)
有人说,2018年人工智能已经进入了全球爆发的时刻。个性化信息推送、人脸识别、语音操控等人工智能技术,已“入侵”日常生活的细枝末节。
十多年前,所有的企业都在想办法互联网化,如今,所有的互联网企业都在试图AI化,据数据统计,平均每 10.9 个小时会诞生一家 AI 企业。在这样的背景下,不难想象,未来机器学习技术将会是技术人的新门槛和领域。
那么问题来了,作为一名技术者,我该如何转型/学习 AI 技术?别着急,本文将带你入门AI第一课:《手把手教你Keras实现CNN》,让你实现手写数字识别准确率达到99.6%!(附完整代码)。
![]()
在我们安装过Tensorflow后,安装Keras默认将TF作为后端,Keras实现卷积网络的代码十分简洁,而且keras中的callback类提供对模型训练过程中变量的检测方法,能够根据检测变量的情况及时的调整模型的学习效率和一些参数. 下面的例子,MNIST数据作为测试:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as pimg
import seaborn as sb # 一个构建在matplotlib上的绘画模块,支持numpy,pandas等数据结构
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix # 混淆矩阵
import itertools
# keras
from keras.utils import to_categorical #数字标签转化成one-hot编码
from keras.models import Sequential
from keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPool2D
from keras.optimizers import RMSprop
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ReduceLROnPlateauUsing TensorFlow backend.# 设置绘画风格
sb.set(style='white', context='notebook', palette='deep')# 加载数据
train_data = pd.read_csv('data/train.csv')
test_data = pd.read_csv('data/test.csv')
#train_x = train_data.drop(labels=['label'],axis=1) # 去掉标签列
train_x = train_data.iloc[:,1:]
train_y = train_data.iloc[:,0]
del train_data # 释放一下内存# 观察一下训练数据的分布情况
g = sb.countplot(train_y)
train_y.value_counts()1 4684
7 4401
3 4351
9 4188
2 4177
6 4137
0 4132
4 4072
8 4063
5 3795
Name: label, dtype: int64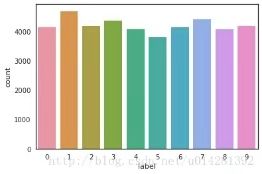
train_x.isnull().describe() # 检查是否存在确实值train_x.isnull().any().describe()count 784
unique 1
top False
freq 784
dtype: objecttest_data.isnull().any().describe()count 784
unique 1
top False
freq 784
dtype: object# 归一化
train_x = train_x/255.0
test_x = test_data/255.0del test_data转换数据的shape
# reshape trian_x, test_x
#train_x = train_x.values.reshape(-1, 28, 28, 1)
#test_x = test_x.values.reshape(-1, 28, 28, 1)
train_x = train_x.as_matrix().reshape(-1, 28, 28, 1)
test_x = test_x.as_matrix().reshape(-1, 28, 28, 1)# 吧标签列转化为one-hot 编码格式
train_y = to_categorical(train_y, num_classes = 10)#从训练数据中分出十分之一的数据作为验证数据
random_seed = 3
train_x , val_x , train_y, val_y = train_test_split(train_x, train_y, test_size=0.1, random_state=random_seed)一个训练样本
plt.imshow(train_x[0][:,:,0])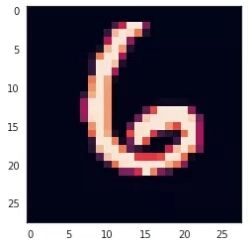
![]()
使用Keras搭建CNN
model = Sequential()
# 第一个卷积层,32个卷积核,大小5x5,卷积模式SAME,激活函数relu,输入张量的大小
model.add(Conv2D(filters= 32, kernel_size=(5,5), padding='Same', activation='relu',input_shape=(28,28,1)))
model.add(Conv2D(filters= 32, kernel_size=(5,5), padding='Same', activation='relu'))
# 池化层,池化核大小2x2
model.add(MaxPool2D(pool_size=(2,2)))
# 随机丢弃四分之一的网络连接,防止过拟合
model.add(Dropout(0.25))
model.add(Conv2D(filters= 64, kernel_size=(3,3), padding='Same', activation='relu'))
model.add(Conv2D(filters= 64, kernel_size=(3,3), padding='Same', activation='relu'))
