中文知识图谱CN-DBpedia构建的关键技术
这篇博客是根据学习查看复旦大学知识工厂实验室的徐波老师报告整合资料后的笔记,报告内容详略得当,结构清晰,干货满满,于是便自己整理并记下来,方便以后深度学习。
什么是知识图谱?
知识图谱本质上是一种语义网络。
主要由节点,边,目标三大块组成。
其中节点包括:实体、概念。边包括:实体与实体、实体与概念、概念与概念。目标包括:描述真实世界中存在的各种实体或概念。
简介中文开放百科知识图谱CN-DBpedia
是目前最大规模的开放百科中文知识图谱之一。
涵盖数千万实体和数亿的关系。
• 百科实体数 16,537,283
• 百科关系数 213,506,696
相关知识服务API累计调用量已达2.6亿次。
CN-DBpedia主要应用场景
语义搜索、智能问答、超级验证码。
CN-DBpedia系统构架
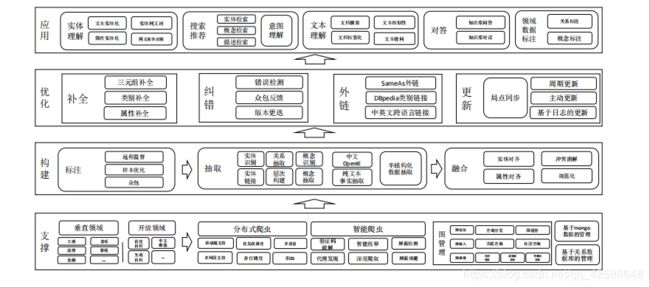
报告中,老师主要介绍了三大模块:抽取模块、归一化模块、填充模块。
抽取模块:
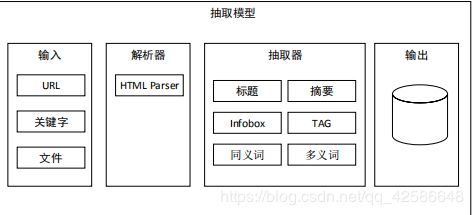
归一化模块:
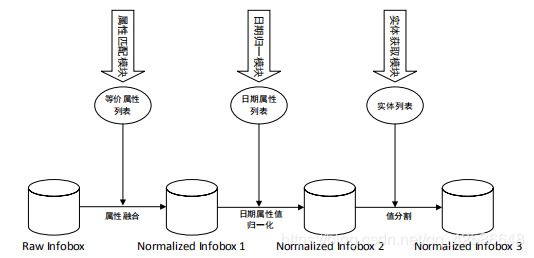
填充模块:
方法一:利用其它知识图谱进行填充。
• e.g. YAGO利用Geonames(一个包含超过1000万地点位置信息的地理知识 图谱)来增加YAGO实体的地理位置信息
方法二:利用百科网站的其他语种进行填充
• e.g. Wikipedia
方法三:利用百科网站实体标签进行填充
• e.g. 如“刘德华”的一个分类信息为“香港演员”,可以从中得出(刘
德华,出生地,香港)和(刘德华,职业,演员)两组Infobox
方法四:利用百科网站实体正文进行填充
• 百科实体正文内容是对实体最全面的介绍,包含的信息最为丰富
利用百科网站实体正文内容进行填充
基本思路
• 为每个属性构建一个抽取器(分类器)
• 每个抽取器分别从百科文本(实体名已知)的句子中抽取出相应属性的值
序列数据标记问题
文本属性值抽取本质上是一个序列数据标记问题 ,将句子当做是一个序列数据,属性值抽取过程即可看作是序列数据标记过程
1表示为属性值,0表示不是属性值 。
这里简单介绍一下传统分类方法:
条件随机场:针对序列数据进行分类的模型 ,每个词组需要人为设定一组特征。
缺点:1、需要专家人为设计特征 。2、不具有通用性。
基于深度学习的方法:
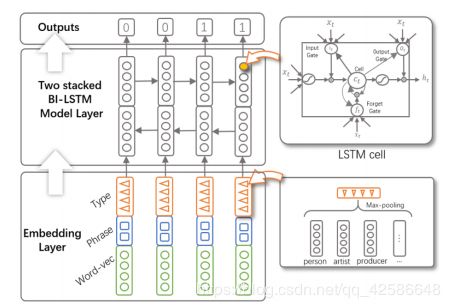
实体分类模块:
知识图谱中的边:
• 实体与实体 (百科网站抽取)
• 概念与概念 (Taxonomy Construction)
• 实体与概念 (实体分类)
Taxonomy构建需要耗费巨大的人工,代价巨大。如何才能获得一个质量优良、又不需要太多人 工的Taxonomy呢?
