Maven+Mybatis的基本使用
Maven:
是一个项目管理工具,负责管理项目开发过程中的几乎所有东西,主要用于项目构建,依赖管理,项目信息管理,Maven为开发者提供了一套完整的构建生命周期框架,开发团队几乎不用花多少时间就能够自动完成工程的基础构建配置,因为Maven使用了一个标准的目录结构和一个默认的构建生命周期,在有多个开发团队环境的情况下,Maven能够在很短的时间内使得每项工作都按照标准进行,因为大部分的工程配置操作都非常简单并且可复用,在创建报告、检查、构建和测试自动配置时,Maven可以让开发者的工作变得更加简单
maven项目目录结构: IDEA中 maven 的项目目录

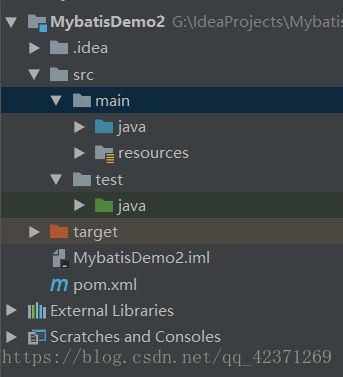
Mybatis:
MyBatis 是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集 对JDBC进行封装,使得操作数据库变得简单。MyBatis 可以对配置和原生Map使用简单的 XML 或注解,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录
使用maven构建一个mybatis项目(IDEA):
1) 选择 maven 创建一个新项目
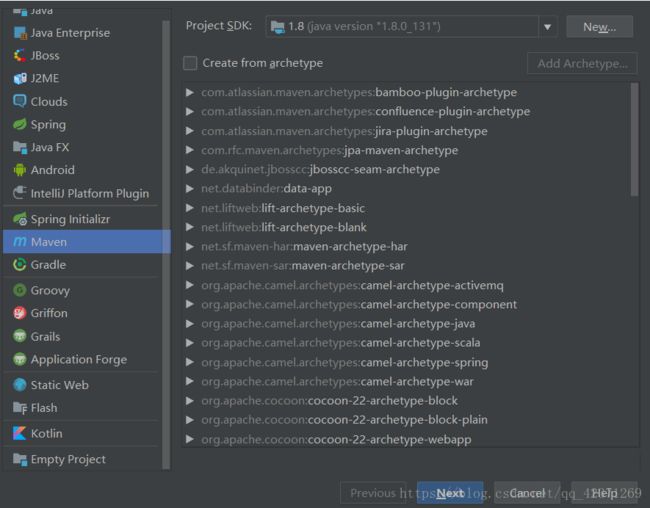
2)填写 GroupId , ArtifactId,Version
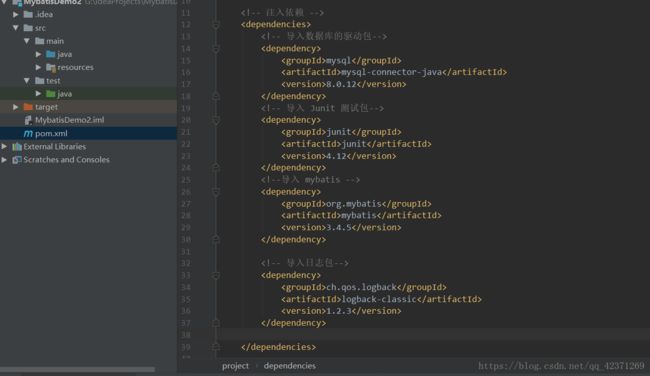
3) 配置 pom.xml,注入依赖项(导入所需的 jar 包)
4)在 resources 包下编写配置文件 mybatis-config.xml , 主要是连接数据库的配置,和
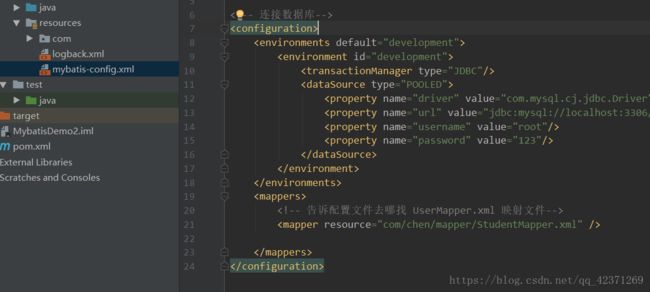
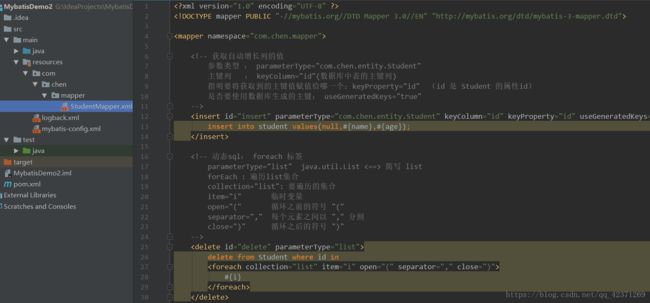
5) 编写映射文件,主要是一些操作数据库的语句(增,删,改,查)
一般以 '' 类名Mapper.xml '' 命名存放在 resources 包下
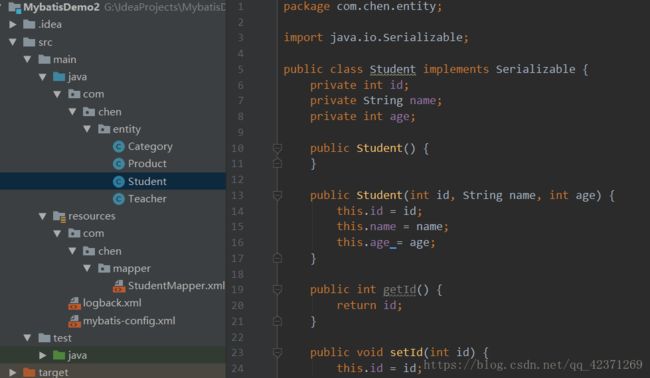
6)编写实体类:在 java 包下进行编写
7)在 test 包下编写测试代码,检查是否都配置正确
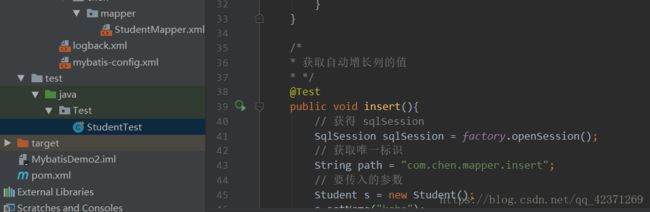
8) 测试代码都正确运行,则基本的配置就成功了
使用Mybatis 对数据库进行 ‘’增 删 改 查” 操作:
1) 在映射文件( xxxMapper.xml )里编写
namespace="包名.XXMapper"> // 防止命名冲突 // id: 唯一标识 parameterType:参数类型 resultType: 返回值类型
<insert id="insert" parameterType="实体类型"> 插入sql语句, #{实体属性值}
<update id="update" parameterType="实体类型"> 更新sql, #{实体属性值}
<delete id="delete" parameterType="基本类型"> 删除sql, #{任意字符串}
<select id="查询单个" parameterType="查询条件类型" resultType="实体类型"> 查询sql
<select id="查询多个" parameterType="查询条件类型" resultType="实体类型"> 查询sql
2)测试代码中:
// 获取配置文件的输入流 FileInputStream is = new FileInputStream(“配置文件的路径”);
// 获得 SqlSessionFactory 工厂类的对象 SqlSessionFactory factory = new SqlSessionFactoryBuilder(is);
// 利用获得的工厂类对象,获取 SqlSession 对象 SqlSession sqlSession = factory.openSession();
