可分离卷积基本介绍

本文为 AI 研习社编译的技术博客,原标题 :
A Basic Introduction to Separable Convolutions
作者 | Chi-Feng Wang
翻译 | 通夜、秃了少年头 编辑 | 王立鱼、Pita
原文链接:
https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
任何看过MobileNet架构的人都会遇到可分离卷积(separable convolutions)这个概念。但什么是“可分离卷积”,它与标准的卷积又有什么区别?可分离卷积主要有两种类型:
-
空间可分离卷积(spatial separable convolutions)
-
深度可分离卷积(depthwise separable convolutions)
空间可分离卷积
从概念上讲,这是两者中较容易的一个,并说明了将一个卷积分成两部分(两个卷积核)的想法,所以我将从这开始。 不幸的是,空间可分离卷积具有一些显着的局限性,这意味着它在深度学习中没有被大量使用。
空间可分卷积之所以如此命名,是因为它主要处理图像和卷积核(kernel)的空间维度:宽度和高度。 (另一个维度,“深度”维度,是每个图像的通道数)。
空间可分离卷积简单地将卷积核划分为两个较小的卷积核。 最常见的情况是将3x3的卷积核划分为3x1和1x3的卷积 核,如下所示:
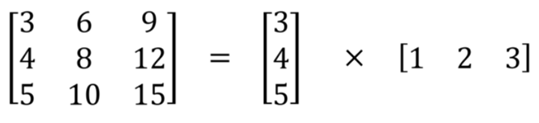
图1:在空间上分离3x3内核
现在,我们不是用9次乘法进行一次卷积,而是进行两次卷积,每次3次乘法(总共6次),以达到相同的效果。 乘法较少,计算复杂性下降,网络运行速度更快。
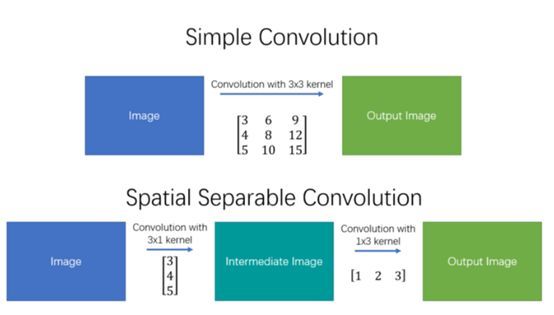
图2:简单且空间可分离的卷积
最著名的可在空间上分离的卷积是用于边缘检测的sobel卷积核:

图3:分离的Sobel卷积核
空间可分卷积的主要问题是并非所有卷积核都可以“分离”成两个较小的卷积核。 这在训练期间变得特别麻烦,因为网络可能采用所有可能的卷积核,它最终只能使用可以分成两个较小卷积核的一小部分。
深度可分离卷积
与空间可分离卷积不同,深度可分离卷积与卷积核无法“分解”成两个较小的内核。 因此,它更常用。 这是在keras.layers.SeparableConv2D或tf.layers.separable_conv2d中看到的可分离卷积的类型。
深度可分离卷积之所以如此命名,是因为它不仅涉及空间维度,还涉及深度维度(信道数量)。 输入图像可以具有3个信道:R、G、B。 在几次卷积之后,图像可以具有多个信道。 你可以将每个信道想象成对该图像特定的解释说明(interpret); 例如,“红色”信道解释每个像素的“红色”,“蓝色”信道解释每个像素的“蓝色”,“绿色”信道解释每个像素的“绿色”。 具有64个通道的图像具有对该图像的64种不同解释。
类似于空间可分离卷积,深度可分离卷积将卷积核分成两个单独的卷积核,这两个卷积核进行两个卷积:深度卷积和逐点卷积。 但首先,让我们看看正常的卷积是如何工作的。
标准的卷积:
如果你不知道卷积如何在一个二维的角度下进行工作,请阅读本文或查看此站点。
然而,典型的图像并不是2D的; 它在具有宽度和高度的同时还具有深度。 让我们假设我们有一个12x12x3像素的输入图像,即一个大小为12x12的RGB图像。
让我们对图像进行5x5卷积,没有填充(padding)且步长为1.如果我们只考虑图像的宽度和高度,卷积过程就像这样:12x12 - (5x5) - > 8x8。 5x5卷积核每25个像素进行标量乘法,每次输出1个数。 我们最终得到一个8x8像素的图像,因为没有填充(12-5 + 1 = 8)。
然而,由于图像有3个通道,我们的卷积核也需要有3个通道。 这就意味着,每次卷积核移动时,我们实际上执行5x5x3 = 75次乘法,而不是进行5x5 = 25次乘法。
和二维中的情况一样,我们每25个像素进行一次标量矩阵乘法,输出1个数字。经过5x5x3的卷积核后,12x12x3的图像将成为8x8x1的图像。
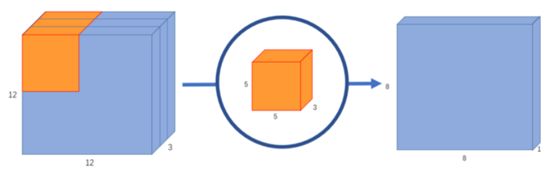
图4:具有8x8x1输出的标准卷积
如果我们想增加输出图像中的信道数量呢?如果我们想要8x8x256的输出呢?
好吧,我们可以创建256个卷积核来创建256个8x8x1图像,然后将它们堆叠在一起便可创建8x8x256的图像输出。