model.add(MaxPool2D(pool_size=(2,2), strides=(2,2)))
model.add(Dropout(0.25))
# 全连接层,展开操作,
model.add(Flatten())
# 添加隐藏层神经元的数量和激活函数
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.25))
# 输出层
model.add(Dense(10, activation='softmax')) # 设置优化器
# lr :学习效率, decay :lr的衰减值
optimizer = RMSprop(lr = 0.001, decay=0.0)# 编译模型
# loss:损失函数,metrics:对应性能评估函数
model.compile(optimizer=optimizer, loss = 'categorical_crossentropy',metrics=['accuracy'])创建一个callback类的实例
# keras的callback类提供了可以跟踪目标值,和动态调整学习效率
# moitor : 要监测的量,这里是验证准确率
# matience: 当经过3轮的迭代,监测的目标量,仍没有变化,就会调整学习效率
# verbose : 信息展示模式,去0或1
# factor : 每次减少学习率的因子,学习率将以lr = lr*factor的形式被减少
# mode:‘auto’,‘min’,‘max’之一,在min模式下,如果检测值触发学习率减少。在max模式下,当检测值不再上升则触发学习率减少。
# epsilon:阈值,用来确定是否进入检测值的“平原区”
# cooldown:学习率减少后,会经过cooldown个epoch才重新进行正常操作
# min_lr:学习率的下限
learning_rate_reduction = ReduceLROnPlateau(monitor = 'val_acc', patience = 3,
verbose = 1, factor=0.5, min_lr = 0.00001)epochs = 40
batch_size = 100数据增强处理
# 数据增强处理,提升模型的泛化能力,也可以有效的避免模型的过拟合
# rotation_range : 旋转的角度
# zoom_range : 随机缩放图像
# width_shift_range : 水平移动占图像宽度的比例
# height_shift_range
# horizontal_filp : 水平反转
# vertical_filp : 纵轴方向上反转
data_augment = ImageDataGenerator(rotation_range= 10,zoom_range= 0.1,
width_shift_range = 0.1,height_shift_range = 0.1,
horizontal_flip = False, vertical_flip = False)训练模型
history = model.fit_generator(data_augment.flow(train_x, train_y, batch_size=batch_size),
epochs= epochs, validation_data = (val_x,val_y),
verbose =2, steps_per_epoch=train_x.shape[0]//batch_size,
callbacks=[learning_rate_reduction])Epoch 1/40
359s - loss: 0.4529 - acc: 0.8498 - val_loss: 0.0658 - val_acc: 0.9793
Epoch 2/40
375s - loss: 0.1188 - acc: 0.9637 - val_loss: 0.0456 - val_acc: 0.9848
Epoch 3/40
374s - loss: 0.0880 - acc: 0.9734 - val_loss: 0.0502 - val_acc: 0.9845
Epoch 4/40
375s - loss: 0.0750 - acc: 0.9767 - val_loss: 0.0318 - val_acc: 0.9902
Epoch 5/40
374s - loss: 0.0680 - acc: 0.9800 - val_loss: 0.0379 - val_acc: 0.9888
Epoch 6/40
369s - loss: 0.0584 - acc: 0.9823 - val_loss: 0.0267 - val_acc: 0.9910
Epoch 7/40
381s - loss: 0.0556 - acc: 0.9832 - val_loss: 0.0505 - val_acc: 0.9824
Epoch 8/40
381s - loss: 0.0531 - acc: 0.9842 - val_loss: 0.0236 - val_acc: 0.9912
Epoch 9/40
376s - loss: 0.0534 - acc: 0.9839 - val_loss: 0.0310 - val_acc: 0.9910
Epoch 10/40
379s - loss: 0.0537 - acc: 0.9848 - val_loss: 0.0274 - val_acc: 0.9917
Epoch 11/40
375s - loss: 0.0501 - acc: 0.9856 - val_loss: 0.0254 - val_acc: 0.9931
Epoch 12/40
382s - loss: 0.0492 - acc: 0.9860 - val_loss: 0.0212 - val_acc: 0.9924
Epoch 13/40
380s - loss: 0.0482 - acc: 0.9864 - val_loss: 0.0259 - val_acc: 0.9919
Epoch 14/40
373s - loss: 0.0488 - acc: 0.9858 - val_loss: 0.0305 - val_acc: 0.9905
Epoch 15/40
Epoch 00014: reducing learning rate to 0.000500000023749.
