从小说网站爬取小说并写入txt文档中
博主这一星期基本都在玩python爬虫,从豆瓣的图书排行到豆瓣的电影排行到链家的房屋信息到去哪儿网的旅游信息爬了个遍:,先贴一段爬取豆瓣图书前200排行的代码给小伙伴们:
#-*- coding:utf-8 -*-
import requests
from lxml import etree
import time
with open(r'D:/douban.txt','w',encoding='utf-8') as F:
for i in range(10):
url = 'https://book.douban.com/top250?start={}'.format(i*25)
data = requests.get(url).text
f = etree.HTML(data)
books = f.xpath('//*[@id="content"]/div/div[1]/div/table')
for div in books:
title = div.xpath('./tr/td[2]/div[1]/a/@title')[0]
score = div.xpath('./tr/td[2]/div[2]/span[2]/text()')[0]
comment = div.xpath('./tr/td[2]/p[2]/span/text()')
num = div.xpath('./tr/td[2]/div[2]/span[3]/text()')[0].strip('(').strip().strip(')')
href = div.xpath('./tr/td[2]/div[1]/a/@href')[0]
time.sleep(1) #加个睡眠,防止IP被封
if len(comment)>0:
print('{}-->{}-->{}-->{}-->{}'.format(title,score,comment[0],num,href))
F.write("{}-->{}-->{}-->{}-->{}\n".format(title,score,comment,num,href))
else:
print('{}-->{}-->{}-->{}'.format(title,score,num,href))
F.write("{}-->{}-->{}-->{}\n".format(title,score,num,href))
F.flush()#保证数据及时从缓存写入本地
print('\n')

但是这些爬虫感觉与自己去搜索查询区别不大,知识更省时而已。但是博主想到每次去网站看小说,旁边各种广告弹窗就很烦,而且翻页还会有各种广告网页跳出,很影响心情,那么我们能不能把小说直接通过爬虫以文本形式保存呢,然后存在手机或者电脑上慢慢看,说干就干,开始我们的小说爬取之路。
首先准备工作就是python的安装和python库的使用,爬取小说我们需要用到的库有:urllib,request,re,bs4(bs4=Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。)。这些库可以在虚拟机环境下安装也可以在windows环境下安装,我是在windows环境下通过cmd直接输入pip install beautifulsoup4/request完成安装,不过百度上说大部分人都会遇到各种问题,只有人品好的人才会直接成功(不好意思我就是人品好的那种,每个都是一次成功。)
我用的开发环境是IDEA,当然你也可以选择使用eclipse,在爬虫方面两者没有什么区别,不过博主更推荐IDEA,毕竟maven项目实在是太好用了。
废话不再多说,下面进入正题:爬取小说。
首先,我们引入我们需要的库文件:
#coding:utf-8 import re import sys from bs4 import BeautifulSoup import urllib.request import time
注意点:python想要使用汉字,需要在脚本最前面添加 #coding:utf-8,汉字使用的编码为utf-8,否则会出现错误!**
首先可以进行一下爬虫伪装(有的网站对于反爬虫力度比较大,如果过快的爬取或者固定IP爬取会被封IP,一般租房网站和购票网站的反爬虫力度比较大,但是此次爬取的“乐文小说”对反爬虫基本没有措施):
headers = ('User-Agent', 'Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1')opener = urllib.request.build_opener()
opener.addheaders = {headers}
urllib.request.install_opener(opener)
首先先从爬取第一个章节开始,此次我选择的是“权杖”这个小说(我也没看过~):权杖 第一章
url = "http://www.lewendu8.com/books/0/114/24413.html"
file = urllib.request.urlopen(url)
data = BeautifulSoup(file , from_encoding="utf8")
先通过代码获取本章节名称:
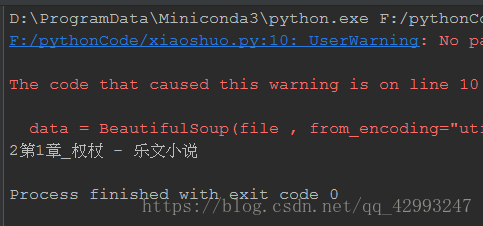
section_name = data.title.string
print(section_name)
爬取结果:
接下来爬取第一章的小说正文,直接贴代码实在太敷衍了,首先我们进入这张小说的页面,通过开发者模式一步步操作(推荐谷歌浏览器,很方便):首先找到正文所在(都在存放在p标签中,具体原因请先了解html):

认真寻找具体划分: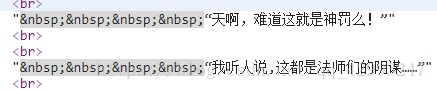
然后将语句写入section_text中:
section_text = data.select('#bgdiv .border_l_r #content p')[0].text
替换章节内容:
section_text=re.sub( '\s+', '\r\n\t', section_text).strip('\r\n')
至此单章爬取完毕,接下来肯定要把整本小说爬取下来了,首先要通过比较每一章节的url来寻找规律:
http://www.lewendu8.com/books/0/114/24413.html 第一章
http://www.lewendu8.com/books/0/114/24415.html 第二章
http://www.lewendu8.com/books/0/114/24418.html 第三章
从上面的url可以看出区别就在于最后的数字不同:
所以可以得出结论,该小说url的构成是:http://www.lewendu8.com/books/21/21335/章节序号.html
然后继续去观察源码:
发现next_page = "6381843.html"便是下一章的章节序号。那么我们只需要使用正则匹配就可以获取到下一章的章节序号了,然后将其写入代码就可以把所有章节给爬取下来了(用一个判断语句即可)。到此一个小说便全部爬取完毕了。
贴上全部代码:
__author__ = 'wanghang'
#coding:utf-8
#author:Ericam_
import re
import sys
from bs4 import BeautifulSoup
import urllib.request
import time
headers = ('User-Agent', 'Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1')
opener = urllib.request.build_opener()
opener.addheaders = {headers}
urllib.request.install_opener(opener)
def get_download(url):
file = urllib.request.urlopen(url)
data = BeautifulSoup(file , from_encoding="utf8")
section_name = data.title.string
section_text = data.select('#bgdiv .border_l_r #content p')[0].text
section_text=re.sub( '\s+', '\r\n\t', section_text).strip('\r\n')
fp = open('quanzhang.txt','a')
fp.write(section_name+"\n")
fp.write(section_text+"\n")
fp.close()
pt_nexturl = 'var next_page = "(.*?)"'
nexturl_num = re.compile(pt_nexturl).findall(str(data))
nexturl_num = nexturl_num[0]
return nexturl_num
if __name__ == '__main__':
url = "http://www.lewendu8.com/books/0/114/24413.html"
num = 228
index = 1
get_download(url)
while(True):
nexturl = get_download(url)
index += 1
sys.stdout.write("已下载:%.3f%%" % float(index/num*100) + '\n')
sys.stdout.flush()
url = "http://www.lewendu8.com/books/0/114/3000868/"+nexturl
if(nexturl == 'http://www.lewendu8.com/books/0/114/3000868/'):
break
print(time.clock())
爬取结果:
