Pandas读取文件(read_csv与read_table 的区别)
pandas
加载文件方式:

注意,read_csv和read_table都是是加载带分隔符的数据,每一个分隔符作为一个数据的标志,但二者读出来的数据格式还是不一样的,read_table是以制表符 \t 作为数据的标志,也就是以行为单位进行存储。
read_csv 与 read_table 的区别
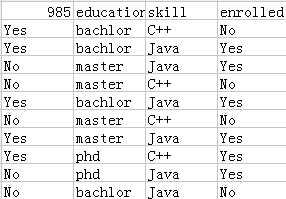
比如读取以上excel中的数据:
- read_table读取
import pandas as pd
import numpy as np
c=pd.read_table('career_data.csv',nrows=5) # 只读了前5行
print c
print ('去掉列名和索引')
print c.values
print '\t'
print ('行列数')
c.values.shape

可以看出,读完后每个字符串之间有逗号相隔,这其实表明每一行作为一个维度进行了存储,所以最后它是一个5行1列的数组,每一行字符串为一列而不是每一个字符串。
- read_csv 读取
import pandas as pd
import numpy as np
c=pd.read_csv('career_data.csv',nrows=5)
print c
print ('去掉列名和索引')
print c.values
print '\t'
print ('行列数')
c.values.shape

而 read_csv读完后是一个5行4列的数组,每一个字符串作为一列,这是二者的区别。还有固定宽度读取的read_ffw 和table 的效果一样。