python每天定时爬取微博热搜并保存到本地(表格、数据库)
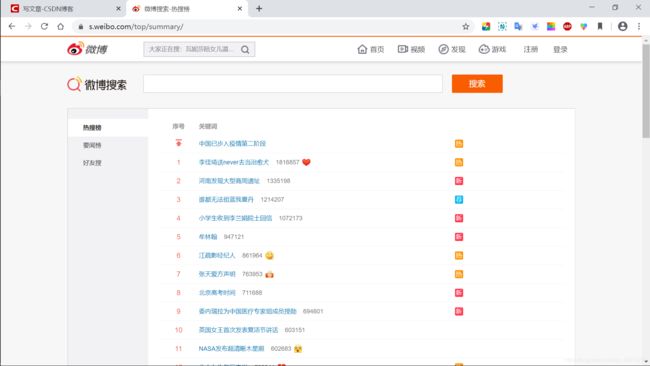
微博热搜网站:https://s.weibo.com/top/summary/
就是这个样子:
pyquery提取:
保险起见headers里加个UA…
from pyquery import PyQuery as pq
html = pq("https://s.weibo.com/top/summary/",
{
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36'
}
)
这里打印html可以看到有结果了
for item in html("#pl_top_realtimehot > table > tbody > tr").items():
if len(list(item.text().split())) >= 3:
print({
'排名': int(item('td.td-01.ranktop').text()),
'名称': item('td.td-02 > a').text(),
'热度': int(item('td.td-02 > span').text())
})
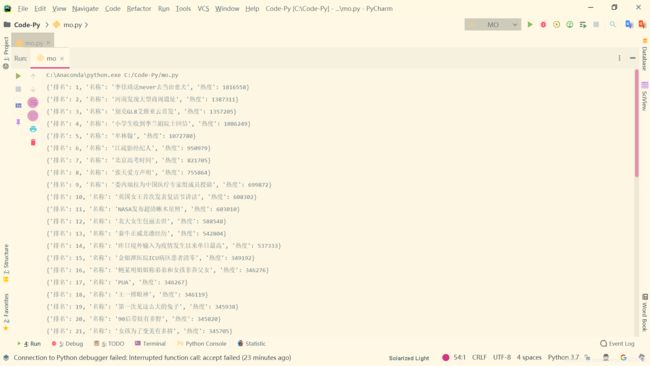
然后用这段代码就可以获得所有结果:
for item in html("#pl_top_realtimehot > table > tbody > tr").items():
if len(list(item.text().split())) >= 3:
with open ("weibo.csv","a",encoding="utf-8") as f:
f.write(item('td.td-01.ranktop').text()+","+item('td.td-02 > a').text()+","+item('td.td-02 > span').text()+"\n")
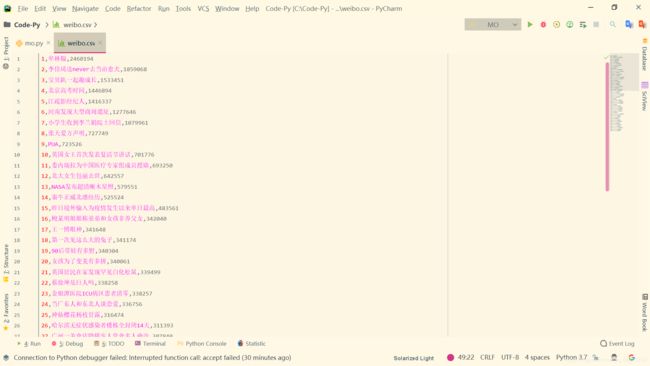
这一段代码就可以把数据存储为csv文件
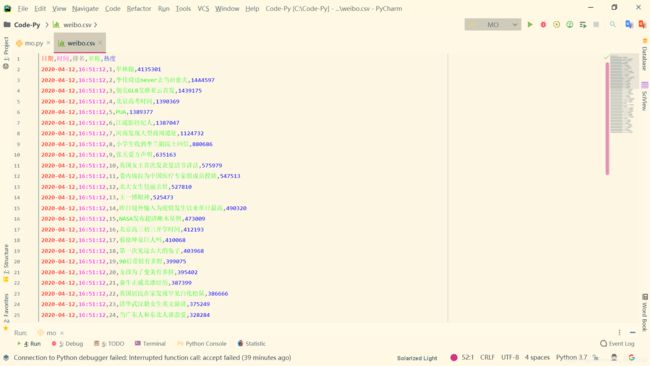
但是因为我们想要每天定时爬取,所以还要再加点东西:
import time
with open ("weibo.csv","a",encoding="utf-8") as f:
f.write("日期,时间,排名,名称,热度\n")
for item in html("#pl_top_realtimehot > table > tbody > tr").items():
if len(list(item.text().split())) >= 3:
with open ("weibo.csv","a",encoding="utf-8") as f:
f.write(time.strftime("%Y-%m-%d")+","+time.strftime("%H:%M:%S")+","+item('td.td-01.ranktop').text()+","+item('td.td-02 > a').text()+","+item('td.td-02 > span').text()+"\n")
这就可以了:
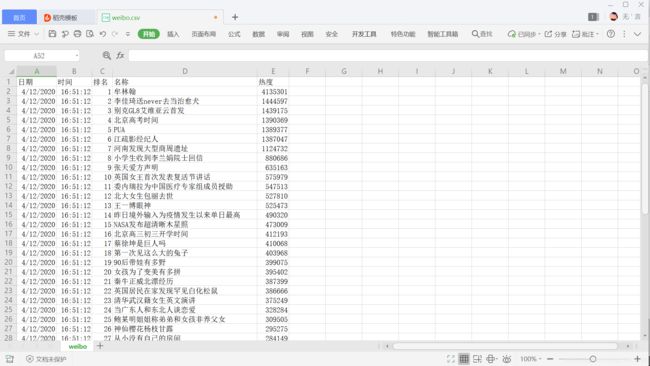
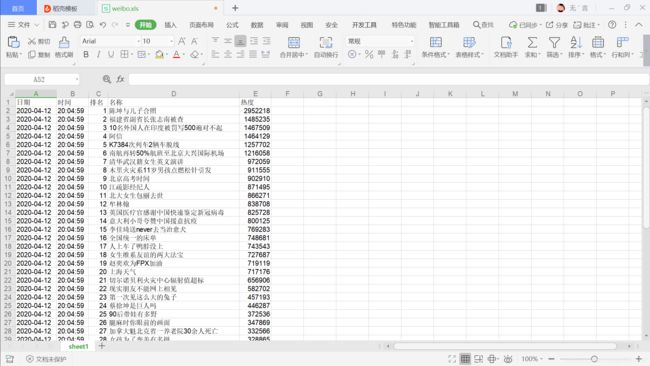
还有保存到excel:
try:
r_xls = open_workbook("weibo.xls")