图5:拥有8x8x256输出的标准卷积
这就是标准卷积的工作原理。我喜欢把它想象成一个函数:12x12x3-(5x5x3x256)->12x12x256(其中5x5x3x256表示内核的高度、宽度、输入信道数和输出信道数)。并不是说这不是矩阵乘法;我们不是将整个图像乘以卷积核,而是将卷积核移动到图像的每个部分,并分别乘以图像的一小部分。
深度可分离卷积的过程可以分为两部分:深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。
第1部分-深度卷积:
在第一部分,深度卷积中,我们在不改变深度的情况下对输入图像进行卷积。我们使用3个形状为5x5x1的内核。
视频1:通过一个3通道的图像迭代3个内核:
https://www.youtube.com/watch?v=D_VJoaSew7Q
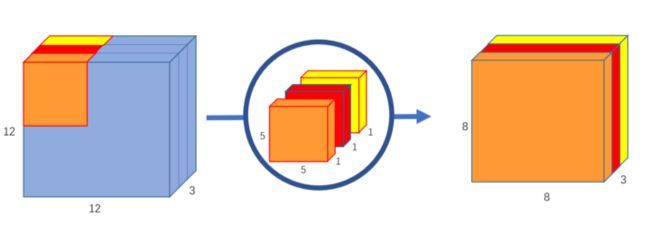
图6:深度卷积,使用3个内核将12x12x3图像转换为8x8x3图像
每个5x5x1内核迭代图像的一个通道(注意:一个通道,不是所有通道),得到每25个像素组的标量积,得到一个8x8x1图像。将这些图像叠加在一起可以创建一个8x8x3的图像。
第2部分-逐点卷积:
记住,原始卷积将12x12x3图像转换为8x8x256图像。目前,深度卷积已经将12x12x3图像转换为8x8x3图像。现在,我们需要增加每个图像的通道数。
逐点卷积之所以如此命名是因为它使用了一个1x1核函数,或者说是一个遍历每个点的核函数。该内核的深度为输入图像有多少通道;在我们的例子中,是3。因此,我们通过8x8x3图像迭代1x1x3内核,得到8x8x1图像。

