《编译原理》陈火旺——词法分析程序c语言实现完整版
编译原理——词法分析程序c语言实现完整版
词法分析程序
一、实验目的
根据所学知识设计、编制并调试一个词法分析程序,加深对词法分析概念的理解以及编写代码的锻炼。
二、实验内容
(1)分组完成,每组由3-4位同学组成
(2)确定源语言L和编写程序的语言P
(3)用正规式描述L的词法规则
(4)根据正规式构造给出识别单词的DFA M
(5)根据M,用语言P编写L的词法分析程序
三、实验过程
首先,本实验使用的C++语言编写分析C语言的词法分析程序,基本功能为识别以下几类单词:
标识符
关键字
运算符
界符
常数
注释
1. 文法设计
给出各类单词的词法规则描述(正则文法或正则表达式)
- 1.标识符:(A|B|…|Z|a|b|…|z|)( A|B|…|Z|a|b|…|z|| 0|1|2|…|9)*
- 2.关键字:auto | break | case | char | const | continue | default | do | double | else | enum | extern | float | for | goto | if | int | long | register | return | short | signed | sizeof | static | struct | switch | typedef | unsigned | union | void | volatitle | while
- 3.运算符:+ | - | * | / | % | ++ | += | – | -> | -= | *= | /= | %= | = | == | != | > | < | >= | <= | ! | && | || | & | | | ~
- 4.界符:( | ) | [ | ] | { | } | , | : | ; | " | ’
- 5.常数:(0|1|2|…|9)(0|1|2|…|9)(( . (0|1|2|…|9) (0|1|2|…|9))|ε)
2. 构造DFA

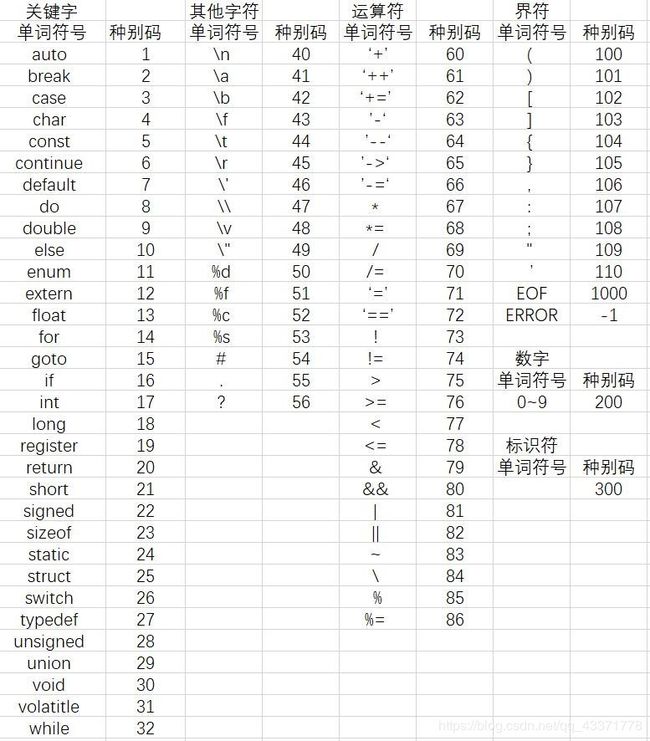
3. 种别编码
词法分析需要输出单词符号对应的属性值,因此构造出如图1-2所示的种别编码表,分别为:
- 关键字:一符一种
- 其他字符:一符一种
- 运算符:一符一种
- 界符:一符一种
- 数字:统一使用200
- 标识符:统一使用300
4.各函数功能说明

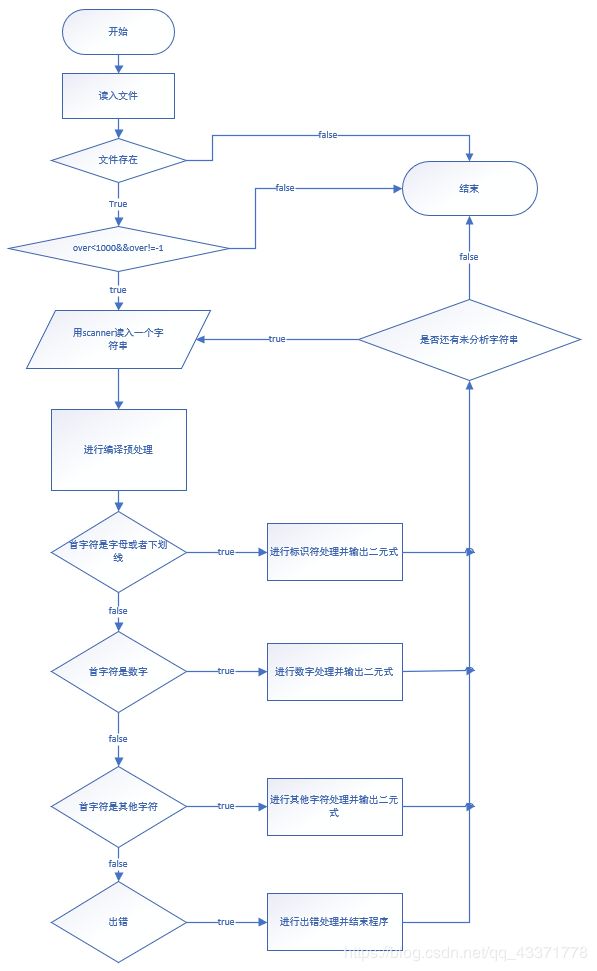
6. 主程序功能流程图
四、测试截图
本次分析为使用了c语言的一个完整的程序输入进入记事本,并用程序进行读文件,文件中的程序截图如图4-1所示。
五、程序源代码(你们最喜欢的!喜欢记得住转发点赞啊)
#include
*/
int main() {
Word* oneword=new Word;
FILE *fp;
int over=1; //如果词法解析出现错误,则结束读取
if( (fp=fopen("input.txt","rt")) == NULL ) {
cout<<"Cannot open file, press any key to exit!"<<endl;
}
while(over<1000&&over!=-1) {
oneword=scanner(fp);
if(oneword->value<1000&&oneword->value>0)
cout<<"<"<<oneword->value<<","<<oneword->token<<">"<<endl;
over=oneword->value;
}
fclose(fp);
system("pause");
return 0;
}
/* 判断是标识符还是关键字*/
int keyOrIdentifier(string token) {
int i=0;
while(KeyWords[i]!=_KEY_WORD_END) {
if(KeyWords[i]==token) {
return i+1;
}
i=i+1;
}
return 300;
}
/*判断标识符是否重复*/
bool isIdExit(string id) {
vector<string>::iterator iter=find(idQueue.begin(),idQueue.end(),id);
if(iter==idQueue.end()) {
return false;
}
return true;
}
/*扫描程序*/
Word* scanner(FILE *fp) {
char ch;
string token="";
Word* ReadWord=new Word;
ReadWord->value=0;
ReadWord->token="";
ch=fgetc(fp);
