利用机器学习方法检测识别TLS加密恶意流量
摘要:本文总结提出了一种主流的机器学习加密流量分析的方法
如何在不侵犯个人隐私的前提下,在加密流量中检测恶意攻击行为,为了找到一种切实可行的“在加密流量中检测恶意攻击行为”的方法,Infosec团队借鉴了Cisco公司高级安全研究小组(Cisco Advanced Security Research)的一个研究项目:基于NetFlows的恶意行为检测技术。研究人员用了两年的时间找到了问题的解决方法。通过分析大量的TLS数据流、恶意样本以及捕获的数据包,研究人员发现TLS数据流中的元数据(明文)包含了无法隐藏或者加密的指纹信息。TLS数据流可被用于模糊明文数据,但同时必须生成一组“可观测的复杂参数”,后者可用于训练数据模型(通过机器学习)。当一个TLS数据流开始后,会先执行一次握手。客户端(如Chrome浏览器)会向服务端(如FACEBOOK网站)发送一个ClientHello的消息,该消息包括一组参数(包括加密算法、版本等信息)。像ClientHello的这种TLS元数据主要在加密数据传输前进行交互,没有被加密。这样,数据模型就可以通过分析元数据来检测恶意攻击行为,而不需要对加密数据进行解密操作。最新的测试结果表明,ETA测试模型不仅不需解密数据,同时也具有较高的准确率。当只分析Netflow的特征时,ETA检测恶意行为的准确率为67%,当加入SPL(Service Packet Length)、DNS、TLS元数据、HTTP等多种特征时,准确率跃会升至99%。
加密一直都是保护用户通讯隐私的重要特性,可如果恶意程序在传播过程中也加密的话,对这样的流量做拦截感觉就麻烦了很多。谈到加密,TLS(Transport Layer Security Protocol,传输层安全协议)就是当前使用非常广泛的协议:国外部分研究机构的数据显示,已有至多60%的网络流量采用TLS,当然也包括一些恶意程序(虽然大约只有10%)。
2015年,Cisco的infosec 团队面临一个亟待解决的问题:如何在不侵犯个人隐私的前提下,在加密流量中检测恶意攻击行为,以确保公司员工的信息安全。但在当时可行的方法只有一个:先解密相关的加密流量(如SSL和TLS),再检测恶意攻击行为。
中间人攻击(MITM:Man-In-The-Middle)是他们需要检测防御的主要对象,但在检测的同时也对个人隐私造成了损害(因为需要将个人计算机与银行、邮件服务器之间的加密流量解密)。此外,这种检测的代价也非常高,如需要管理用于检测后重复签名的SSL证书、降低网络服务的用户体验等。
针对该问题,Infosec团队决定寻找一个不影响公司正常网络业务的新检测方法。
一个复杂但未解决的问题
Cisco在本周宣布将推出一组新的网络产品和应用软件:基于意图的新一代网络解决方案[2]。研究小组开发的数据模型为称为加密流量分析(ETA:Encrypted Traffic Analytics),其标志着Cisco正往自己的目标迈出坚实有力的一步:利用整合了自动化和机器学习的海量网络数据技术,将安全技术部署在网络的各个地方。
加密技术通常被看成一个好的事物,保护了互联网通信和会话的隐私,防御了中间人攻击对数据的窃取和篡改。随着云服务应用的逐渐开展、以及一些公司(如Google和Mozilla)对TLS的强力推广,公司企业需要应对处理更多的加密流量。
所有的加密流量需要使用由可信的证书颁发机构(CA:Certificate Authority)颁发的证书签名。逐渐增多的CA也使TLS加密流量的处理变得方便快捷。但是,加密流量的增多使得攻击流量也能够完美的隐藏在正常流量中(之前在未加密的流量中进行攻击的话,攻击者需要将自己的攻击流量加密以规避检测),CSO的一篇文章[1]指出:“不断降低的加密成本同样也使攻击者受益”。