row = r_xls.sheets()[0].nrows
excel = copy(r_xls)
table = excel.get_sheet("sheet1")
for item in html("#pl_top_realtimehot > table > tbody > tr").items():
if len(list(item.text().split())) >= 3:
contents = [time.strftime("%Y-%m-%d"),
time.strftime("%H:%M:%S"),
int(item('td.td-01.ranktop').text()),
item('td.td-02 > a').text(),
int(item('td.td-02 > span').text())]
for i in range(len(contents)):
table.write(row, i, contents[i])
row += 1
excel.save("weibo.xls")
except FileNotFoundError:
f = xlwt.Workbook()
sheet = f.add_sheet("sheet1")
lists = ['日期', '时间', '排名', '名称', '热度']
for i in range(0, len(lists)):
sheet.write(0, i, lists[i])
row = 1
for item in html("#pl_top_realtimehot > table > tbody > tr").items():
if len(list(item.text().split())) >= 3:
contents = [time.strftime("%Y-%m-%d"),
time.strftime("%H:%M:%S"),
int(item('td.td-01.ranktop').text()),
item('td.td-02 > a').text(),
int(item('td.td-02 > span').text())]
for i in range(len(contents)):
sheet.write(row, i, contents[i])
row += 1
f.save("weibo.xls")
这里的try中的内容是当"weibo.xls"存在时直接写入,except中的内容是当"weibo.xls"不存在时导入数据。
接下来是保存数据到MongoDB数据库:
不会用的可以看这里入门:pymongo操作MongoDB基础教程
import pymongo
client = pymongo.MongoClient(host="localhost", port=27017)
db = client.test
collection = db.weibo
for item in html("#pl_top_realtimehot > table > tbody > tr").items():
if len(list(item.text().split())) >= 3:
collection.insert_one({
'日期':time.strftime("%Y-%m-%d"),
'时间': time.strftime("%H:%M:%S"),
'排名': int(item('td.td-01.ranktop').text()),
'名称': item('td.td-02 > a').text(),
'热度': int(item('td.td-02 > span').text())
})
保存数据到mysql数据库:(4.24新增)