370s - loss: 0.0493 - acc: 0.9853 - val_loss: 0.0259 - val_acc: 0.9919
Epoch 16/40
367s - loss: 0.0382 - acc: 0.9888 - val_loss: 0.0176 - val_acc: 0.9936
Epoch 17/40
376s - loss: 0.0376 - acc: 0.9891 - val_loss: 0.0187 - val_acc: 0.9945
Epoch 18/40
376s - loss: 0.0410 - acc: 0.9885 - val_loss: 0.0220 - val_acc: 0.9926
Epoch 19/40
371s - loss: 0.0385 - acc: 0.9886 - val_loss: 0.0194 - val_acc: 0.9933
Epoch 20/40
372s - loss: 0.0345 - acc: 0.9894 - val_loss: 0.0186 - val_acc: 0.9938
Epoch 21/40
Epoch 00020: reducing learning rate to 0.000250000011874.
375s - loss: 0.0395 - acc: 0.9888 - val_loss: 0.0233 - val_acc: 0.9945
Epoch 22/40
369s - loss: 0.0313 - acc: 0.9907 - val_loss: 0.0141 - val_acc: 0.9955
Epoch 23/40
376s - loss: 0.0308 - acc: 0.9910 - val_loss: 0.0187 - val_acc: 0.9945
Epoch 24/40
374s - loss: 0.0331 - acc: 0.9908 - val_loss: 0.0170 - val_acc: 0.9940
Epoch 25/40
372s - loss: 0.0325 - acc: 0.9904 - val_loss: 0.0166 - val_acc: 0.9948
Epoch 26/40
Epoch 00025: reducing learning rate to 0.000125000005937.
373s - loss: 0.0319 - acc: 0.9904 - val_loss: 0.0167 - val_acc: 0.9943
Epoch 27/40
372s - loss: 0.0285 - acc: 0.9915 - val_loss: 0.0138 - val_acc: 0.9950
Epoch 28/40
375s - loss: 0.0280 - acc: 0.9913 - val_loss: 0.0150 - val_acc: 0.9950
Epoch 29/40
Epoch 00028: reducing learning rate to 6.25000029686e-05.
377s - loss: 0.0281 - acc: 0.9924 - val_loss: 0.0158 - val_acc: 0.9948
Epoch 30/40
374s - loss: 0.0265 - acc: 0.9920 - val_loss: 0.0134 - val_acc: 0.9952
Epoch 31/40
378s - loss: 0.0270 - acc: 0.9922 - val_loss: 0.0128 - val_acc: 0.9957
Epoch 32/40
372s - loss: 0.0237 - acc: 0.9930 - val_loss: 0.0133 - val_acc: 0.9957
Epoch 33/40
375s - loss: 0.0237 - acc: 0.9931 - val_loss: 0.0138 - val_acc: 0.9955
Epoch 34/40
371s - loss: 0.0276 - acc: 0.9920 - val_loss: 0.0135 - val_acc: 0.9962
Epoch 35/40
373s - loss: 0.0259 - acc: 0.9920 - val_loss: 0.0136 - val_acc: 0.9952
Epoch 36/40
369s - loss: 0.0249 - acc: 0.9924 - val_loss: 0.0126 - val_acc: 0.9952
Epoch 37/40
370s - loss: 0.0257 - acc: 0.9923 - val_loss: 0.0130 - val_acc: 0.9960
Epoch 38/40
Epoch 00037: reducing learning rate to 3.12500014843e-05.