if(int(ch)==EOF) {
ReadWord->value=1000;
ReadWord->token="ERROR";
}
/* 判断回车 */
if(int(ch)==10) {
line_num++;
return (ReadWord);
}
/* 识别中文并跳过 */
if ((unsigned char)ch > 0x7F) {
return (ReadWord);
}
/* 判断空格 */
else if(isspace(ch)) {
return (ReadWord);
}
/* 标识符及关键字 */
else if(isalpha(ch)||ch=='_') { //如果首字符是字母
while(isalpha(ch)||isdigit(ch)||ch=='_') {
token=token+ch;
ch=fgetc(fp);
}
fseek( fp, -1, SEEK_CUR ); //当获取的字符既不是字母也不是数字,则指针依然指向该字符
if(keyOrIdentifier(token)==300) {
if(!isIdExit(token)) {
ReadWord->value=300;
ReadWord->token=token;
idQueue.push_back(token);
} else {
ReadWord->value=-1;
ReadWord->token="ERROR";
cout<<"第"<<line_num<<"行发生了错误!"<<"标识符:"<<token<<"重复"<<endl;
}
} else {
ReadWord->value=keyOrIdentifier(token); // 判断获取的字符串是关键字还是标识符,获取它对应的类型
ReadWord->token=token;
}
return(ReadWord);
}
/* 数字 */
else if(isdigit(ch)) {
while(isdigit(ch)) {
token=token+ch;
ch=fgetc(fp);
}
fseek( fp, -1, SEEK_CUR );
ReadWord->value=200;
ReadWord->token=token;
return(ReadWord);
} else
switch(ch) {
/*其他字符*/
case '\\':
ch=fgetc(fp);
if (ch=='n') {
ReadWord->value=40;
ReadWord->token="\\n";
return(ReadWord);
}
if (ch=='a') {
ReadWord->value=41;
ReadWord->token="\\a";
return(ReadWord);
}
if (ch=='b') {
ReadWord->value=42;
ReadWord->token="\\b";
return(ReadWord);
}
if (ch=='f') {
ReadWord->value=43;
ReadWord->token="\\f";
return(ReadWord);
}
if (ch=='t') {
ReadWord->value=44;
ReadWord->token="\\t";
return(ReadWord);
}
if (ch=='r') {
ReadWord->value=45;
ReadWord->token="\\r";
return(ReadWord);
}
if (ch=='\'') {
ReadWord->value=46;
ReadWord->token="\\'";
return(ReadWord);
}
if (ch=='\\') {
ReadWord->value=47;
ReadWord->token="\\\\";
return(ReadWord);
}
if (ch=='v') {
ReadWord->value=48;
ReadWord->token="\\v";
return(ReadWord);
}
if (ch=='"') {
ReadWord->value=49;
ReadWord->token="\\\"";
return(ReadWord);
}
fseek( fp, -1, SEEK_CUR );
ReadWord->value=84;
ReadWord->token="\\";
return(ReadWord);
break;
case '%':
ch=fgetc(fp);
if (ch=='d') {
ReadWord->value=50;
ReadWord->token="%d";
return(ReadWord);
}
if (ch=='f') {
ReadWord->value=51;
ReadWord->token="%f";