// 使用 SqlSession 对象执行 映射文件的 SQL语句 namespace.id 唯一标识
sqlSession.insert("namespace.id", 参数对象);
sqlSession.update("namespace.id", 参数对象);
sqlSession.delete("namespace.id", 参数对象);// 获得执行SQL语句后的结果
实体类型 obj = sqlSession.selectOne("namespace.id", 参数对象); // 查询单个结果
List<实体类型> obj = sqlSession.selectList("namespace.id", 参数对象); // 查询多个结果// 提交事务
sqlSession.commit();// 关闭资源
sqlSession.close();
对数据库进行一些比较复杂的操作:
1)获取自动增长列的值:
映射文件:
insert into student values(null,#{name},#{age});
测试代码:
/*
* 获取自动增长列的值
* */
@Test
public void insert(){
// 获得 sqlSession
SqlSession sqlSession = factory.openSession();
// 获取唯一标识
String path = "com.chen.mapper.insert";
// 要传入的参数
Student s = new Student();
s.setName("kobe");
s.setAge(18);
System.out.println(s);
// 执行sql语句
sqlSession.insert(path,s);
// 手动提交事务
sqlSession.commit();
System.out.println(s);
// 关闭sqlSession
sqlSession.close();
}
2)动态拼接 SQL:
映射文件:
delete from Student where id in
#{i}
测试代码:
/*
* 动态sql : 拼接sql forEach标签
* */
@Test
public void delete(){
SqlSession sqlSession = factory.openSession();
List list = new ArrayList();
list.add(1);
list.add(2);
sqlSession.delete("com.chen.mapper.delete",list);
sqlSession.commit();
sqlSession.close();
}
3)动态拼接:
映射文件:
update student
name=#{name},
age=#{age},
id=#{id}
测试代码:
/*
* 动态sql 拼接: if标签 set标签
* */
@Test
public void update(){
SqlSession sqlSession = factory.openSession();
Student s = new Student();
s.setName("curry");
s.setAge(30);
s.setId(3);
sqlSession.update("com.chen.mapper.update",s);
sqlSession.commit();
sqlSession.close();
}
4)多条件查询:
映射文件:
测试代码:
/**
* 动态sql if标签 where标签 多条件查询:模糊查询 & 范围查询
*/
@Test
public void selectByCondition(){
SqlSession sqlSession = factory.openSession();
Map map = new HashMap();
map.put("name","%e%");
map.put("minAge","10");