攻击者通常将自己的通信、控制、数据窃取等操作的数据伪装成正常的TLS或者SSL流量。而检测隐藏在正常流量中的恶意攻击行为是一个涉及大量的数据集的复杂任务。在研发人员看来,基于Netflow的检测技术虽然提供了很多有价值的信息,但也有其局限性。例如,利用Netflow能够获取两个设备之间的传输了多少字节等详细信息,但并不能描绘出整个通信过程。
研究人员相信能够找到一种让安全和隐私合理共存的解决方案。为次,他们从零开始构建项目,工作包括大量的代码编写和密集的数据建模。该项目得到了思科技术投资资金(Cisco’s Technology Investment Fund)的支持,通常该类项目的周期长达数年。
有了资金的担保,在项目开始前还需要获取和分析来自思科网络的大量数据和各种恶意代码的样本数据。一方面,研究人员引入了机器学习的理念,藉此开发了一些分析工具,虽然还没有应用到恶意行为检测分析上,这些工具已经能够成功地识别了一些使用Netflow数据的特定应用程序,如识别数据是来自用户的Chrome浏览器还是Windows更新服务。另一方面,项目组和思科的所有产品团队通力合作,包括公司内部的信息安全团队,塔洛斯的威胁情报组和最近收购了ThreatGRID团队。
在花费了数月开发了超过10000行代码后,项目组开始为数据模型进行实际测试,在数以百万计的数据包和已知恶意代码的样本中找出“最具描述性的特征”,最终达到能够在加密流量中检测恶意攻击行为的目的。在项目组看来,“搜集合适的数据”是最重要的工作环节,当其它人拿着数据不知如何利用时,项目组已经拿着数据的需求清单在思科的各个部门大肆搜刮。
寻找恶意攻击行为的指纹信息
从2009年起,网络攻击者就开始通过伪装、窃取、甚至是合法的证书来欺骗互联网的认证系统。TLS证书由合法的证书颁发机构(CA)颁发,其用途是让用户放心其访问的网站是合法的。 但证书的安全保证并非完全可靠,攻击者会利用其让受害者交出登录凭证或下载恶意软件载荷。
在过去的几个月里,使用合法TLS证书的攻击事件逐渐增多,部分原因是合法证书的获取越发简单快捷(如可通过Let’sEncrypt免费获取),网络钓鱼的攻击者利用合法的免费证书生成大量的伪装网站(如PayPal或比特币钱包供应商),如下图所示。

另一方面,相对简单的密钥获取方式也成为了安全防护的一把双刃剑。
安全部门成为了自己决策的受害者,比如为了提高信息安全,要求研发、供应和销售部门使用加密信道,但这又为如何在这些加密数据中检测恶意攻击行为提出了新的挑战。
通过分析大量的TLS数据流、恶意样本以及捕获的数据包,研究人员发现TLS数据流中的元数据(明文)包含了无法隐藏或者加密的指纹信息。TLS数据流可被用于模糊明文数据,但同时必须生成一组“可观测的复杂参数”,后者可用于训练数据模型(通过机器学习)。
当一个TLS数据流开始后,会先执行一次握手。客户端(如Chrome浏览器)会向服务端(如FACEBOOK网站)发送一个ClientHello的消息,该消息包括一组参数(包括加密算法、版本等信息)。像ClientHello的这种TLS元数据主要在加密数据传输前进行交互,没有被加密。这样,数据模型就可以通过分析元数据来检测恶意攻击行为,而不需要对加密数据进行解密操作(见下图)。

最新的测试结果表明,ETA测试模型不仅不需解密数据,同时也具有较高的准确率。当只分析Netflow的特征时,ETA检测恶意行为的准确率为67%,当加入SPL(Service Packet Length)、DNS、TLS元数据、HTTP等多种特征时,准确率跃会升至99%。
资源的合理分配、部门间的有效合作等多种原因使得该项目能够在短短两年内取得飞跃式的成果,也为网络安全领域的一个复杂问题提交了一个解决方案,这种成果也仅能在类似于思科这种同时拥有资源和数据来源的公司中才会出现。研发人员希望ETA通过代码升级更新的方式,在网络中进行广泛部署。利用ETA的测试模型,能够提高网络的整体安全性。