def save_to_mysql(html):
conn = pymysql.connect(
host="localhost",
user="root",
passwd="19834044876lpy",
port=3306,
database="mydb",
charset='utf8',
cursorclass=pymysql.cursors.DictCursor)
conn.cursor().execute("""
create table if not exists weibo (
日期 char(30),
时间 char(30),
排名 char(30),
名称 char(30),
热度 char(30)
);
""")
conn.commit()
for item in html("#pl_top_realtimehot > table > tbody > tr").items():
if len(list(item.text().split())) >= 3:
with conn.cursor() as cursor:
cursor.execute("insert into weibo (日期,时间,排名,名称,热度) values (%s,%s,%s,%s,%s);",
[
time.strftime("%Y-%m-%d"),
time.strftime("%H:%M:%S"),
item('td.td-01.ranktop').text(),
item('td.td-02 > a').text(),
item('td.td-02 > span').text()
])
conn.commit()
cursor.close()
conn.close()
然后我们把它们封装成函数便于操作,主函数里设置整点抓取数据
接下来上源码:
from pyquery import PyQuery as pq
import pymongo
import time
from xlrd import open_workbook
from xlutils.copy import copy
import xlwt
import os
import threading
import pymysql
def get_data():
return pq("https://s.weibo.com/top/summary/",
{
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36'
}
)
def save_to_csv(html):
if os.path.exists("weibo.csv"):
pass
else:
with open("weibo.csv", "a", encoding="utf-8") as f:
f.write("日期,时间,排名,名称,热度\n")
for item in html("#pl_top_realtimehot > table > tbody > tr").items():
if len(list(item.text().split())) >= 3:
with open("weibo.csv", "a", encoding="utf-8") as f:
f.write(time.strftime("%Y-%m-%d") + "," + time.strftime("%H:%M:%S") + "," + item(
'td.td-01.ranktop').text() + "," + item('td.td-02 > a').text() + "," + item(
'td.td-02 > span').text() + "\n")