map.put("maxAge","40");
List list = sqlSession.selectList("com.chen.mapper.selectByCondition", map);
sqlSession.commit();
for (Student student : list) {
System.out.println(student);
}
sqlSession.close();
} 5)分页查询:
物理分页:select * from student limit start,size;
优点:使用sql直接进行分页
缺点:不通用,数据库不同的sql语句不同
逻辑分页:select * from student 先把数据查询出来,再通过JDBC代码实现分页
优点: 通用
缺点: 效率低,值设和于数据很少的情况
映射文件:
测试代码:
/*
* 分页查询
* */
/*物理分页*/
@Test
public void selectPage(){
SqlSession sqlSession = factory.openSession();
Map map = new HashMap();
map.put("start","6");
map.put("size","3");
List list = sqlSession.selectList("com.chen.mapper.selectPage", map);
sqlSession.commit();
for (Student student : list) {
System.out.println(student);
}
sqlSession.close();
}
/*逻辑分页*/
@Test
public void selectByLogical(){
SqlSession sqlSession = factory.openSession();
/*
* 底层通过 JDBC 的代码实现分页
* RowBounds(offset,limit): offset:起始位置, limit:要查询的数量
* */
List list = sqlSession.selectList("com.chen.mapper.selectLogical",null,new RowBounds(0,3));
for (Student student : list) {
System.out.println(student);
}
sqlSession.commit();
sqlSession.close();
} 6)解决数据库中的表与实体类不匹配的情况:
映射文件:
测试代码:
/*
* 解决表与实体类不匹配是的情况,类名不同
* */
/*方法一: 取列别名*/
@Test
public void otherName(){
SqlSession sqlSession = factory.openSession();
Teacher o = sqlSession.selectOne("com.chen.mapper.selectName", 2);
System.out.println(o);
sqlSession.commit();
sqlSession.close();
}
/*方法二: 使用 resultMap 代替 resultType 完成映射 */
@Test
public void selectMap(){
SqlSession sqlSession = factory.openSession();
Teacher t = sqlSession.selectOne("com.chen.mapper.selectMap",2);
System.out.println(t);
sqlSession.commit();
sqlSession.close();
}
6)使用连接查询:
select p.id,p.name,p.price ,c.id cid,c.name cname from product p inner join category c on p.categoryId = c.id where p.id=?