下面分析一下这种方法原理:

TLS协议
思科大约分析了18个恶意程序家族的数千个样本,并在企业网络中数百万加密数据流中,分析数万次恶意连接。整个过程中,网络设备的确不对用户数据做处理,仅是采用DPI(深度包检测技术)来识别clientHello和serverHello握手信息,还有识别连接的TLS版本。
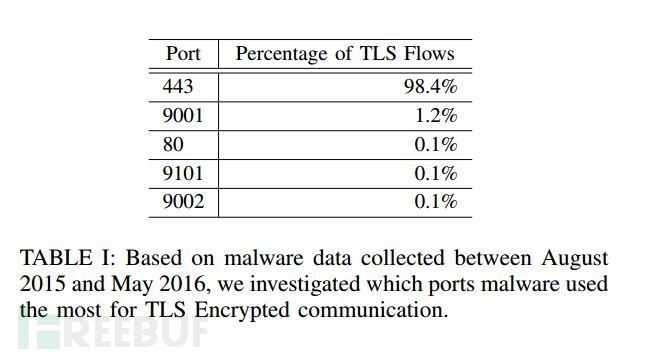
“在这篇报告中,我们主要针对433端口的TLS加密数据流,尽可能公正地对比企业一般的TLS流量和恶意TLS流量。为了要确认数据流是否为TLS,我们需要用到DPI,以及基于TLS版本的定制signature,还有clientHello和serverHello的信息类型。”
“最终,我们在203个端口之上发现了229364个TLS流,其中443端口是目前恶意TLS流量使用最普遍的端口。尽管恶意程序端口使用情况多种多样,但这样的情况并不多见。”
不仅如此,据说他们还能就这些恶意流量,基于流量特性将之分类到不同的恶意程序家族中。“我们最后还要展示,在仅有这些网络数据的情况下,进行恶意程序家族归类。每个恶意程序家族都有其独特的标签,那么这个问题也就转化为不同类别的分类问题。”
“即便使用相同TLS参数,我们依然就够辨认和比较准确地进行分类,因为其流量模式相较其他流量的特性,还是存在区别的。我们甚至还能识别恶意程序更为细致的家族分类,当然仅通过网络数据就看不出来了。”
实际上,研究人员自己写了一款软件工具,从实时流量或者是抓取到的数据包文件中,将所有的数据输出为比较方便的JSON格式,提取出前面所说的数据特性。包括流量元数据(进出的字节,进出的包,网络端口号,持续时间)、包长度与到达间隔时间顺序(Sequence of Packet Lengths and Times)、字节分布(byte distribution)、TLS头信息。
其实我们谈了这么多,还是很抽象,整个过程还是有些小复杂的。有兴趣的同学可以点击这里下载思科提供的完整报告。
分析结果准确性还不错
思科自己认为,分析结果还是比较理想的,而且整个过程中还融合了其机器学习机制(他们自己称为机器学习classifiers,应该就是指对企业正常TLS流量与恶意流量进行分类的机制,甚至对恶意程序家族做分类),正好做这一机制的测试。据说,针对恶意程序家族归类,其准确性达到了90.3%。
“在针对单独、加密流量的识别中,我们在恶意程序家族归类的问题上,能够达到90.3%的准确率。在5分钟窗口全部加密流量分析中,我们的准确率为93.2%(make use of all encrypted flows within a 5-minute window)。”
参考文献
[1]https://www.anquanke.com/post/id/86342
[2]论文记录:Identifying Encrypted Malware Traffic with Contextual Flow Data
[3] 来自FreeBuf黑客与极客(FreeBuf.COM)
https://www.cnblogs.com/bonelee/p/10194509.html
http://www.csoonline.com/article/3121327/security/performance-management-and-privacy-issues-stymie-ssl-inspections-and-the-bad-guys-know-it.html
http://news.ifeng.com/a/20170621/51292838_0.shtml
https://arxiv.org/pdf/1607.01639.pdf
https://github.com/cisco/joy