def save_to_excel(html):
try:
r_xls = open_workbook("weibo.xls")
row = r_xls.sheets()[0].nrows
excel = copy(r_xls)
table = excel.get_sheet("sheet1")
for item in html("#pl_top_realtimehot > table > tbody > tr").items():
if len(list(item.text().split())) >= 3:
contents = [time.strftime("%Y-%m-%d"),
time.strftime("%H:%M:%S"),
int(item('td.td-01.ranktop').text()),
item('td.td-02 > a').text(),
int(item('td.td-02 > span').text())]
for i in range(len(contents)):
table.write(row, i, contents[i])
row += 1
excel.save("weibo.xls") # 保存并覆盖文件
except FileNotFoundError:
f = xlwt.Workbook()
sheet = f.add_sheet("sheet1")
lists = ['日期', '时间', '排名', '名称', '热度']
for i in range(0, len(lists)):
sheet.write(0, i, lists[i])
row = 1
for item in html("#pl_top_realtimehot > table > tbody > tr").items():
if len(list(item.text().split())) >= 3:
contents = [time.strftime("%Y-%m-%d"),
time.strftime("%H:%M:%S"),
int(item('td.td-01.ranktop').text()),
item('td.td-02 > a').text(),
int(item('td.td-02 > span').text())]
for i in range(len(contents)):
sheet.write(row, i, contents[i])
row += 1
f.save("weibo.xls")
def save_to_mongodb(html):
client = pymongo.MongoClient(host="localhost", port=27017)
db = client.test
collection = db['weibo']
for item in html("#pl_top_realtimehot > table > tbody > tr").items():
if len(list(item.text().split())) >= 3:
collection.insert_one({
'日期': time.strftime("%Y-%m-%d"),
'时间': time.strftime("%H:%M:%S"),
'排名': int(item('td.td-01.ranktop').text()),
'名称': item('td.td-02 > a').text(),
'热度': int(item('td.td-02 > span').text())
})
def save_to_mysql(html):