映射文件:
实体类中:
// 普通属性
private int id;
private String name;
private int price;
//关系属性,保存着另一张表
private Category category;
测试代码:
/*
* 连接查询
* */
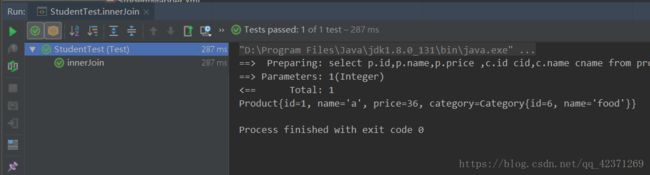
@Test
public void innerJoin(){
SqlSession sqlSession = factory.openSession();
Product p = sqlSession.selectOne("com.chen.mapper.innerJoin", 1);
System.out.println(p);
sqlSession.commit();
sqlSession.close();
}
SqlSession的缓存机制:
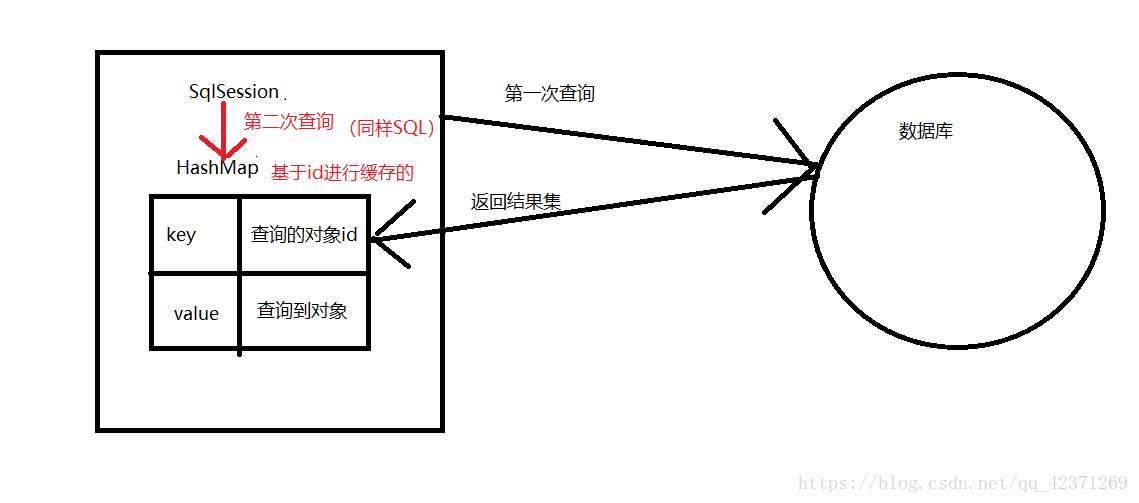
一级缓存: 每个sqlsession都有一个一级缓存,在操作数据库时需要构造SqlSession对象,在SqlSession对象里, 有一个HashMap用于存储缓存数据,不同的SqlSession之间的缓存互相不影响,只要sql语句和参数相同, 只有第一次查询数据库,并且会把查询结果放入一级缓存,之后的查询,就直接从一级缓存中获取结果
作用范围: 只限于同一个sqlsession