return(ReadWord);
}
if (ch=='c') {
ReadWord->value=52;
ReadWord->token="%c";
return(ReadWord);
}
if (ch=='s') {
ReadWord->value=53;
ReadWord->token="%s";
return(ReadWord);
}
if (ch=='=') {
ReadWord->value=86;
ReadWord->token="%=";
return(ReadWord);
}
fseek( fp, -1, SEEK_CUR );
ReadWord->value=85;
ReadWord->token="%";
return(ReadWord);
break;
case '#':
ReadWord->value=54;
ReadWord->token="#";
return(ReadWord);
break;
case '.':
ReadWord->value=55;
ReadWord->token=".";
return(ReadWord);
break;
case '?':
ReadWord->value=56;
ReadWord->token="?";
return(ReadWord);
break;
/* 运算符 */
case '+':
ch=fgetc(fp);
if (ch=='+') {
ReadWord->value=61;
ReadWord->token="++";
return(ReadWord);
}
if (ch=='=') {
ReadWord->value=62;
ReadWord->token="+=";
return(ReadWord);
}
fseek( fp, -1, SEEK_CUR );
ReadWord->value=60;
ReadWord->token="+";
return(ReadWord);
break;
case '-':
ch=fgetc(fp);
if (ch=='-') {
ReadWord->value=64;
ReadWord->token="--";
return(ReadWord);
}
if (ch=='>') {
ReadWord->value=65;
ReadWord->token="->";
return(ReadWord);
}
if (ch=='=') {
ReadWord->value=66;
ReadWord->token="-=";
return(ReadWord);
}
fseek( fp, -1, SEEK_CUR );
ReadWord->value=63;
ReadWord->token="-";
return(ReadWord);
break;
case '*':
ch=fgetc(fp);
if (ch=='=') {
ReadWord->value=68;
ReadWord->token="*=";
return(ReadWord);
}
ReadWord->value=67;
ReadWord->token="*";
return(ReadWord);
break;
/* 除号和注释*/
case '/':
ch=fgetc(fp);
if (ch=='/') {
ch=fgetc(fp);
while(ch!=10&&ch!=EOF) { // 发现注释符号,则一直读取,直到遇到回车为止
ch=fgetc(fp);
}
if(int(ch)==10) {
line_num++;
}
return(ReadWord);
} else if(ch=='*') {
ch=fgetc(fp);
while(ch!='/'&&ch!=EOF) {
if(int(ch)==10)
line_num++;
ch=fgetc(fp);
}
return(ReadWord);
} else if (ch=='=') {
ReadWord->value=70;
ReadWord->token="/=";
return(ReadWord);
} else {
fseek( fp, -1, SEEK_CUR );
ReadWord->value=69;
ReadWord->token="/";
return(ReadWord);
}
break;
case '=':
ch=fgetc(fp);
if (ch=='=') {
ReadWord->value=72;
ReadWord->token="==";
return(ReadWord);
}
fseek( fp, -1, SEEK_CUR );
ReadWord->value=71;
ReadWord->token="=";
return(ReadWord);
break;
case '!':
ch=fgetc(fp);
if (ch=='=') {