conn = pymysql.connect(
host="localhost",
user="root",
passwd="19834044876lpy",
port=3306,
database="mydb",
charset='utf8',
cursorclass=pymysql.cursors.DictCursor)
conn.cursor().execute("""
create table if not exists weibo (
日期 char(30),
时间 char(30),
排名 char(30),
名称 char(30),
热度 char(30)
);
""")
conn.commit()
for item in html("#pl_top_realtimehot > table > tbody > tr").items():
if len(list(item.text().split())) >= 3:
with conn.cursor() as cursor:
cursor.execute("insert into weibo (日期,时间,排名,名称,热度) values (%s,%s,%s,%s,%s);",
[
time.strftime("%Y-%m-%d"),
time.strftime("%H:%M:%S"),
item('td.td-01.ranktop').text(),
item('td.td-02 > a').text(),
item('td.td-02 > span').text()
])
conn.commit()
cursor.close()
conn.close()
if __name__ == '__main__':
while 1:
if time.strftime("%M%S") == "0000":
t1 = threading.Thread(save_to_csv(get_data()))
t2 = threading.Thread(save_to_excel(get_data()))
t3 = threading.Thread(save_to_mongodb(get_data()))
t4 = threading.Thread(save_to_mysql(get_data()))
t1.start()
t2.start()
t3.start()
t4.start()
这是我挂了一晚上的结果:
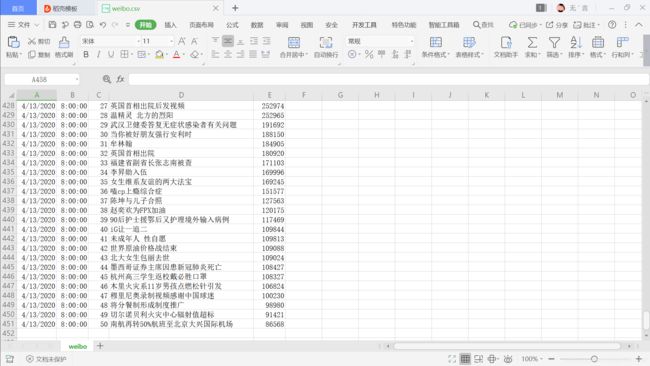
csv:
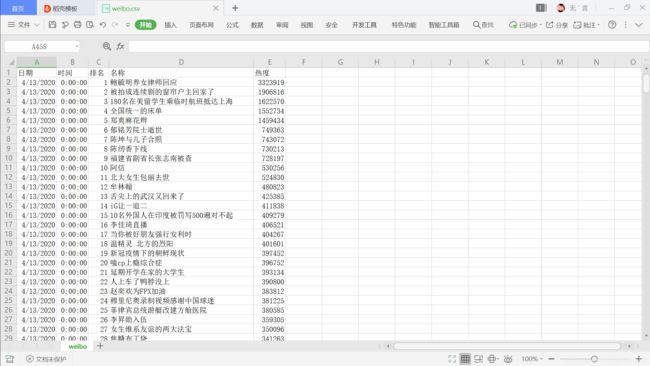
…
…
…
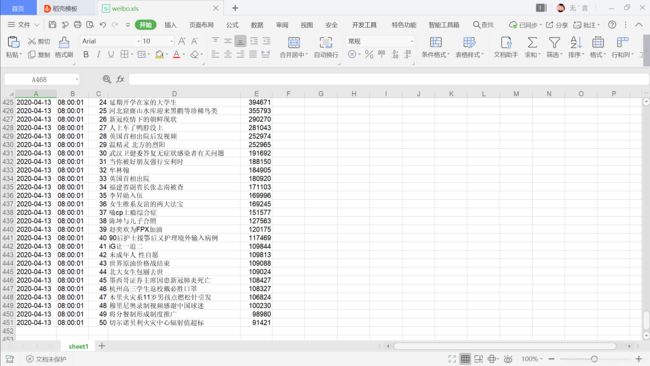
excel:

…
…
…
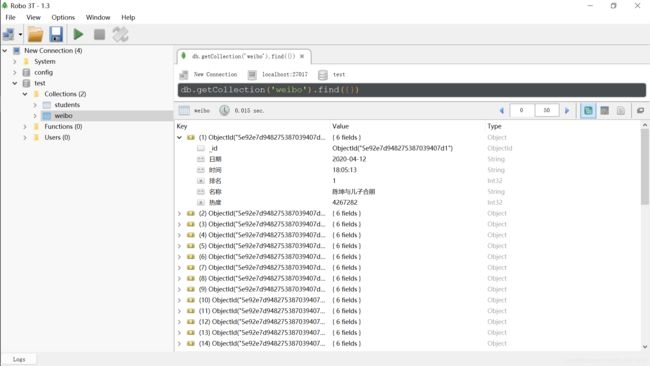
MongoDB:
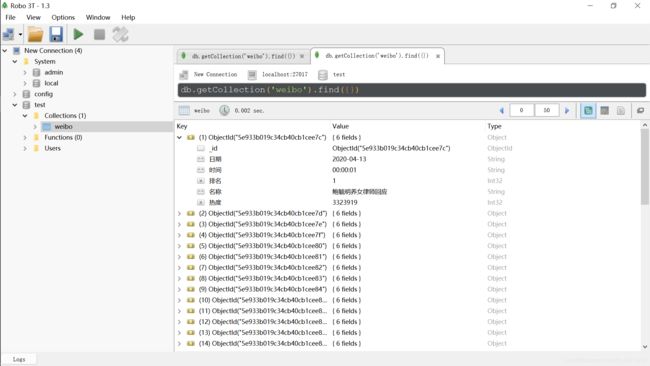
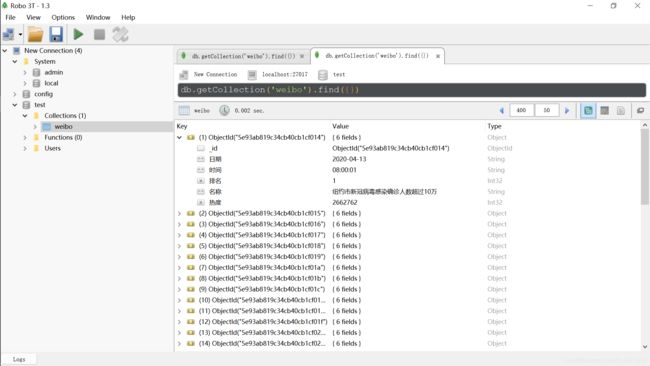
…
…
…
MySQL:
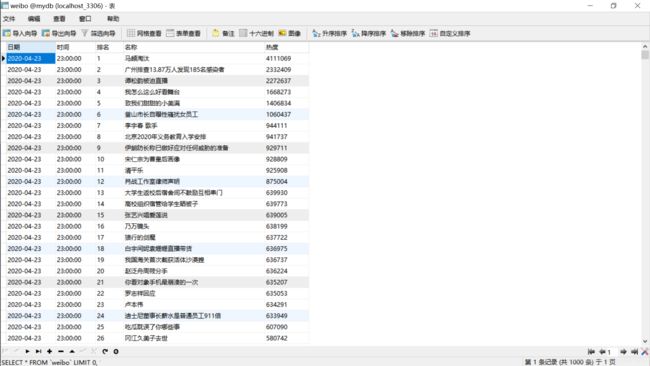
…
…
…
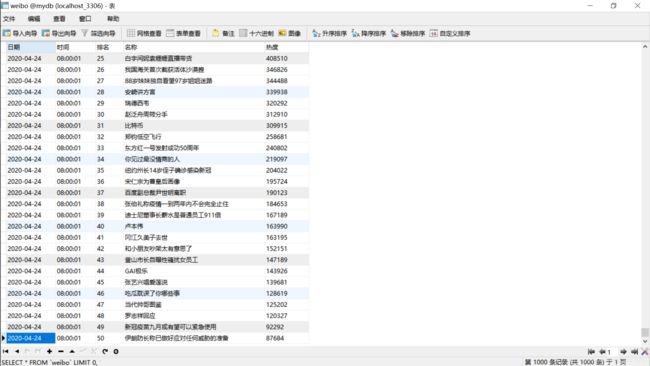
4.24,补充MySQL(因为之前懒得安,现在安上了…)
源码也一同同步
数据抓取下来后想要玩数据分析和可视化的就可以用这个数据集去玩玩什么微博热搜舆情分析啊什么的…
想玩又没基础的同学可以看这里:
数据分析三剑客之 Numpy 基础教程
数据分析三剑客之 Pandas 基础教程
数据分析三剑客之 Matplotlib 基础教程