作用时效: 当这个SqlSession执行 增 删 改 操作时,这时HashMap中的缓存会被清空,这样是为了保证避免出现脏读;
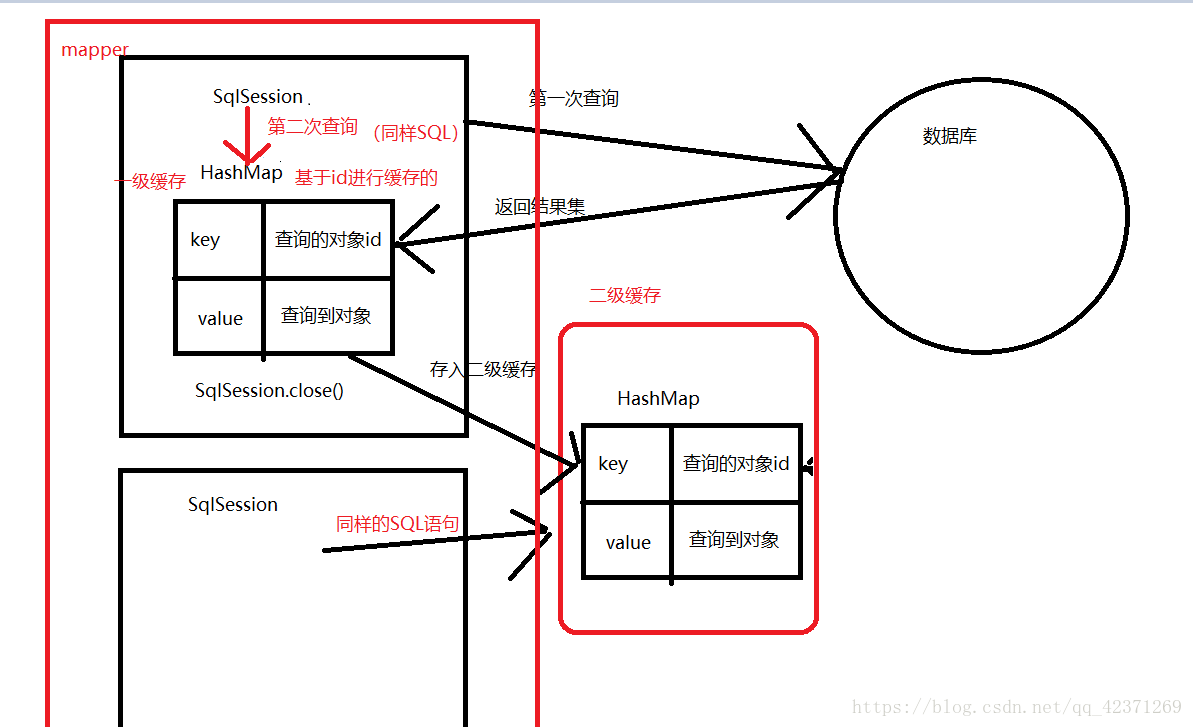
二级缓存: mapper级别的缓存,所有sqlSession都共享的缓存,多个SqlSession使用同一个mapper的SQL语句去操作数据库 得到的数据会存在二级缓存,它同样使用HashMap进行数据存储,相比一级缓存,二级缓存的范围更大, 多个SqlSession可以共享二级缓存,二级缓存是跨SqlSession的
作用范围: mapper的同一个 namespace,当第一个SqlSession调用close()方法时,关闭了一级缓存, 这时数据会缓存到二级缓存中,这时第二个SqlSession查询时,会去二级缓存中查询数据, 不再去数据库中查询,提高查询效率;
作用时效:
只要是执行了增,删,改的操作,缓存就应该失效,仍然从数据库查询得到最新结果
Mybatis默认没有开启二级缓存,需要在映射文件中开启二级缓存
一级缓存无需配置,而二级缓存需要配置
#{} 与 ${} 的区别
1)
#{} :生成的sql语句是用?占位符的方式, 可以防止sql注入攻击
${} :生成的sql语句是直接把值进行了字符串的拼接, 有注入攻击漏洞2):
${} 可以进行运算 #{}不能运算3):
#{} 在sql语句中只能替换值, 不能是表名,列名,关键字
${} 可以替换sql语句的任意部分