374s - loss: 0.0252 - acc: 0.9926 - val_loss: 0.0136 - val_acc: 0.9950
Epoch 39/40
372s - loss: 0.0246 - acc: 0.9927 - val_loss: 0.0134 - val_acc: 0.9957
Epoch 40/40
371s - loss: 0.0247 - acc: 0.9929 - val_loss: 0.0139 - val_acc: 0.9950在训练过程当中,有几次触发学习效率衰减的条件,每当val_acc连续3轮没有增长,就会把学习效率调整为当前的一半,调整之后,val_acc都有明显的增长,但是在最后几轮,模型可能已经收敛.
# learning curves
fig,ax = plt.subplots(2,1,figsize=(10,10))
ax[0].plot(history.history['loss'], color='r', label='Training Loss')
ax[0].plot(history.history['val_loss'], color='g', label='Validation Loss')
ax[0].legend(loc='best',shadow=True)
ax[0].grid(True)
ax[1].plot(history.history['acc'], color='r', label='Training Accuracy')
ax[1].plot(history.history['val_acc'], color='g', label='Validation Accuracy')
ax[1].legend(loc='best',shadow=True)
ax[1].grid(True)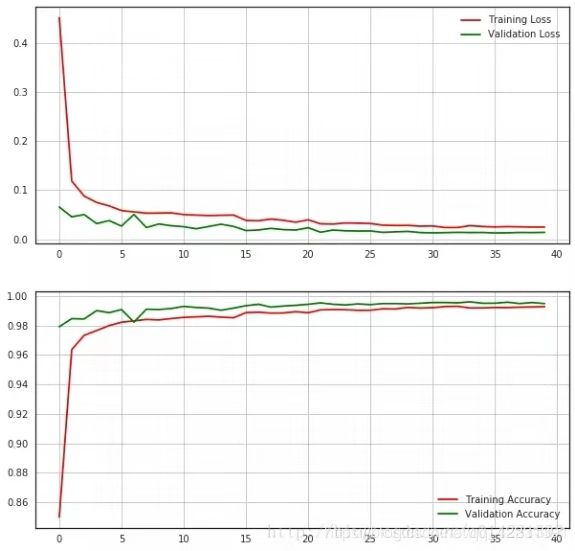
# 混淆矩阵
def plot_sonfusion_matrix(cm, classes, normalize=False, title='Confusion matrix',cmap=plt.cm.Blues):
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype('float')/cm.sum(axis=1)[:,np.newaxis]
thresh = cm.max()/2.0
for i,j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j,i,cm[i,j], horizontalalignment='center',color='white' if cm[i,j] > thresh else 'black')
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predict label')验证数据的混淆举证
pred_y = model.predict(val_x)
pred_label = np.argmax(pred_y, axis=1)
true_label = np.argmax(val_y, axis=1)
confusion_mat = confusion_matrix(true_label, pred_label)
plot_sonfusion_matrix(confusion_mat, classes = range(10))
以上就是本文的案例,如果大家对本篇文章技术点一知半解,不能透彻理解,您可能需要从机器学习的基础学起。
如果您决定踏入AI这个“坑”,在这里我推荐 CSDN 学院出品的《人工智能工程师》实训营,目标是通过 120 天的实战,将学员培养达到具备一年项目经验的人工智能工程师水平。CSDN 百天计划课程共分为 3 个阶段,4 个月完成。
3分钟了解AI人工智能课程:https://www.v5kf.com/public/chat/chat?sid=148176&entry=5&ref=link&accountid=242d003016152
联系 CSDN 学院职场规划师,获取一对一专属服务,包括:IT 职场规划服务/专属折扣

阅读原文,获取更多资讯信息