图7:逐点卷积,将一个3通道的图像转换为一个1通道的图像
我们可以创建256个1x1x3内核,每个内核输出一个8x8x1图像,以得到形状为8x8x256的最终图像。
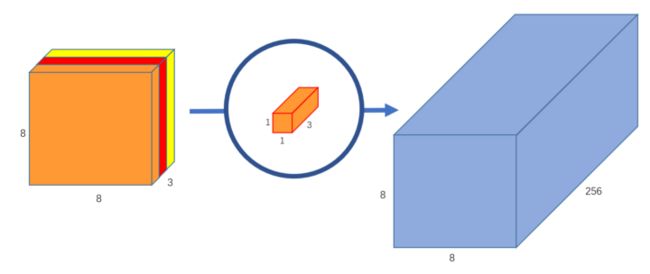
图8:256个核的逐点卷积,输出256个通道的图像
就是这样!我们把卷积分解成两部分:深度卷积和逐点卷积。更抽象地说,如果原始卷积函数是12x12x3 - (5x5x3x256)→12x12x256,我们可以将这个新的卷积表示为12x12x3 - (5x5x1x1) - > (1x1x3x256) - >12x12x256。
好的,但是创建一个深度可分离卷积有什么意义呢?
我们来计算一下计算机在原始卷积中要做的乘法的个数。有256个5x5x3内核可以移动8x8次。这是256 x3x5x5x8x8 = 1228800乘法。
可分离卷积呢?在深度卷积中,我们有3个5x5x1的核它们移动了8x8次。也就是3x5x5x8x8 = 4800乘以。在点态卷积中,我们有256个1x1x3的核它们移动了8x8次。这是256 x1x1x3x8x8 = 49152乘法。把它们加起来,就是53952次乘法。
52,952比1,228,800小很多。计算量越少,网络就能在更短的时间内处理更多的数据。
然而,这是如何实现的呢?我第一次遇到这种解释时,我的直觉并没有真正理解它。这两个卷积不是做同样的事情吗?在这两种情况下,我们都通过一个5x5内核传递图像,将其缩小到一个通道,然后将其扩展到256个通道。为什么一个的速度是另一个的两倍多?
经过一段时间的思考,我意识到主要的区别是:在普通卷积中,我们对图像进行了256次变换。每个变换都要用到5x5x3x8x8=4800次乘法。在可分离卷积中,我们只对图像做一次变换——在深度卷积中。然后,我们将转换后的图像简单地延长到256通道。不需要一遍又一遍地变换图像,我们可以节省计算能力。
值得注意的是,在Keras和Tensorflow中,都有一个称为“深度乘法器”的参数。默认设置为1。通过改变这个参数,我们可以改变深度卷积中输出通道的数量。例如,如果我们将深度乘法器设置为2,每个5x5x1内核将输出8x8x2的图像,使深度卷积的总输出(堆叠)为8x8x6,而不是8x8x3。有些人可能会选择手动设置深度乘法器来增加神经网络中的参数数量,以便更好地学习更多的特征。
深度可分离卷积的缺点是什么?当然!因为它减少了卷积中参数的数量,如果你的网络已经很小,你可能会得到太少的参数,你的网络可能无法在训练中正确学习。然而,如果使用得当,它可以在不显著降低效率的情况下提高效率,这使得它成为一个非常受欢迎的选择。
1x1内核:
最后,由于逐点卷积使用了这个概念,我想讨论一下1x1内核的用法。
一个1x1内核——或者更确切地说,n个1x1xm内核,其中n是输出通道的数量,m是输入通道的数量——可以在可分离卷积之外使用。1x1内核的一个明显目的是增加或减少图像的深度。如果你发现卷积有太多或太少的通道,1x1核可以帮助平衡它。
然而,对我来说,1x1核的主要目的是应用非线性。在神经网络的每一层之后,我们都可以应用一个激活层。无论是ReLU、PReLU、Softmax还是其他,与卷积层不同,激活层是非线性的。直线的线性组合仍然是直线。非线性层扩展了模型的可能性,这也是通常使“深度”网络优于“宽”网络的原因。为了在不显著增加参数和计算量的情况下增加非线性层的数量,我们可以应用一个1x1内核并在它之后添加一个激活层。这有助于给网络增加一层深度。 雷锋网(公众号:雷锋网)雷锋网雷锋网
如果你有任何问题,请在下方留言!别忘了给这个故事点赞!
想要继续查看该篇文章相关链接和参考文献?
点击【可分离卷积基础介绍】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1639
直播预告 | 全网独家 AI 研习社 AIS (ACL, IJCAI, SIGIR) 2019 论文报告会

AlS 2019 是由中国中文信息学会青工委、杭州钱塘新区管委会、搜狗搜索联合举办的论文报告会。 会议将于2019年5月25日一5月26日,在杭州钱塘新区大创小镇国际创博中心内举办。
直播时间:
5 月 25 日 9:00 至 17:30
5 月 26 日 9:00 至 18:00
观看方式:
加入【NLP论文】讨论小组后即可开始观看:
https://ai.yanxishe.com/page/paperGroup/42