ReadWord->value=74;
ReadWord->token="!=";
return(ReadWord);
}
fseek( fp, -1, SEEK_CUR );
ReadWord->value=73;
ReadWord->token="!";
return(ReadWord);
break;
case '>':
ch=fgetc(fp);
if (ch=='=') {
ReadWord->value=76;
ReadWord->token=">=";
return(ReadWord);
}
fseek( fp, -1, SEEK_CUR );
ReadWord->value=75;
ReadWord->token=">";
return(ReadWord);
break;
case '<':
ch=fgetc(fp);
if (ch=='=') {
ReadWord->value=78;
ReadWord->token="<=";
return(ReadWord);
}
fseek( fp, -1, SEEK_CUR );
ReadWord->value=77;
ReadWord->token="<";
return(ReadWord);
break;
case '&':
ch=fgetc(fp);
if (ch=='&') {
ReadWord->value=80;
ReadWord->token="&&";
return(ReadWord);
}
fseek( fp, -1, SEEK_CUR );
ReadWord->value=79;
ReadWord->token="&";
return(ReadWord);
break;
case '|':
ch=fgetc(fp);
if (ch=='|') {
ReadWord->value=82;
ReadWord->token="||";
return(ReadWord);
}
fseek( fp, -1, SEEK_CUR );
ReadWord->value=81;
ReadWord->token="|";
return(ReadWord);
break;
case '~':
ReadWord->value=83;
ReadWord->token="~";
return(ReadWord);
break;
/* 界符 */
case '(':
ReadWord->value=100;
ReadWord->token="(";
return(ReadWord);
break;
case ')':
ReadWord->value=101;
ReadWord->token=")";
return(ReadWord);
break;
case '[':
ReadWord->value=102;
ReadWord->token="[";
return(ReadWord);
break;
case ']':
ReadWord->value=103;
ReadWord->token="]";
return(ReadWord);
break;
case '{':
ReadWord->value=104;
ReadWord->token="{";
return(ReadWord);
break;
case '}':
ReadWord->value=105;
ReadWord->token="}";
return(ReadWord);
break;
case ',':
ReadWord->value=106;
ReadWord->token=",";
return(ReadWord);
break;
case ':':
ReadWord->value=107;
ReadWord->token=":";
return(ReadWord);
break;
case ';':
ReadWord->value=108;
ReadWord->token=";";
return(ReadWord);
break;
case '"':
ReadWord->value=109;
ReadWord->token="\"";
return(ReadWord);
break;
case '\'':
ReadWord->value=110;
ReadWord->token="'";
return(ReadWord);
break;
/* 结束符*/
case EOF:
ReadWord->value=1000;
ReadWord->token="OVER";
return(ReadWord);
break;
/* 错误*/
default:
ReadWord->value=-1;
ReadWord->token="ERROR";
cout<<"第"<<line_num<<"行发生了错误!"<<endl;
return(ReadWord);
}
}