为此,提出了Taxonomy复用的方法,也就是将现有的、成熟的Taxonomy(如DBpedia、Yago、Freebase等)作为CN-DBpedia的Taxonomy。
基于Taxonomy复用的实体分类
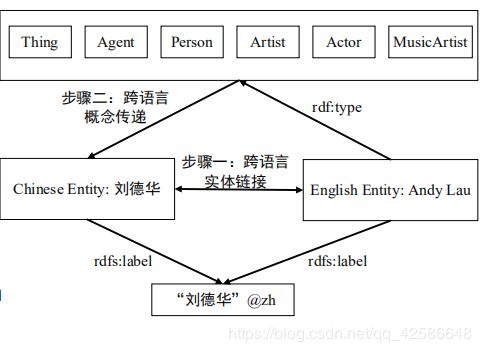
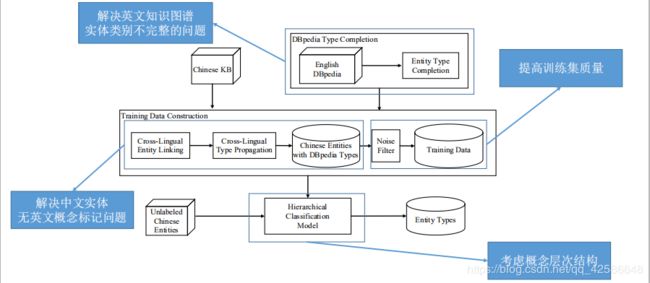
难点1:训练集构建,中文实体无法直接分类到英文 Taxonomy上。
解决方案 :跨语言实体链接 ,跨语言概念传递 。
难点2:训练集存在噪声
• CASE 1:DBpedia 中的实体本身存在分类错误,这将导致对应的中文实体也分类错误
• CASE 2:由于跨语言实体链接错误,导致中文实体分类错误
• CASE 3:由于中文实体语义特征缺失,导致无法推断部分来自其对应英文实体的概念
解决方案
• 对训练集中实体的分类结果进行多分类器投票过滤。
• 将训练集分为N份,其中每N-1份作为训练集,用来过滤另一份的结果。
• 每个分类器分别对实体进行重新预测,与原结果比较,未预测出的结果即视为该分类 器认为的噪声数据。
• 通过过滤策略对结果进行过滤。
跨语言实体分类—系统框架
基于文本的实体分类
难点1:训练集构建
人工标记代价大。
解决方案 :STEP 1:基于远程监督的训练集 构建 。
STEP 2:训练集噪声过滤
多分类器投票过滤方法
难点2:特征选择
人工设计代价大。
解决方案
基于神经网络的实体指称项分类 ,一个句子分为三部分 : Left Context ,Mention ,Right Context.
对句子进行向量化处理 [?−? , … , ?−1] [?1, … , ??] [?1, … , ?? ]
难点3:结果融合
• 简单的合并算法无法取得良好的效果
解决方案
将其看作是一个整数线性规划问题。
• 一个带约束的优化问题,并且模型中 的每个参数都要求为非负数。
模型
• 将所有mention的分类结果累加
约束
• 概念互斥约束
一个实体不能同时属于两个语义互斥 的概念
??? ?1, ?2 = ??? ?(?1,?2)/?(?1)×?(?2)
• 概念层次化约束
• 一个实体如果不属于某个概念,那么 也不能属于这个概念的任意子概念。
如何更新?
传统更新方法
基于更新日志的更新
• Wikipedia有这个功能,但百度百科没有
• 周期性更新
• E.g., 每半年重新爬取一遍数据并进行解析
反馈更新
• 用户点击更新按钮,进行更新
• 基于搜索日志的新词发现
• 用户搜索一个词时,未在知识库中找到, 即认为是一个新词
主动更新方法
基本思路
•监控互联网上的热词
• 热词分为两种情况
• 新词
• 旧词,但信息发生了变化
• 更新热词以及与之相关的词条
为什么将热词作为更新的种子结点?
• 实证分析
实验:统计热词的更新频率和随机选择的 实体的更新频率。
结果 :80%的热词在100天内更新过了 ,10%的随机选择的实体在100天内更新过了。
更新框架
步骤一:从互联网上发现热词作为种子结点
步骤二:更新这些热词(从百科网站中获取新词或更新旧词)
步骤三:从这些更新的热词的页面中的超链接中获取更多的待更 新实体,并为每个待更新实体设置更新优先级。
• 如果是旧词,从知识库中获取
• 如果是新词,从最新的百科页面中获取
• 之所以要设置优先级而不是更新所有扩展实体是由于扩展会得到非常多 的实体,超过每日的更新限制K
步骤四:按照优先级顺序更新扩展实体。
优先级如何设置?
原则
• 如果是一个新词,那么优先级设置为最高。
• 如果是一个旧词,估计其上一次更新结束到当前时间内可能更新的次数, 该次数作为优先级指标E[u(x)]。
• P(x):为实体x预期的更新频率,通过预测器得到。
• ts (x):为最近一次更新的时间。
• 如果x是一个新词,t? ? = −∞
Jiaqing Liang, Sheng Zhang, Yanghua Xiao, How to Keep a Knowledge
Base Synchronized with Its Encyclopedia Source, (IJCAI2017 )
期望更新频率预测器
模型:回归
• 线性回归
• 随机森林回归
更新系统评估
• 我们将这套更新机制布置到CN-DBpedia中。
• 设置K(每日更新实体个数上限)为1000。
• 我们系统在一天中爬取了1000个实体,其中68.7%的实体的信息 发生了变化。